AI编译器及TVM整体架构
虽然之前也依据tvm官方文档写过一篇关于TVM架构的博客,但总感觉属于一种身在此山中的感觉(偏向于TVM实现的各个模块),并没有一览众山小的即视感(对框架的整体理解)。
因此,今天再次请求出战...
------华丽的分割线------
首先呢,想先来介绍下常规编译器的结构和特征
常规的编译器通常是由前端(frontend)、优化器(optimizer)、和后端(backend) 三部分组成。
编译过程以高级语言作为输入,
- 前端主要负责解析源代码的词法和语法分析,检查语法错误,并将源代码转换抽象语法树(AST, Abstract Syntax Tree)
- 优化器则是在前端的基础上,对中间代码进行优化,使代码更加高效
- 后端负责将优化后的中间代码转换为针对硬件平台的机器代码
PS:
转换过程中,尽量使用目标机器的特殊指令,提高机器代码的性能。
这样划分的好处:
这种设计简化了编译器的组成结构,降低了编译器的开发难度。编译开发者只需要知道如何将高级语言转换为优化器能够理解的中间代码即可,不需要精通优化器的工作原理和目标机器的体系结构。
当系统需要支持新的高级语言,只需要添加相应的编译器前端即可;
当系统需要支持心的目标机器,只需要添加相应的编译器后端即可;

IR(Intermediate Representation) 即中间表示,是用于表示中间代码的数据结构。设计IR的目的是保证编译器的跨平台,因此,去除了硬件平台相关的特性,对于不同的硬件平台,使用相同的IR表示,这位系统支持新语言或新硬件提供了便利
IR既是连接前端和后端的桥梁,又是前端和后端解耦合的工具。
优化器的转换和优化都是围绕IR实现的。
AI编译器又需要解决哪些问题呢?又是什么催生出了AI编译器呢?
先来看个图:
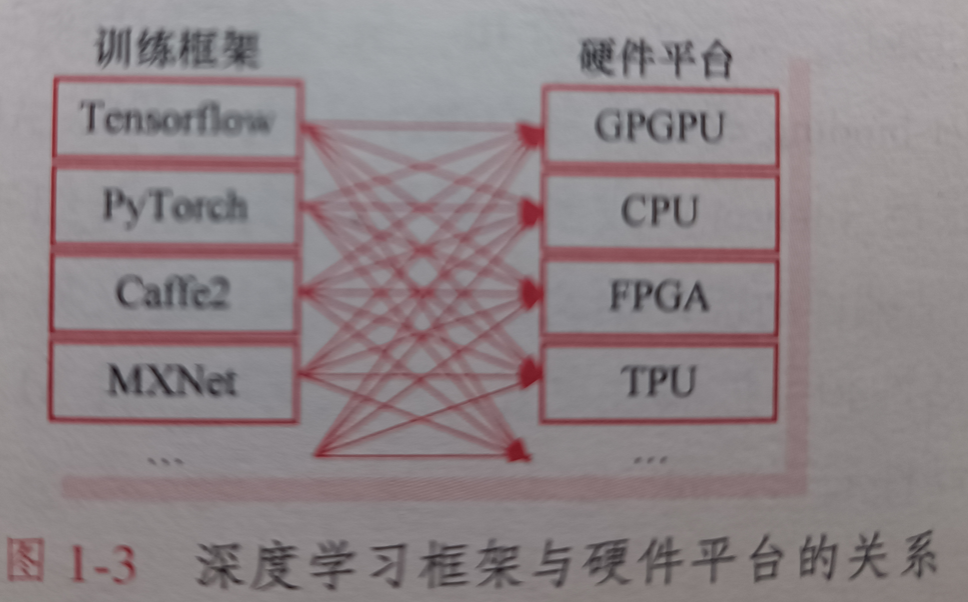
可以发现,训练框架众多,对应到的硬件平台众多,这就导致不同的深度学习框架训练出的模型不能通过某个工具转换生成可部署到不同硬件平台,对框架之间转换以及维护不同后端并保证所有硬件平台性能稳定都是一个巨大的挑战。
AI领域有众多的深度学习框架(Tensorflow、Pytorch等),由于前端接口和后端实现之间的差异,AI模型开发者常常面临从一个框架到另一个框架的巨大困难。
AI模型开发者希望,来自底层DSA(Domain Specific Architecture)改进带来的性能增益能在第一时间反应在模型性能的提升上
框架开发者也面临着同时维护多个后端并保证所有硬件平台性能的坚巨任务。
因此为了解决这些问题,提出了AI编译器,AI编译器的作用如下图:
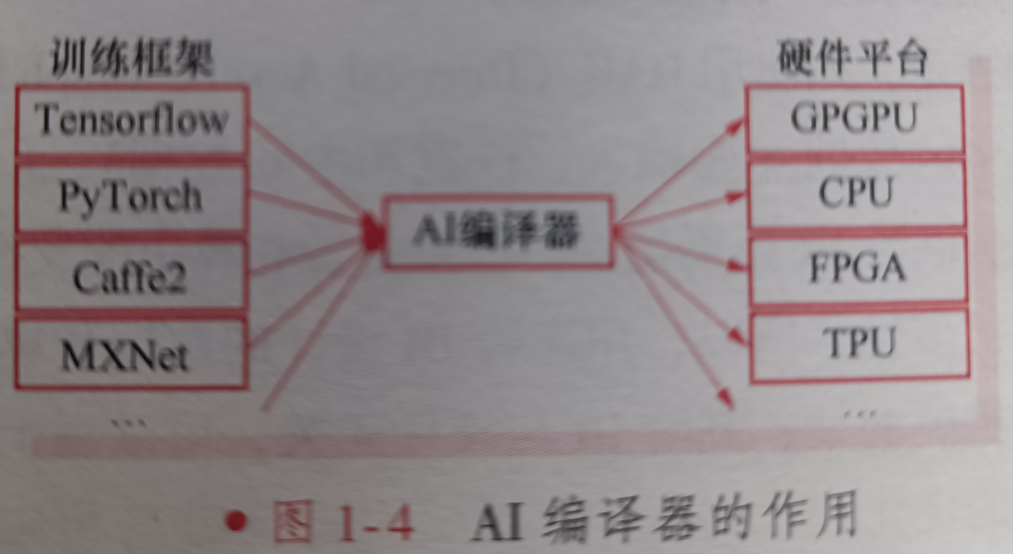
虽然AI编译器还处于发展阶段,还未形成通用的AI编译器技术框架,但通过分析,不难发现AI编译器的体系结构一般仍采用分层设计,作用和常规编译器相似,主要包括编译器前端、IR和编译器后端。
- 针对不同的模型规格和AI芯片体系结构,AI编译器对模型定义和特定代码实现之间的转换进行了高度优化。具体说就是,这些转化过程结合了面向深度学习的优化(如层和算子融合),从而实现了高效的代码生成。
- AI编译器还利用通用编译器(如LLVM)的成熟编译链,在各种AI芯片体系结构之间提供了更好的可移植性。
AI编译器结构如下:
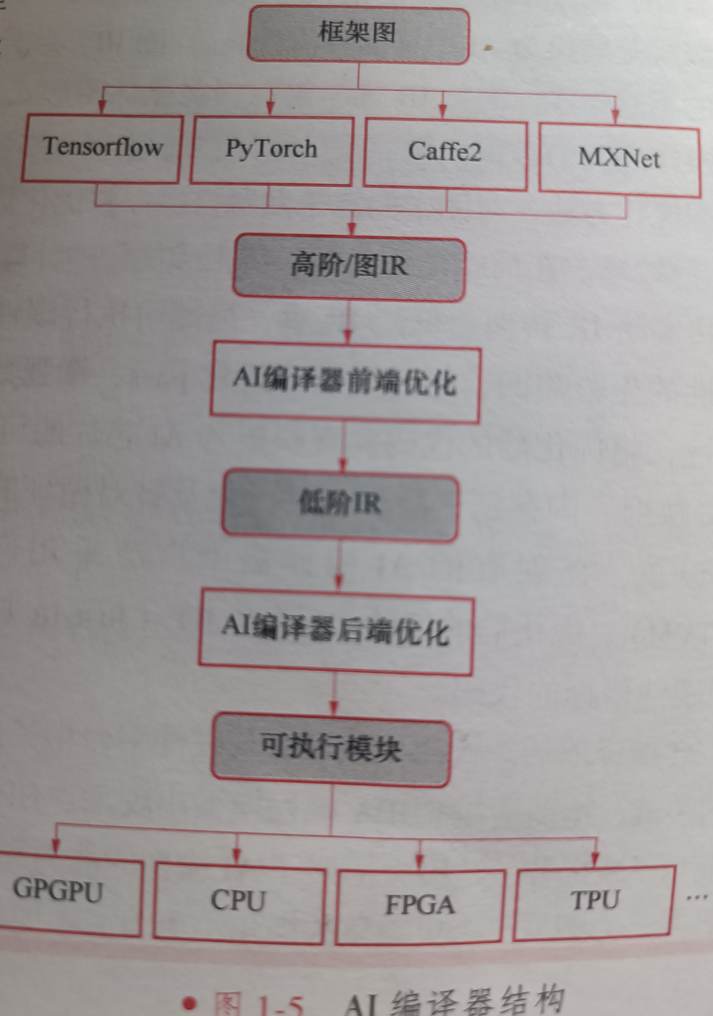
其中IR同样起到了连接前端和后端的作用。
通常,IR是程序的抽象,可用于程序优化。但,由于AI应用的特殊性,AI编译器不仅要解决跨平台问题,还要在兼顾专用架构设计特性的同时,解决深度学习网络本身的优化问题。所以,单层IR已经不能满足需求了。
因为单层IR很难从低阶IR中抽取AI模型的高阶概念,,并以此辅助后端优化。
例如,LLVM很难从低阶IR中的循环指令理解为卷积。
因此,在AI编译器中采用了多阶IR(multi-level IR)设计。多阶IR设计和针对AI模型的特定优化设计正是AI编译器的独特之处。
AI模型被AI编译器转换为多阶IR,其中的高阶IR服务于前端(执行硬件无关的转换和优化),低阶IR服务于后端(执行硬件相关的编译、优化和代码生成)
- 高阶IR,也成为图IR,可用于表示与硬件无关的计算和控制流程。
- 高阶IR的设计重点在于如何抽象计算和控制流,有了这种抽象能力,高阶IR就可以捕获和表达各种AI模型特性
- 高阶IR的目标是建立控制流及算子与数据之间的依赖关系,并为图优化提供接口,
- 完整的高阶IR,至少需要包括对计算图的表示,如使用DAG(Directed Acyclic Graph)和let-binding等形式来构建计算图。
- AI编译器中的数据(如输入、权重和中间数据)通常以张量(tensor)或 多维数组的形式进行组织。因此高阶IR还需要提供对数据张量和算子的支持,包括编译所需的语义信息,并为自定义算子提供可扩展性。
所以,用高阶IR设计的数据和算子灵活性和可扩展性更好,可以支持各种AI模型,更重要的是,高阶IR与硬件无关,可以用于各种硬件后端
低阶IR,主要设计用于各种硬件相关的优化和代码生成。因此,低阶IR应该注重设计细节,并以更细粒度的表示形式反应硬件特性,准确表示硬件相关的内存布局、并行化模式等优化选项。
此外,低阶IR还应该在编译器后端中兼容使用成熟的第三方工具链,利用已有编译器工具完成通用优化和代码生成,并将指令选择、寄存器分配等低级优化留给LLVM等下游编译器完成,重点关注下游编译器未涵盖的优化方法。
由上图AI编译器结构图可见,AI编译器的输入是来自深度学习框架的AI模型,针对AI模型的编译、优化过程大体分为两个阶段。第一个阶段是与硬件平台无关的前端优化,第二个阶段是与硬件平台相关的后端优化和代码生成。
第一阶段:
首先,前端从深度学习框架中获取AI模型作为输入,并通过模型导入接口,将深度神经网络的高级规范转换为AI编译器特有的高阶/图IR。此外,前端需要实现各种格式转换,以支持不同框架中的不同格式。高阶IR通常采用有向无环图形式。其中的每个节点代表一个计算操作,每条边代表操作之间的数据依赖关系。因此,前端可以在高阶IR上使用结合通用编译器优化和AI特定优化的图优化方法,对图中的算子做融合操作并与优化数据布局,以减少冗余计算和内存访问,提高高阶IR的效率。在前端优化之后,将生成优化的计算图。第二阶段:
将高阶IR转换为低阶IR,后端可执行硬件相关的后端优化。后端可以利用AI模型和硬件特性的先验只是,通过定制的优化pass,增强数据局部性,优化调度,并充分利用硬件平台的并行性,将优化后的代码实现映射为AI芯片的可执行指令。常见的硬件相关的优化包括硬件intrinsic映射、内存延迟隐藏、并行化及针对循环的优化等。为了在大型优化搜索空间中确定最佳参数设置,在现有的AI编译器中广泛采用自动调度(如多面体模型) 和自动调优(autoTVM)。优化后的低阶IR通过JIT(Just In Time)或AOT(Ahead Of Time)编译,生成针对不同硬件目标的代码。
------华丽的分割线------
终于,终于,对常规的编译器以及AI编译的介绍暂时告一段落,下面来进入主题 ---- TVM的整体架构
TVM的提出是为了解决深度学习框架和硬件后端适配的问题。
TVM是一个端到端的全栈编译器,包括统一的IR堆栈和自动代码生成方法,其主要功能是优化在CPU、GPU和其他定制AI芯片上执行的AI模型,通过自动转换计算图,实现计算模式的融合和内存利用率最大化,并优化数据布局,完成从计算图到算子级别的优化,提供从前端框架到AI芯片、端到端的编译优化。
通过TVM只需要花费少量工作即可在移动端、嵌入式设备上运行AI模型。
总览TVM系统结构图:
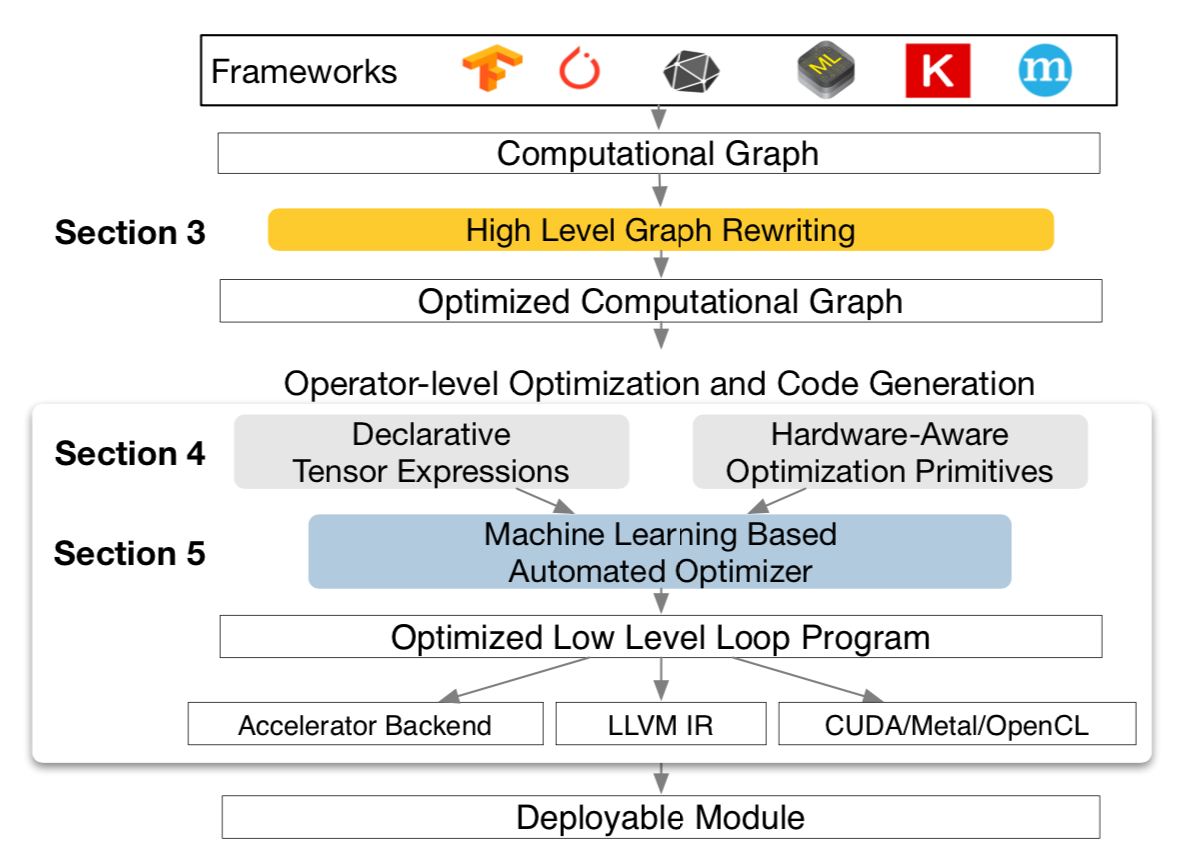
TVM以AI模型作为输入,首先将其转换为计算图,然后执行高级数据流重写,为计算图生成优化图。
算子级优化模块为优化图中的每个融合算子生成高效代码,并以声明式张量表达式指定算子。
TVM为给定硬件目标算子建立了可能的优化集合,这形成了巨大的搜索空间。因此,TVM使用机器学习的代价模型搜索优化算子。
最后,系统将生成的代码打包到可部署模块中。
AI编译器及TVM整体架构的更多相关文章
- 【AI编译器原理】系列来啦!我们要从入门到放弃!
随着深度学习的应用场景的不断泛化,深度学习计算任务也需要部署在不同的计算设备和硬件架构上:同时,实际部署或训练场景对性能往往也有着更为激进的要求,例如针对硬件特点定制计算代码. 这些需求在通用的AI框 ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- Mybatis技术内幕(一)——整体架构概览
Mybatis技术内幕(一)--整体架构概览 Mybatis的整体架构分为三层,分别是基础支持层.核心处理层和接口层. 如图所示: 一.基础支持层 基础支持层包含整个Mybatis的基础模块,这些模块 ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- Underscore 整体架构浅析
前言 终于,楼主的「Underscore 源码解读系列」underscore-analysis 即将进入尾声,关注下 timeline 会发现楼主最近加快了解读速度.十一月,多事之秋,最近好多事情搞的 ...
- jQuery 2.0.3 源码分析core - 整体架构
拜读一个开源框架,最想学到的就是设计的思想和实现的技巧. 废话不多说,jquery这么多年了分析都写烂了,老早以前就拜读过, 不过这几年都是做移动端,一直御用zepto, 最近抽出点时间把jquery ...
- [转]Android App整体架构设计的思考
1. 架构设计的目的 对程序进行架构设计的原因,归根到底是为了提高生产力.通过设计使程序模块化,做到模块内部的高聚合和模块之间的低耦合.这样做的好处是使得程序在开发的过程中,开发人员只需要专注于一点, ...
- jQuery整体架构源码解析(转载)
jQuery整体架构源码解析 最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性, ...
- 《深入理解bootstrap》读书笔记:第二章 整体架构
一. 整体架构 1. CSS-12栅格系统 把网页宽度均分为12等分(保留15位精度)--这是bootstrap的核心功能. 2.基础布局组件 包括排版.按钮.表格.布局.表单等等. 3.jQu ...
随机推荐
- Python实现URL自动转二维码的高效方法
Python实现URL自动转二维码的高效方法 安装包依赖 pip install qrcode pip install pillow 程序 import qrcode data = "htt ...
- Docker 安装详细步骤
一.安装前的准备 确认系统要求 不同的操作系统对 Docker 的支持有所不同,常见的如 Windows.MacOS 和各种 Linux 发行版. 启用虚拟化(如果需要) 对于某些系统,可能需要在 B ...
- DeepSeek 不太稳定?那就搭建自己的 DeepSeek 服务
概述 DeepSeek-R1 发布 DeepSeek 在 2025 年给我们送来一份惊喜,1 月 20 号正式发布第一代推理大模型 DeepSeek-R1.这个模型在数学推理.代码生成和复杂问题解决等 ...
- PHP中类和对象相关的函数
1.class_exists 用于判断一个类是否存在,参数为类名: 2.interface_exists 判断一个接口是否存在,参数为接口名: 3.method_exists 判断一个方法是否存在,参 ...
- Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
一:背景 1. 讲故事 前面跟大家分享过一篇 C# 调用 C代码引发非托管内存泄露 的文章,这是一个故意引发的正向泄露,这一篇我们从逆向的角度去洞察引发泄露的祸根代码,这东西如果在 windows 上 ...
- Landsat遥感影像分幅条带介绍与矢量下载:WRS的Path与Row
本文介绍Landsat系列卫星的分幅规则,并提供WRS的矢量文件下载. WRS,即Worldwide Reference System,是Landsat系列卫星全球影像标记符号系统,用以区分全 ...
- js回忆录(4) -- 对象,构造函数
1.对象 && 构造函数 js是一门基于对象的语言,里边所有的数据类型都可以当对象使唤(当然null和undefined除外),当我们在v8引擎里声明一个对象时会发现每个对象属性里边都 ...
- Detected non-NVML platform: could not load NVML: libnvidia-ml.so.1: cannot open shared object
前言 在 kubernetes 中配置 https://github.com/NVIDIA/k8s-device-plugin 时, 报错:Detected non-NVML platform: co ...
- bee must have one register DataBase alias named `default`
bee must have one register DataBase alias named default 在你初始化db,注册默认数据库时,看看你是否import初始化注册数据库驱动driver ...
- git 访问方式浅谈
小小总结下git的访问方式,留爪. git访问方式简介 https:每次fetch/push/pull都需要输入username & password ssh:通过ssh-keygen生成的公 ...