基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子
在Windows环境上搭建Hadoop环境需要安装jdk1.7或以上版本.有了jdk之后,就可以进行Hadoop的搭建.
首先下载所需要的包:
1. Hadoop包: hadoop-2.5.2.tar.gz
2. Eclipse插件: hadoop-eclipse-plugin-2.5.2.jar
3. Hadoop在Windows运行插件包: hadooponwindows-master.zip
4. 测试数据: 1901和1902年天气预报文件
以上文件下载链接: https://pan.baidu.com/s/1R9qFdFDWHN1NnCW83VQiJg 密码: lkpp
将以上的文件都下载下来之后,进行Hadoop的安装.
第一步: 安装hadoop
1. 将下载的 hadoop-2.5.2.tar.gz 解压到指定目录, 例如我的就是放在 C:\hadoop, 一下所有的例子都以该目录为标准
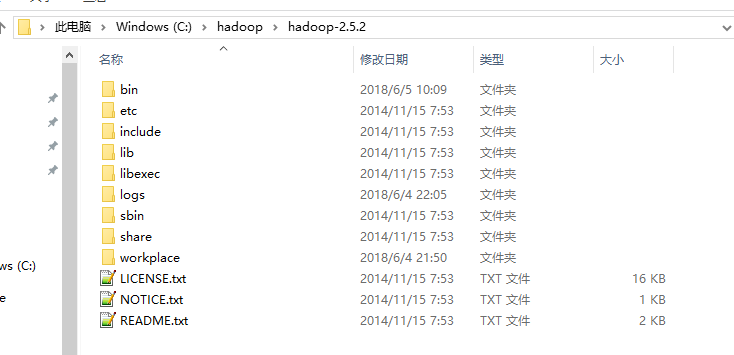
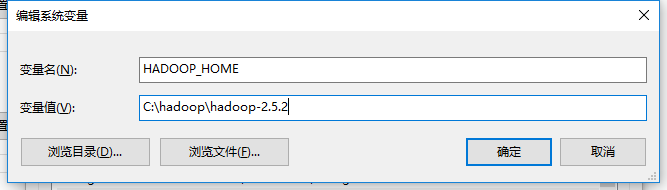
2. 配置Hadoop环境变量
2. 修改Hadoop配置文件
2.1 编辑 %HADOOP_HOME%\etc\hadoop 下的core-site.xml文件, 加入以下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/C:/hadoop/hadoop-2.5.2/workplace/tmp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/C:/hadoop/hadoop-2.5.2/workplace/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.2 编辑 %HADOOP_HOME%\etc\hadoop 下的mapred-site.xml文件, 加入以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
2.3 编辑 %HADOOP_HOME%\etc\hadoop 下的hdfs-site.xml文件, 加入以下内容
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/C:/hadoop/hadoop-2.5.2/workplace/data</value>
</property>
</configuration>
2.4 编辑 %HADOOP_HOME%\etc\hadoop 下的yarn-site.xml文件, 加入以下内容
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
2.5 编辑 %HADOOP_HOME%\etc\hadoop 下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为本机JAVA_HOME的路径,然后保存

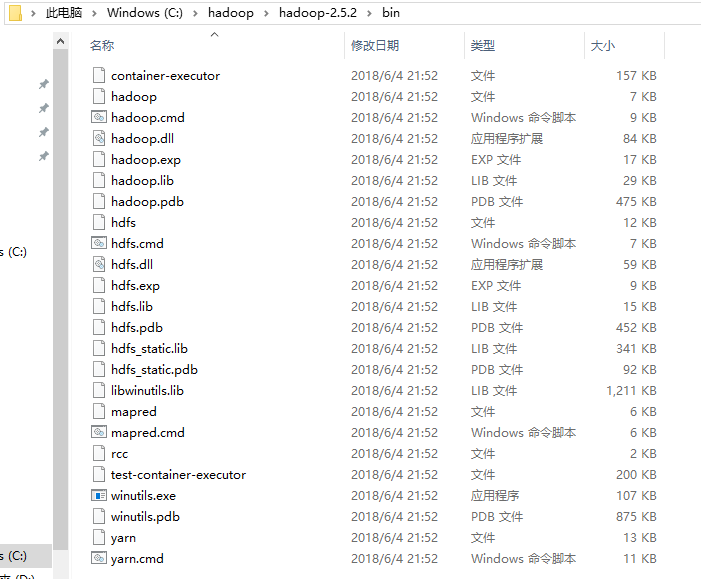
3. 配置Hadoop在Windows上的运行环境
将下载的 hadooponwindows-master.zip 解压, 并将bin目录下的所有文件替换到 %HADOOP_HOME%\bin 目录下
4. DOM窗口运行以下命令:
hdfs namenode -format
5. DOM窗口切换到 %HADOOP_HOME%\sbin 目录, 可以进行Hadoop的启动和停止
启动: start-all.cmd
停止: stop-all.cmd
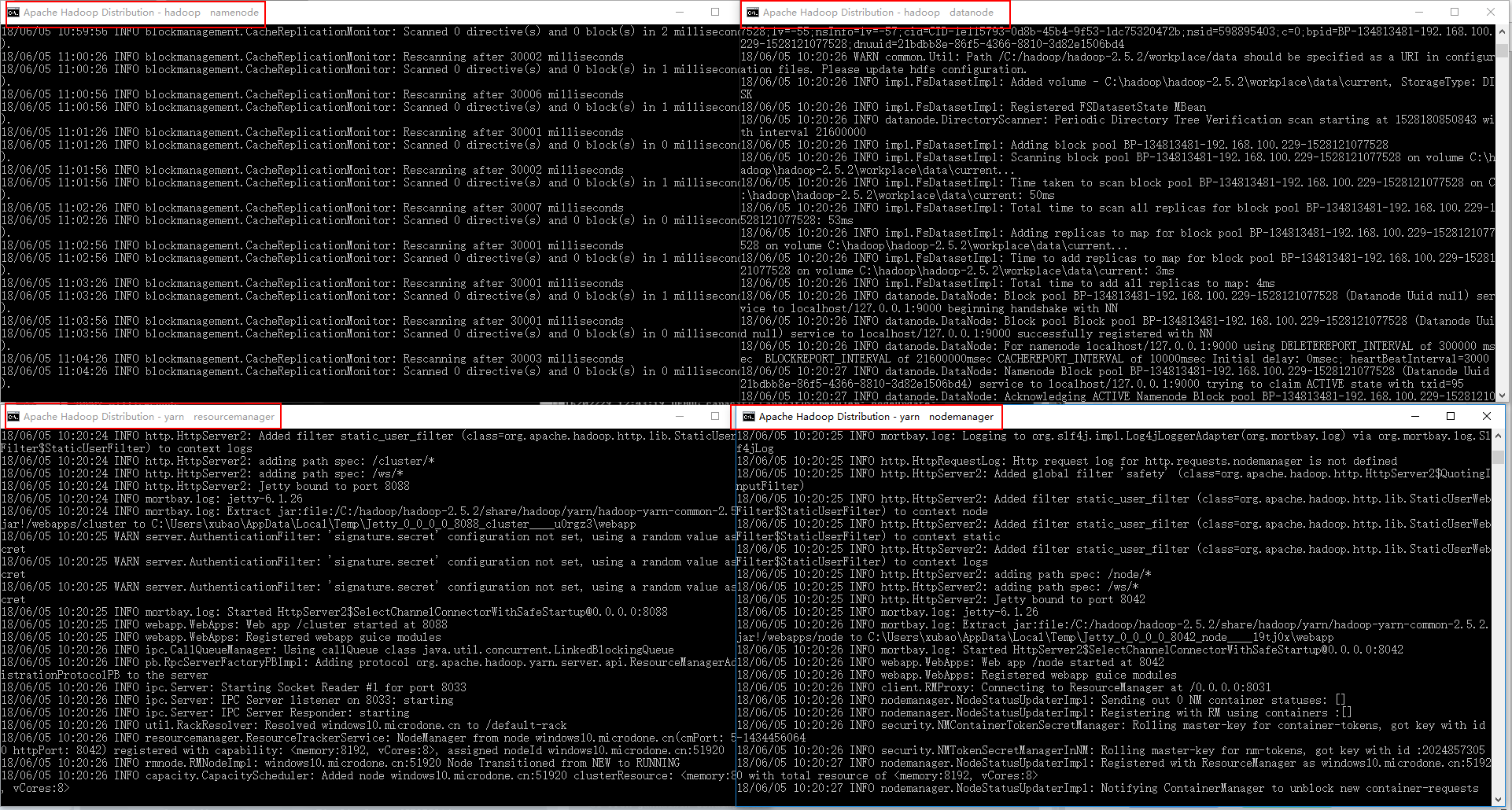
5.1 运行 start-all.cmd 如果出现类似于以下界面说明Hadoop在Windows上部署成功

6. 根据 core-site.xml 的配置, 接下来就可以通过:hdfs://localhost:9000 来对hdfs进行操作了
6.1 创建输入目录
hadoop fs -mkdir hdfs://localhost:9000/user/
hadoop fs -mkdir hdfs://localhost:9000/user/input
6.2 上传测试数据到目录
hadoop fs -put C:\hadoop\data\1901 hdfs://localhost:9000/user/input
hadoop fs -put C:\hadoop\data\1902 hdfs://localhost:9000/user/input
6.3 查看上传上去的文件
hadoop fs -ls hdfs://localhost:9000/user/input
出现以下界面说明上传成功

7. 安装Eclipse插件
7.1 将下载的 hadoop-eclipse-plugin-2.5.2.jar 文件放到Eclipse安装目录下的plugins下, 重启Eclipse
7.2 点击菜单栏 Windows–>Preferences ,如果插件安装成功,就会出现如下图

7.3 配置Hadoop安装目录

7.4 调出 Map/Reduce 视图
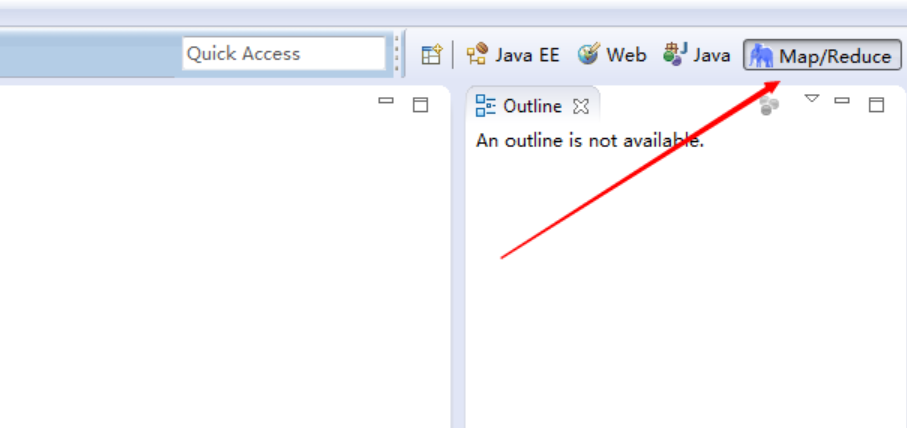
7.5 点击 Map/Redure Locations 窗口,空白处右键New Hadoop location

7.6 填写参数,连接参数, 然后 Finish

8. 编写测试类:
8.1 创建Map/Redure Project
右键 –> New –> Other –> Map/Redure Project
8.2 编写测试代码
package hadoop.code01.maxtemperature; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.log4j.BasicConfigurator; public class MaxTemperature { public static class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private static final Integer MISSING = 9999; @Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
System.out.println("line: " + line);
System.out.println("year: " + year);
Integer air;
if (line.charAt(87) == '+') {
air = Integer.parseInt(line.substring(88, 92));
} else {
air = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
System.out.println("quality: " + quality);
if (!MISSING.equals(air) && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(air));
}
}
} public static class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
Integer maxValue = Integer.MIN_VALUE;
System.out.println("maxValue0: " + maxValue);
for (IntWritable value : values) {
System.out.println("maxValue1: " + maxValue);
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
} public static class Temperature { public static void main(String[] args) throws Exception, ClassNotFoundException, InterruptedException {
BasicConfigurator.configure(); // 自动快速地使用缺省Log4j环境。
System.out.println("kaishi...");
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <Input path> <Output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = new Job(conf); job.setJarByClass(MaxTemperature.class);
job.setJobName("maxTemperature"); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); System.out.println("jieshu...");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} }
8.3 执行测试
Run As –> Run Configurations
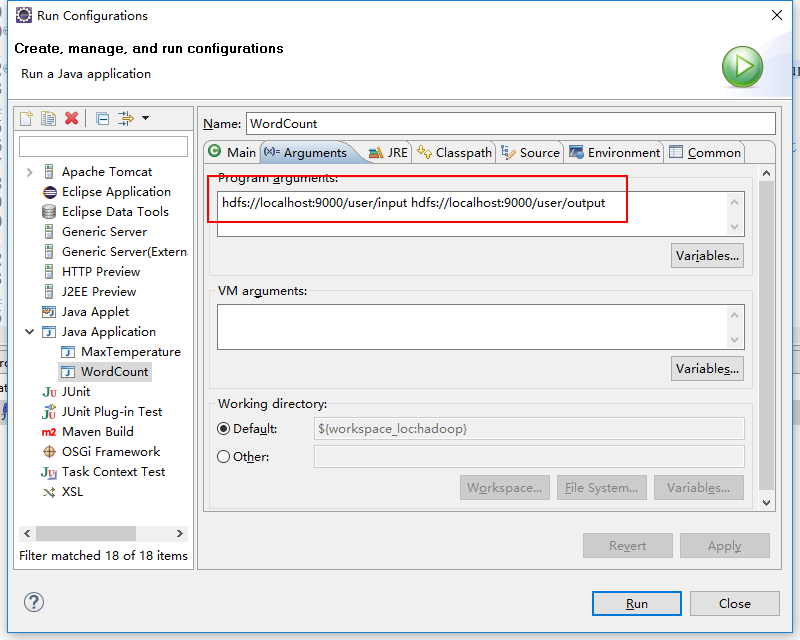
8.4 点击 Run 运行, 然后在DOM窗口执行查看输出结果
hadoop fs -ls hdfs://localhost:9000/user/output

8.5 执行 hadoop fs -cat hdfs://localhost:9000/user/output/part-r-00000 查看算法执行结果数据

至此, 第一个Hadoop例子执行成功
基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子的更多相关文章
- Android编程权威指南第三版 第32章
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qq_35564145/article/de ...
- hadoop权威指南(第四版)要点翻译(4)——Chapter 3. The HDFS(1-4)
Filesystems that manage the storage across a network of machines are called distributed filesystems. ...
- hadoop权威指南(第四版)要点翻译(5)——Chapter 3. The HDFS(5)
5) The Java Interface a) Reading Data from a Hadoop URL. 使用hadoop URL来读取数据 b) Although we focus main ...
- CSS权威指南-第三版--读书笔记
第一章:CSS和文档 html是结构化语言,css是样式语言,html主要用来被强大的搜索引擎更好的索引,更好的让一个盲人通过语音浏览器来了解我们的网页,这也就是为什么说html是结构话语言,因为这是 ...
- [读书笔记]Hadoop权威指南 第3版
下面归纳概述了用于设置MapReduce作业输出的压缩格式的配置属性.如果MapReduce驱动使用了Tool接口,则可以通过命令行将这些属性传递给程序,这比通过程序代码来修改压缩属性更加简便. Ma ...
- Android编程权威指南(第三版)- 2.8 挑战练习:添加后退按钮
package com.example.geoquiz; import android.support.v7.app.AppCompatActivity; import android.os.Bund ...
- Hadoop权威指南:通过FileSystem API读取数据
Hadoop权威指南:通过FileSystem API读取数据 [TOC] 在Hadoop中,FileSystem是一个通用的文件系统API 获取FileSystem实例的几个静态方法 public ...
- Hadoop权威指南(中文版-带目录索引)pdf电子书
Hadoop权威指南(中文版-带目录索引)pdf电子书下载地址:百度网盘点击下载:链接:https://pan.baidu.com/s/1E-8eLaaqTCkKESNPDqq0jw 提取码:g6 ...
- Hadoop权威指南:压缩
Hadoop权威指南:压缩 [TOC] 文件压缩的两个好处: 减少储存文件所需要的磁盘空间 加速数据在网络和磁盘上的传输 压缩格式总结: 压缩格式 工具 算法 文件扩展名 是否可切分 DEFLATE ...
随机推荐
- 任意两点间最短距离floyd-warshall ---- POJ 2139 Six Degrees of Cowvin Bacon
floyd-warshall算法 通过dp思想 求任意两点之间最短距离 重复利用数组实现方式dist[i][j] i - j的最短距离 for(int k = 1; k <= N; k++) f ...
- java多线程调试
1. 多线程调试 https://blog.csdn.net/bramzhu/article/details/52367052 https://www.jb51.net/article/129632. ...
- Linux--进程组、会话、守护进程(转)
http://www.cnblogs.com/forstudy/archive/2012/04/03/2427683.html 进程组 一个或多个进程的集合 进程组ID: 正整数 两个函数 getpg ...
- java基础语法——方法,static关键字
一:方法: 1.什么是方法: 通俗地讲,方法就是行为.它是完成特定功能的代码块能执行一个功能.它包含于类和对象中. 2.为什么要有方法: *提高代码的复用性. *提高效率 *利于程序维护 3.命名规则 ...
- Java后端技术书单
写博客记录技术上使用的各种问题,这个只能算是一个打游击. 如果要把一个知识学透,最有效的方式就是系统学习,而系统学习就是看书,书本上有清晰的学习路线以及相应的技术栈. 下面是我收集的Java后端的技术 ...
- Android中传递对象的三种方法
Android知识.前端.后端以至于产品和设计都有涉猎,想成为全栈工程师的朋友不要错过! Android中,Activity和Fragment之间传递对象,可以通过将对象序列化并存入Bundle或者I ...
- 【APUE】一个fork的面试题及字符设备、块设备的区别
具体内容见:http://coolshell.cn/articles/7965.html 字符设备.块设备主要区别是:在对字符设备发出读/写请求时,实际的硬件I/O一般就紧接着发生了,而块设备则不然, ...
- [Javascript] Link to Other Objects through the JavaScript Prototype Chain
Objects have the ability to use data and methods that other objects contain, as long as it lives on ...
- 编译iOS使用的.a库文件
首先是须要编译成.a的源文件 hello.h: #ifndef __INCLUDE_HELLO_H__ #define __INCLUDE_HELLO_H__ void hello(const cha ...
- 西门子PLC学习笔记六-(Step7指令简单介绍)
1.指令操作数 指令操作数由操作标示符和參数组成. 操作标识符由主标识符和辅标识符组成. 主标识符有:I(输入过程影像寄存器).Q(输出过程映像寄存器).M(位寄存器).PI(外部输入寄存器).PQ( ...