一条update语句优化小记

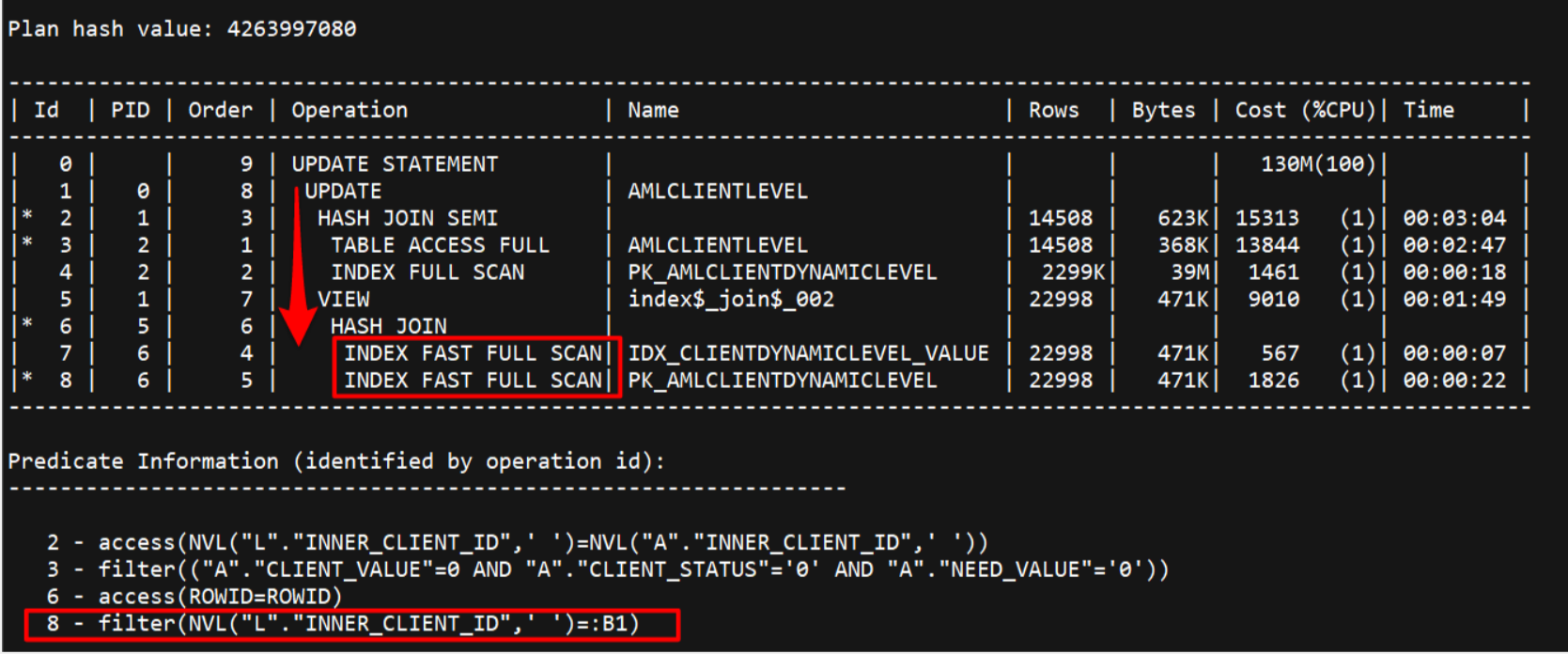




.png)
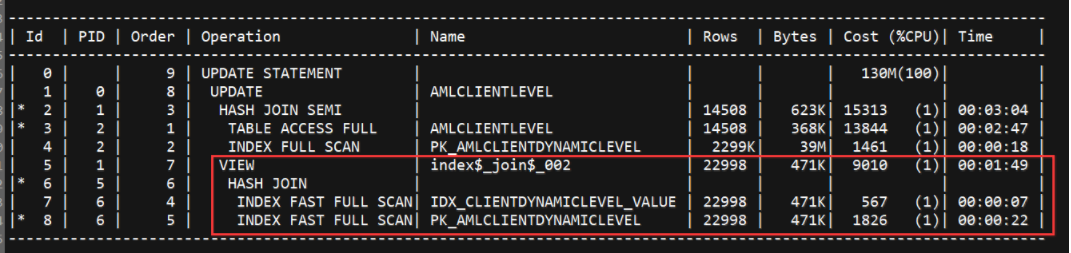
.png)
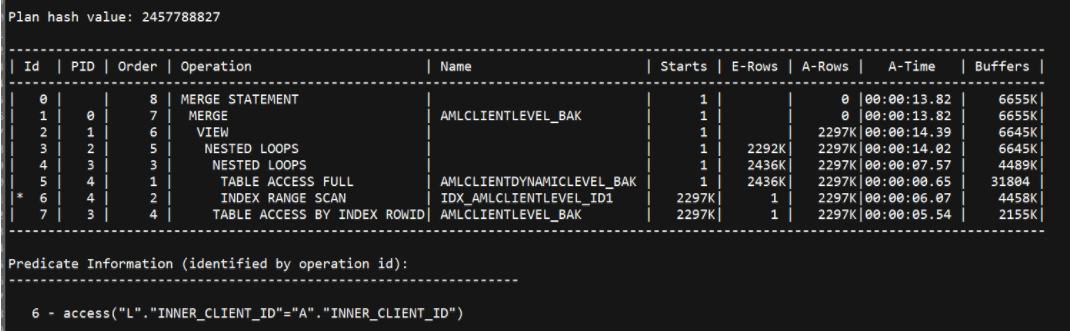
.png)
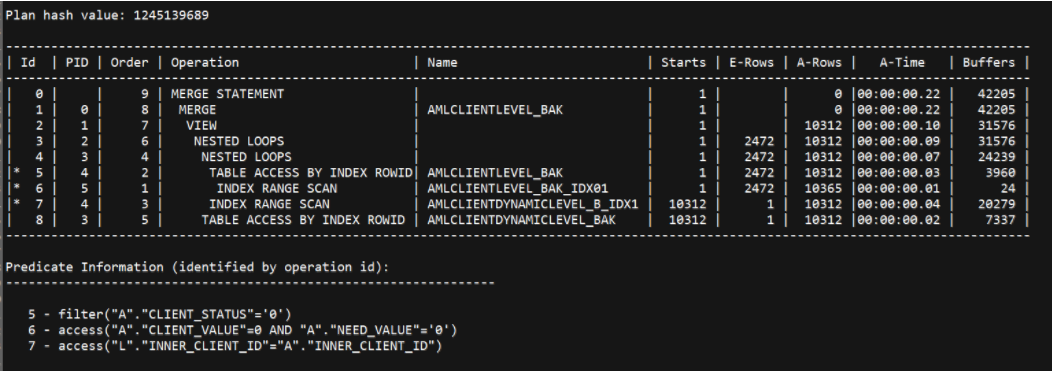
.png)
一条update语句优化小记的更多相关文章
- sql执行万条update语句优化
几个月没有更新笔记了,最近遇到一个坑爹的问题,顺道记录一下.. 需求是这样的:一次性修改上万条数据库. 项目是用MVC+linq的. 本来想着用 直接where() 1 var latentCusto ...
- 完蛋,公司被一条 update 语句干趴了!
大家好,我是小林. 昨晚在群划水的时候,看到有位读者说了这么一件事. 在这里插入图片描述 大概就是,在线上执行一条 update 语句修改数据库数据的时候,where 条件没有带上索引,导致业务直接崩 ...
- 如何将多条update语句合并为一条
需求: 如何将多条update语句合并为一条update语句:如,update table1 set col='2012' where id='2014001' update table1 ...
- 一条update语句到底加了多少锁?带你深入理解底层原理
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子. 手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:"我爱加班". 面试开始,直 ...
- Oracle的update语句优化研究
最近研究sql优化,以下文章转自互联网: 1. 语法 单表:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值 如:update t_join_situation s ...
- MySQL45讲:一条update语句是怎样执行的
首先创建一张表: create table T(ID int primary key,c int); 如果要更新ID=2这行+1:应该这样写 update T set c=c+1 where ID=2 ...
- [转]Oracle的update语句优化研究
原文地址:http://blog.csdn.net/u011721927/article/details/39228001 一. update语句的语法与原理 1. 语法 单表 ...
- Sql Server执行一条Update语句很慢,插入数据失败
今天同事要我修改服务器数据库里面的2条数据,查看服务器上的SQL Server数据库的时候,发现这几天数据没有添加成功,然后发现磁盘很快就满了,执行Update语句时,执行半天都提示还在执行,查询语句 ...
- 用一条UPDATE语句交换两列的值
在SQL UPDATE语句中,"="右侧的值在整个UPDATE语句中都是一致的,所有更新同时发生!因此以下语句将在没有临时变量的情况下交换两列的值: UPDATE table SE ...
随机推荐
- rsync(二):inotify+rsync详细说明和sersync
以下是rsync系列篇: inotify+rsync 如果要实现定时同步数据,可以在客户端将rsync加入定时任务,但是定时任务的同步时间粒度并不能达到实时同步的要求.在Linux kernel 2. ...
- vue随笔2
vue2.0中移除.sync修饰符 .sync可是实现props的双向数据绑定,但是会破坏[单向数据流]的假设.这样的话在改变子组件时,父组件同时也改变,你完全不知道它是何时悄悄地改变了父组件的状态. ...
- jsp实现文件上传(二)用cos组件实现文件上传
jsp表单 <%@ page language="java" pageEncoding="utf-8"%> <html> <hea ...
- 任务12:Bind读取配置到C#实例
将json文件的配置转换成C#的实体 新建项目: Normal 0 7.8 磅 0 2 false false false EN-US ZH-CN X-NONE /* Style Definition ...
- Codeforces 378C
DFS连通块,思路就是搜到底,然后一个一个回溯(填上X)上来 #include <iostream> #include <stdio.h> #include <strin ...
- bzoj 3576: [Hnoi2014]江南乐【博弈论】
这个东西卡常--预处理的时候要先把i%j,i/j都用变量表示,还要把%2变成&1-- 首先每一堆都是不相关子游戏,所以对于每一堆求sg即可 考虑暴力枚举石子数i,分割块数j,分解成子问题求xo ...
- Codeforces Round #516 Div2 (A~D)By cellur925
比赛传送门 A. Make a triangle! 题目大意:给你三根木棒,选出其中一根木棒增加它的长度,使构成三角形,问增加的长度最小是多少. 思路:签到题,根据样例/三角形性质不难发现,答案就是最 ...
- CentOS7下如何正确安装并启动Docker(图文详解)
我使用了CentOS 7操作系统,可以非常容易地安装Docker环境.假设,下面我们都是用root用户进行操作,执行如下命令进行准备工作: yum install -y yum-utils yum-c ...
- Cloudera Manager架构原理
cloudera manager的核心是管理服务器,该服务器承载管理控制台的Web服务器和应用程序逻辑,并负责安装软件,配置,启动和停止服务,以及管理上的服务运行群集. Cloudera Manage ...
- gvim 常用键
按i 切换到插入模式,ESC退出 命令模式下 dd 删除一行 dw 删除一个字 x 删除一个字符 :set num 设置行号 :reg 查看寄存器 p 粘贴 y 复制 "*p 不同环境下 ...