Oracle Spatial中的空间索引
转自cryolite原文 Oracle Spatial中的空间索引
Oracle Spatial可对空间数据进行R-tree索引,每个空间图层(Spatial Layer)的空间索引元信息都可以在USER_SDO_INDEX_METADATA视图中找到。
具体的索引数据保存在MDRT字段开头的表中, 每个空间图层都会对应一个索引表(表的格式是MDRT_[...]$),空间索引表中的主要数据是MBR
通过空间索引元数据视图(USER_SDO_INDEX_METADATA)可以查到每个空间图层的空间索引名、空间索引数据表名、R-tree索引的根节点ROWID,R-tree的分支因子(又叫扇出fanout,即R-tree节点的最大子节点数)及其它相关信息。
索引的创建:
1. R-tree索引:
CREATE INDEX customers_sidx ON customers(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX;
2. 四叉树索引:
CREATE INDEX customers_sidx ON customers(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
PARAMETERS ('SDO_LEVEL=8');
在Oracle Spatial中,四叉树索引不如R-tree索引,因为:
1. 只能对二维非geodesic数据创建四叉树索引;
2. 用户自己要对四叉树索引的参数进行调整,而R-tree索引的参数比较好调,也更自动。
关于四叉树索引可以参考文档: Oracle Spatial Quadtree Indexing
索引的效率:
1. 如果表空间指定为ASSM表空间(user_tablespaces表中segment_space_management为AUTO即是),索引中的LOB数据将是SECUREFILE LOB的,这比一般的BASIC LOB快。
2.
空间索引创建过程中会临时产生许多工作表,创建完后会删除这些工作表,这一过程中(大量不同大小的表的创建和删除,其数据量大约是要索引的表的200-300倍)会使得表空间(tablespace)产生许多碎片从而影响表空间效率,可以为这些工作表指定独立的表空间(即指定WORK_TABLESPACE)避免这一效率损失:
CREATE INDEX customers_sidx ON customers(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
PARAMETERS ('WORK_TABLESPACE=SYSAUX');
注意工作表空间不得使用temporacy表空间。如果不指定工作表空间,缺省同要索引之表的表空间。
3. 要索引的geometry列如果都是相同形状的几何体(例如都是点),在创建索引时指定要索引空间图层中的几何体类型会提高查询速度:
CREATE INDEX customers_sidx ON customers(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
PARAMETERS ('LAYER_GTYPE=POINT');
4. 如果需要在事务中进行大量的数据删除/插入时可以考虑为空间索引设置SDO_DML_BATCH_SIZE参数,在事务中删除/插入数据后并不会马上就更新索引,而是在事务提交时、或者删除/插入的数量达到某个批量值时统一索引更新,这个值(即SDO_DML_BATCH_SIZE)缺省为1000,对于大多数操作这个值足够了。但是如果你的表在工作中会有大量删除/插入操作,那么可以考虑将这个值设得更大以提高效率,代价是更多的内存和系统资源消耗:
CREATE INDEX customers_sidx ON customers(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
PARAMETERS ('SDO_DML_BATCH_SIZE=5000');
这个值最好设在5000-10000之间。
另一个提高大量插入删除效率的方法是在大批量操作之前删除索引,之后再重建索引
5. 对于一个有N个记录的表创建空间索引:
1). R-tree的空间索引表大概需要100×3N个字节的存储空间;
2). 在R-tree空间索引创建过程中,在临时的数据表空间中需要200×3N到300×3N字节的额外存储空间。
可以通过下列语句估算为一个空间图层创建R-tree索引需要的存储空间大小:
SELECT sdo_tune.estimate_rtree_index_size('SPATIAL', 'CUSTOMERS', 'LOCATION') sz FROM dual;
sz
-----------------
1
结果为1,表示
1). 索引数据需要1M字节的存储空间,这是索引数据本身所需的存储空间,此外在索引创建过程中2到3倍这个值的存储空间;
2). 当创建空间索引时,指定session参数SORT_AREA_SIZE为这个值(1MB)会优化索引创建过程。
6. 如果使用SDO_NN空间操作符的效率问题
1) SDO_NN空间操作时,空间索引会遮蔽其它索引,因此不要期望使用SDO_NN空间操作符时在WHERE语句中加入更多的限制条件会加快查询速度,这时对SDO_BATCH_SIZE参数进行微调有可能会提高查询效率。
SELECT ct.id, ct.name, ct.customer_grade
FROM competitors comp, customers ct
WHERE comp.id=1
AND ct.customer_grade='GOLD'
AND SDO_NN(ct.location, comp.location)='TRUE'
AND ROWNUM<=5
ORDER BY ct.id;
尽管customer_grade字段有索引,但是这不会加快空间查询的速度,执行时可能先找出10条最近的记录,看是否是'GOLD'的,如果不是则找出接下来10条最近的记录,。。。。。直到所有'GOLD'的用户有5条为止。
如果预计5条'GOLD'用户肯定在前100个最近的记录里,则通过设置SDO_BATCH_SIZE参数为100可以加快查询速度:
SELECT ct.id, ct.name, ct.customer_grade
FROM competitors comp, customers ct
WHERE comp.id=1
AND ct.customer_grade='GOLD'
AND SDO_NN(ct.location, comp.location, 'SDO_BATCH_SIZE=100' )='TRUE'
AND ROWNUM<=5
ORDER BY ct.id;
如果你不知道SDO_BATCH_SIZE该设为多少,就设为0,索引会在使用合适的内部值。
2) 限定SDO_NN返回的记录数量会加快查询的速度,这通过调整SDO_NUM_RES设置:
SELECT ct.id, ct.name, ct.customer_grade
FROM competitors comp, customers ct
WHERE comp.id=1
AND SDO_NN(ct.location, comp.location, 'SDO_NUM_RES=5')='TRUE' ;
效果与这个相同:
SELECT ct.id, ct.name, ct.customer_grade
FROM competitors comp, customers ct
WHERE comp.id=1
AND SDO_NN(ct.location, comp.location)='TRUE'
AND ROWNUM<=5
ORDER BY ct.id;
空间索引与分区
上面建立的索引是全表范围内的,是“全局”索引,在对数据库表进行分区后,可以在每个分区上建立一个“本地(Local)”索引。
进行带空间操作符的空间查询时,Oracle会在每个分区的索引上进行查询,然后将各个分区上的查询结果汇集,最后将结果返回给用户。因此,分区索引并不总能加快查询速度。
分区也会影响查询返回的结果:
例如SDO_NN操作符中的SDO_NUM_RES参数会指定符合条件的结果数量,但是如果是分区索引的话,则在每个分区上都得满足此参数,如果有3个分区,那么最终返回的结果数量将是SDO_NUM_RES×3,而不是SDO_NUM_RES。
注:以上讨论的分区是由限制的,只能是range分区,list分区和哈希分区都不行
空间索引与并行
创建索引时可以指定索引并行,例如:
CREATE INDEX customers_sidx ON customers(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
PARALLEL [parallel_degree];
并行参数parallel_degree是可选的,它定义了并行度,如果大于1,则索引创建时会并行进行。
但查询时无法指定并行,查询的并行实际上与数据库表的分区有关,也就是说查询会在每个分区上并行的进行。因此设定表的并行度并分区会提高使用空间索引的空间分析操作的性能。
ALTER TABLE customers PARALLEL 2 ;
空间索引的重建
在对表进行大量(大约30%)删除后,对空间索引进行重建可以提高未来数据的查询效率:
ALTER INDEX customers_sidx REBUILD ;
重建时也可以指定参数:
ALTER INDEX customers_sidx REBUILD
PARAMETERS ('layer_gtype=POINT');
注意:
1. ALTER INDEX是一个DDL语句,因此会导致当前事务的提交;
2. 空间索引重建是个耗时操作,它以排他锁的方式阻止了在空间索引上的其它操作,从而造成相应空间查询操作的阻塞,不过可以指定ONLINE关键字避免这种堵塞发生:
ALTER INDEX customers_sidx REBUILD ONLINE
PARAMETERS ('layer_gtype=POINT');
ONLINE重建索引的过程如图所示:
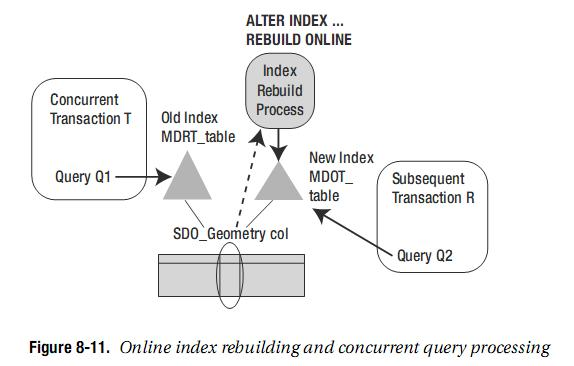
重建的索引数据保存到新索引表上,重建时旧的索引表仍在,旧的查询在旧索引上,因此重建过程不会影响正在进行的查询,在新索引建好后再切换到新的索引表上。
要了解更多关于Oracle Spatial空间索引设计原理:
“Efficient Processing of Large Spatial Queries using Interior
Approximations.” Proceedings of the 7th International Symposium on
Spatial and Temporal Databases (SSTD), 2001.
Oracle Spatial中的空间索引的更多相关文章
- Oracle Spatial 中的弧段及弧相关拓扑错误
1.报告说明 此报告用于验证下列问题: ORACLE SPATIAL 0.05m的最小拓扑容差值是否可以被修改 原始数据通过ARCGIS入库数据精度是否有损失 修改ORACLE SPATIAL图层的最 ...
- Oracle Spatial中SDO_Geometry说明
Oracle Spatial中SDO_Geometry说明 在ArcGIS中通过SDE存储空间数据到Oracle中有多种存储方式,分别有:二进制Long Raw .ESRI的ST_Geometry以及 ...
- 在Oracle Spatial中增加Web Mercator投影坐标系
参考资料: 1. 最重要的参考文章,基本上就是按这个做的!!!:https://www.inf.unibz.it/dis/wiki/doku.php?id=students:minnerebner:o ...
- Oracle Spatial中SDO_Geometry详细说明[转]
在ArcGIS中通过SDE存储空间数据到Oracle中有多种存储方式,分别有:二进制Long Raw .ESRI的ST_Geometry以及基于Oracle Spatial的SDO_Geometry等 ...
- 【转载】Oracle Spatial中SDO_Geometry详细说明
转载只供个人学习参考,查看请前往原出处:http://www.cnblogs.com/upDOoGIS/archive/2009/05/20/1469871.html 相关微博:oracle 创建SD ...
- Oracle Spatial GIS相关研究
1.Oracle Spatial 概念相关 Oracle Spatial 是Oracle 数据库强大的核心特性,包含了用于存储矢量数据类型.栅格数据类型和持续拓扑数据类型的原生数据类型.Oracle ...
- Oracle spatial与arcsde 的关系
有一些同事问过我下面这些问题: 我们用了oracle spatial sdo_geometry,是不是没用arcsde? 我们到底是使用oracle spatial还是arcsde,有点懵! 执行了c ...
- Oracle Spatial操作geometry方法
Oracle Spatial中SDO_GEOMETRY类型: CREATE TYPE SDO_GEOMETRY AS OBJECT( SDO_GTYPE NUMBER,--几何类型,如点线面 SDO_ ...
- Oracle spatial抽稀函数(SDO_UTIL.SIMPLIFY)
在使用Oracle spatial做空间查询和展示时,经常会遇到展示或者查询过慢,这时候我可以通过空间数据抽稀来优化查询展示效率. 在Oracle spatial中的抽稀函数为:SDO_UTIL.SI ...
随机推荐
- app自动化配置信息
caps={ "platformName":"Android",#平台名称 "platformVersion":"6. ...
- 【软件构造】(转)Git详解、常用操作与版本图
版本控制与Git 转自:http://www.cnblogs.com/angeldevil/p/3238470.html 版本控制 版本控制是什么已不用在说了,就是记录我们对文件.目录或工程等的修改历 ...
- Hibernate-02 HQL实用技术
学习任务 Query接口的使用 HQL基本用法 动态参数绑定查询 HQL的使用 Hibernate支持三种查询方式:HQL查询.Criateria查询.Native SQL查询. HQL是Hibern ...
- bonding的系统初始化介绍
bond0模块的加载 Bonding原理 为方便理解bonding的配置及实现,顺便阐述一下Linux的网络接口及其配置文件.在 Linux 中,所有的网络通讯都发生在软件接口与物理网络设备之间.与网 ...
- IOS学习笔记37——ViewController生命周期详解
在我之前的学习笔记中讨论过ViewController,过了这么久,对它也有了新的认识和体会,ViewController是我们在开发过程中碰到最多的朋友,今天就来好好认识一下它.ViewContro ...
- (转)浅谈trie树
浅谈Trie树(字典树) Trie树(字典树) 一.引入 字典是干啥的?查找字的. 字典树自然也是起查找作用的.查找的是啥?单词. 看以下几个题: 1.给出n个单词和m个询问,每次询问 ...
- css选择器(2)——属性选择器和基于元素结构关系的选择器
在有些标记语言中,不能使用类名和id选择器,于是css2引入了属性选择器. 3.属性选择器 a)根据是否存在该属性来选择 如果希望选择有某个属性的元素,例如要选择有class属性的所有h1元素,使其文 ...
- 【HIHOCODER 1033 】 交错和(数位DP)
描述 输入 输入数据仅一行包含三个整数,l, r, k(0 ≤ l ≤ r ≤ 1018, |k| ≤ 100). 输出 输出一行一个整数表示结果,考虑到答案可能很大,输出结果模 109 + 7. 提 ...
- 利用virtualbox中的虚机制作主机启动盘
制作镜像的过程: 第一步:1.Windows下先下载安装virtualbox usb3.0驱动:https://download.virtualbox.org/virtualbox/5.2.20/Or ...
- CodeForces 22、23部分题解
CodeForces 22A 找严格第二小的...注意只有一种情况,可以sort排序然后unique输出. int a[N]; int main() { int n; while(~scanf(&qu ...