SpringBoot性能优化的12个小技巧
前言
不知道你在SpringBoot项目中,有没有遇到过下面这样的代码:
@GetMapping("/orders")
public List<Order> listOrders() {
return orderDao.findAll();
}
一次性查询了所有的订单,全表扫描50万数据,导致接口查询性能很差,严重的时候可能会导致OOM问题。
问题定位:
- 未分页查询
- 无缓存机制
- 未启用批量处理
这次事故让我明白:性能优化必须贯穿开发全流程。
今天这篇文章,跟大家一起聊聊SpringBoot优化的12招,希望对你会有所帮助。
第1招:连接池参数调优
问题场景:
默认配置导致连接池资源浪费,高并发时出现连接等待
错误配置:
spring:
datasource:
hikari:
maximum-pool-size: 1000
connection-timeout: 30000
数据库连接池的最大连接数,盲目设置过大,连接超时时间设置过长。
优化方案:
spring:
datasource:
hikari:
maximum-pool-size: ${CPU核心数*2} # 动态调整
minimum-idle: 5
connection-timeout: 3000 # 3秒超时
max-lifetime: 1800000 # 30分钟
idle-timeout: 600000 # 10分钟空闲释放
数据库连接池的最大连接数,改成根据CPU核心数动态调整。
将连接超时时间由30000,改成3000。
第2招:JVM内存优化
问题场景:
频繁Full GC导致服务卡顿
我们需要优化JVM参数。
启动参数优化:
java -jar -Xms4g -Xmx4g
-XX:NewRatio=1
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:InitiatingHeapOccupancyPercent=35
-XX:+AlwaysPreTouch
最大堆内存和初始堆内存都设置成了4G。
-XX:NewRatio=1,设置新生代和老年代各占一半。
垃圾收集器配置的是G1。
垃圾回收的最大停顿时间为200毫秒。
第3招:关闭无用组件
问题场景:
自动装配加载不需要的Bean
优化方案:
@SpringBootApplication(exclude = {
DataSourceAutoConfiguration.class,
SecurityAutoConfiguration.class
})
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
如果有些功能暂时用不到,可以先排除一下。
在SpringBoot项目启动的时候,排除了DataSourceAutoConfiguration和SecurityAutoConfiguration配置类的自动装载。
第4招:响应压缩配置
问题场景:
接口返回JSON数据体积过大
优化方案:
server:
compression:
enabled: true
mime-types: text/html,text/xml,text/plain,text/css,text/javascript,application/json
min-response-size: 1024
配置开启响应的压缩。
第5招:请求参数校验
问题场景:
恶意请求导致资源耗尽
防御代码:
@GetMapping("/products")
public PageResult<Product> list(
@RequestParam @Max(value=100, message="页大小不能超过100") int pageSize,
@RequestParam @Min(1) int pageNum) {
//...
}
在接口中做好参数校验,可以拦截很多恶意请求。
第6招:异步处理机制
问题场景:
同步处理导致线程阻塞
优化方案:
@Async("taskExecutor")
public CompletableFuture<List<Order>> asyncProcess() {
return CompletableFuture.completedFuture(heavyProcess());
}
@Bean("taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(500);
return executor;
}
在有些业务逻辑中,使用异步处理性能可能会更好。
第7招:使用缓存
使用缓存可以提升效率。
缓存架构:
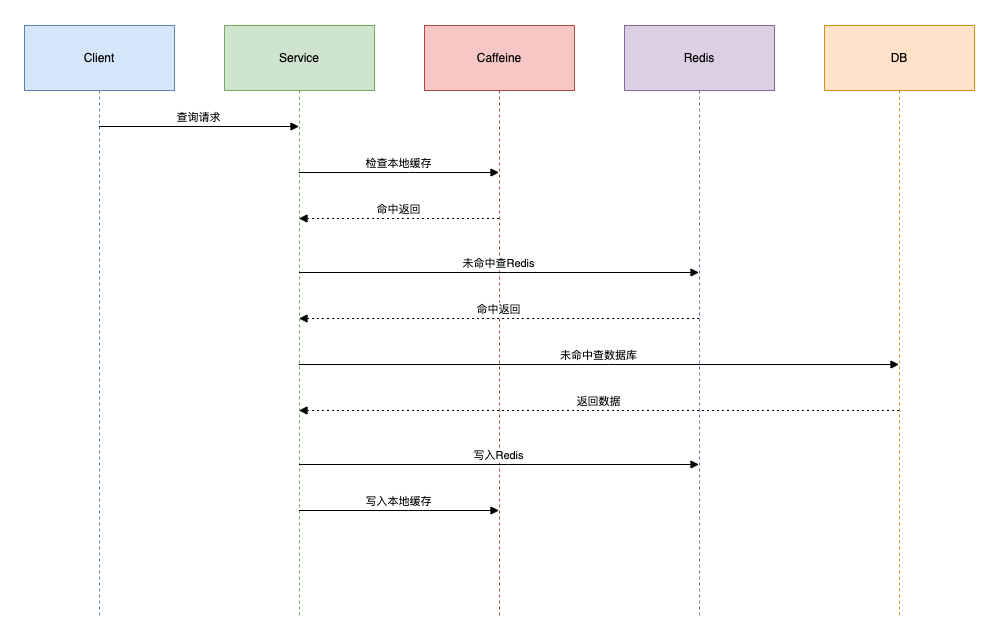
代码实现:
@Cacheable(cacheNames = "products", key = "#id",
cacheManager = "caffeineCacheManager")
public Product getDetail(Long id) {
return productDao.getById(id);
}
这里使用了内存缓存。
第8招:批量操作优化
问题场景:
逐条插入导致性能低下
优化方案:
@Transactional
public void batchInsert(List<Product> products) {
jdbcTemplate.batchUpdate(
"INSERT INTO product(name,price) VALUES(?,?)",
products,
500, // 每批数量
(ps, product) -> {
ps.setString(1, product.getName());
ps.setBigDecimal(2, product.getPrice());
});
}
每500条数据插入一次数据库。
第9招:索引深度优化
问题场景:
慢查询日志频繁出现全表扫描,SQL执行时间波动大
错误案例:
-- 商品表结构
CREATE TABLE products (
id BIGINT PRIMARY KEY,
name VARCHAR(200),
category VARCHAR(50),
price DECIMAL(10,2),
create_time DATETIME
);
-- 低效查询
SELECT * FROM products
WHERE category = '手机'
AND price > 5000
ORDER BY create_time DESC;
问题分析:
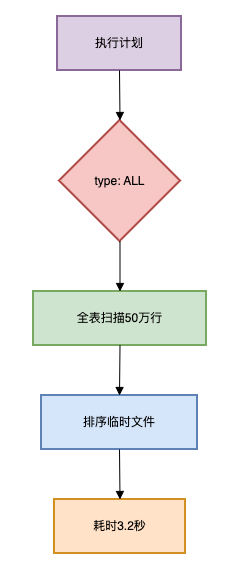
优化方案一:联合索引设计
索引创建:
下面创建了一个分类ID,单价和时间的联合索引:
ALTER TABLE products
ADD INDEX idx_category_price_create
(category, price, create_time);
优化方案二:覆盖索引优化
查询改造:
只查询索引包含字段:
SELECT id, category, price, create_time
FROM products
WHERE category = '手机'
AND price > 5000
ORDER BY create_time DESC;
这里使用了覆盖索引。
优化方案三:索引失效预防
常见失效场景:
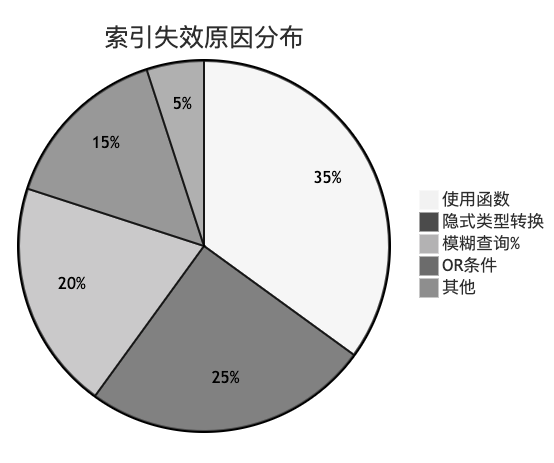
案例修复:
错误写法:
SELECT * FROM products
WHERE DATE(create_time) = '2023-01-01';
正确写法:
SELECT * FROM products
WHERE create_time BETWEEN '2023-01-01 00:00:00'
AND '2023-01-01 23:59:59';
查询时间范围,这里使用了BETWEEN AND关键字,代替了等于号。
优化方案四:索引监控分析
诊断命令:
查看索引使用情况:
SELECT
index_name,
rows_read,
rows_selected
FROM
sys.schema_index_statistics
WHERE
table_name = 'products';
分析索引效率:
EXPLAIN FORMAT=JSON
SELECT ...;
索引优化黄金三原则
- 最左前缀原则:联合索引的第一个字段必须出现在查询条件中
- 短索引原则:整型字段优先,字符串字段使用前缀索引
- 适度索引原则:单个表索引数量不超过5个,总索引长度不超过表数据量30%
DBA工具箱
- 索引分析脚本
- 执行计划可视化工具
- 索引碎片检测工具
第10招:自定义线程池
问题场景:
默认线程池导致资源竞争
优化方案:
@Bean("customPool")
public Executor customThreadPool() {
return new ThreadPoolExecutor(
10, // 核心线程
50, // 最大线程
60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new CustomThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
}
在高并发业务场景中,使用Executors类创建默认的线程池,可能会导致OOM问题。
因此,我们需要自定义线程池。
第11招:熔断限流策略
问题场景:
突发流量导致服务雪崩
解决方案:
// 使用Sentinel实现接口限流
@SentinelResource(value = "orderQuery",
blockHandler = "handleBlock",
fallback = "handleFallback")
@GetMapping("/orders/{id}")
public Order getOrder(@PathVariable Long id) {
return orderService.getById(id);
}
// 限流处理
public Order handleBlock(Long id, BlockException ex) {
throw new RuntimeException("服务繁忙,请稍后重试");
}
// 降级处理
public Order handleFallback(Long id, Throwable t) {
return Order.getDefaultOrder();
}
为了解决重复流量导致服务雪崩的问题,我们需要增加接口熔断、限流和降级处理。
第12招:全链路监控体系
问题场景:
线上问题定位困难,缺乏数据支撑
我们需要增加项目全链路的监控。
监控方案:
# SpringBoot配置
management:
endpoints:
web:
exposure:
include: "*"
metrics:
export:
prometheus:
enabled: true
这里使用了prometheus监控。
监控架构:
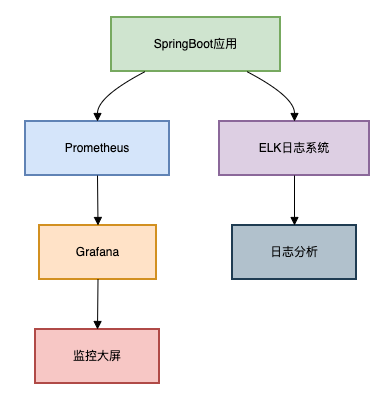
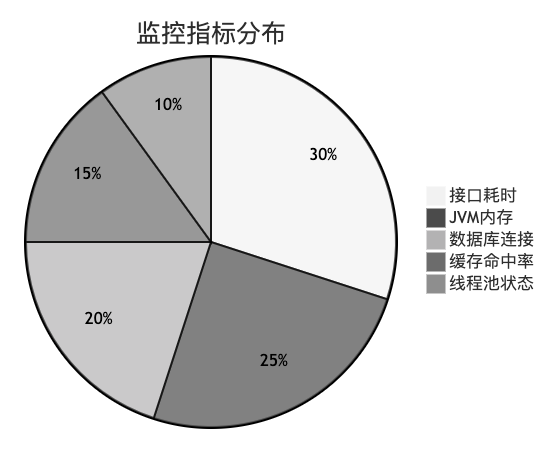
核心监控指标:
总结
SpringBoot性能优化检查清单
- 连接池参数按业务调整
- JVM参数经过压测验证
- 所有查询走缓存机制
- 批量操作替代逐条处理
- 线程池按场景定制
- 全链路监控覆盖
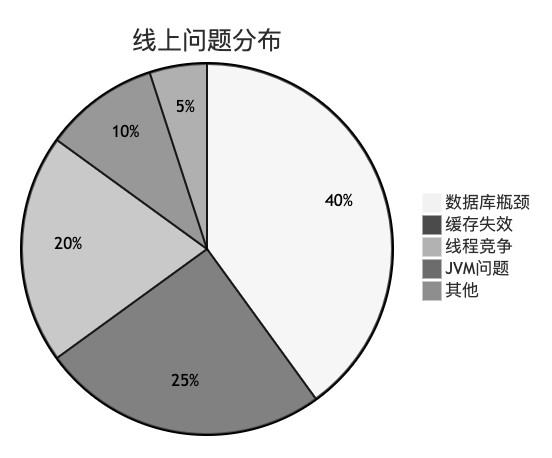
三条黄金法则:
- 预防性优化:编码时考虑性能影响
- 数据驱动:用监控指标指导优化方向
- 持续迭代:性能优化是持续过程
性能工具包
- Arthas在线诊断
- JProfiler性能分析
- Prometheus监控体系
(看着监控大屏上平稳的QPS曲线,我知道今晚可以睡个好觉了...)
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,我的所有文章都会在公众号上首发,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
本文收录于:www.susan.net.cn
SpringBoot性能优化的12个小技巧的更多相关文章
- React性能优化,六个小技巧教你减少组件无效渲染
壹 ❀ 引 在过去的一段时间,我一直围绕项目中体验不好或者无效渲染较为严重的组件做性能优化,多少积累了一些经验所以想着整理成一片文章,下图就是优化后的一个组件,可以对比优化前一次切换与优化后多次切换的 ...
- SQL性能优化的47个小技巧,你了解多少?
大家好,我是哪吒. 1.先了解MySQL的执行过程 了解了MySQL的执行过程,我们才知道如何进行sql优化. 客户端发送一条查询语句到服务器: 服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中 ...
- java 性能优化:35 个小细节,让你提升 java 代码的运行效率
前言 代码 优化 ,一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没 ...
- JAVA性能优化:35个小细节让你提升java代码的运行效率
代码优化,一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没用,但是, ...
- 【SpringBoot】SpringBoot性能优化
Spring 框架给企业软件开发者提供了常见问题的通用解决方案,包括那些在未来开发中没有意识到的问题.但是,它构建的 J2EE 项目变得越来越臃肿,逐渐被 Spring Boot 所替代.Spring ...
- 聊聊sql优化的15个小技巧
前言 sql优化是一个大家都比较关注的热门话题,无论你在面试,还是工作中,都很有可能会遇到. 如果某天你负责的某个线上接口,出现了性能问题,需要做优化.那么你首先想到的很有可能是优化sql语句,因为它 ...
- 加快Win7整体运行速度的12个小技巧
在整体运行速度方面,微软Windows 7系统超越了它的前任Vista,拥有明显的提升;但是相比最新的Windows 8,似乎又有所不及,至少很少有Windows用户能够体会到15秒的开机速度.虽然如 ...
- YbSoftwareFactory 代码生成插件【二十一】:Web Api及MVC性能提升的几个小技巧
最近在进行 YbSoftwareFactory 的流程功能升级,目前已经基本完成,现将用到的一些关于 Web Api 及 MVC 性能提升的一些小技巧进行了总结,这些技巧在使用.配置上也相当的简单,但 ...
- SpringBoot入门-SpringBoot性能优化
SpringBoot启动优化 显示声明扫包范围: 即不使用@SpringBootApplication默认扫包,使用@ComponentScan(basePackages = { "com. ...
- springboot性能优化
一.扫描优化 原文链接:http://www.studyshare.cn/blog-front/blog/details/1135 SpringBoot项目中的启动类,会使用@SpringBootAp ...
随机推荐
- mysql 无数据插入,有数据更新
mysql的语法与sql server有很多不同,sql server执行插入更新时可以update后使用if判断返回的@@rowcount值,然后确定是否插入,mysql在语句中无法使用类似sql ...
- .net 8 C# 集成 AWS Cognito SMS/Email 注册与登录
本文主要分为三个部分: 1.描述 cognito 涉及的专业术语 以及 交互流程 2..net 集成的代码 3.感想 * 阅读提示 :鼠标悬停在 章节标题 上可见 文章目录 1. Cognito 概念 ...
- TPC-H 研究和优化尝试
TPC-H测试提供了8张表,最近做这个测试,记录下过程中的关键点备忘. 1.整体理解TPC-H 8张表 2.建立主外键约束后测试22条SQL 3.分区表改造,确认分区字段 4.重新测试22条SQL 5 ...
- 最新活动 ISS 国际空间站 MAI-75 SSTV活动计划于2020年8月4日至5日
MAI-75 SSTV活动计划于2020年8月4日和5日举行 8月3日至9日这一周的最后宇航员时间表最近公布了,它显示了定于8月4日和5日进行的MAI-75活动.这是在Space X Demo-2脱 ...
- 表访问方法:PostgreSQL 中数据更新的处理方式
作者:Cary 前言 本文将详细探讨 PostgreSQL 如何处理更新操作.在 PostgreSQL 中,成功的更新可以被视为"插入一条新记录",同时"标记旧记录为不可 ...
- 2D小游戏--猜对应卡牌(unity)
博客地址:https://www.cnblogs.com/zylyehuo/ 项目名称 guess_card_game 参考源码链接: https://www.manning.com/books/un ...
- 『Plotly实战指南』--柱状图绘制基础篇
柱状图作为最基础的数据可视化形式之一,能直观展示不同类别数据的对比关系,适用于一下的场景: 比较不同类别之间的数据大小,如不同产品的销售额对比. 展示数据的分布情况,如各年龄段的人口数量分布. 分析时 ...
- 查看docker容器占用内存
ps -ef|grep 容器Id 1 2 3 [root@wentao-2 order]# ps -ef|grep 3a61cb3fd4f6 root 7358 12956 0 09:14 ...
- SOA架构和微服务架构的区别
1.SOA架构和微服务架构的区别 首先SOA和微服务架构一个层面的东西,而对于ESB和微服务网关是一个层面的东西,一个谈到是架构风格和方法,一个谈的是实现工具或组件. 1.SOA(Service Or ...
- HashMap 在高并发场景下可能出现的性能问题以及如何规避这些问题
JDK1.8 之前 HashMap 底层是 数组和链表, 之后在之前基础上加上红黑树. 相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转 ...