rpc项目中的长连接与短连接的思考
对于rpc项目,在接受大佬指导的时候曾问过对于长连接和短连接是处理处理的,在面试的时候也被问起socket是长连接还是短连接,发现自己没有好好思考过这个问题,因此好好总结一下。
前置知识点:rpc基础,tcp基础
rpc项目中的长连接与短连接的思考
什么是rpc项目中的长连接和短连接
类似于http的长连接和短连接的概念,rpc项目中的短连接是指处理完一次rpc请求后就断开连接,长连接是指处理完一次rpc请求后不断开连接,复用连接。
http中长连接是指处理完一次http请求和响应之后不断开tcp连接,http短连接是指处理完一次http请求和响应之后断开tcp连接(一般是服务器断开,至于为什么是服务器断开,则又是一篇小文章了hhh)。
与tcp和http的长连接短连接的异同
对于rpc和http的长短连接上文已经分析过了(毕竟有的rpc框架底层的传输协议甚至都是http),这里主要要区别的就是** http**和**rpc**的长短连接本质上就是控制的**tcp**的断开时机。
这里又涉及一个平时很容易弄错的地方了,比如tcp的包活机制(keep-aliving)与http协议的长连接(Connection: Keep-Alive)英文很相似,但是本质上不是一个东西。
客户端与服务器有哪几种连接模式与利弊分析
rpc连接的三种方式:
常规 RPC 的连接模型主要有三种:
- 短连接:每次请求都创建新连接,得到返回后立即关闭连接
- 长连接池:单个连接同时只能处理一次完整请求与返回
- 连接多路复用:单个连接可以同时异步处理多个请求与返回
每类连接模型没有绝对好坏,取决于实际使用场景,连接多路复用虽然一般来说性能相对最好。
这些应该是一些比较成熟的rpc框架实现的,中间配有负载均衡器才能实现连接池的操作。
如果是客户端与服务端直连,本质上就是两种:长连接和短连接。
长连接不是银弹
本节主要说明长连接虽然相对于短连接一般情况下性能好,但是不是十全十美,必须有所考量。
1. client 和 server 的数量
rpc长连接模式下相比于rpc短连接,在相同client数量的情况下,需要维系的连接数更多(连接一般不会断开,或者是需要超时或者是其他情况才会断开),因此当client数量相比于server数量过多的时候,使用长连接会有以下几个问题:
server需要维护数量众多的连接,压力很大。- 端口很容易耗尽
因此在client数量特别多的情况下就不适合用长连接了,用短连接反而合适一些。
使用长连接的时候也需要考虑超时断开等机制。
所幸rpc服务器一般来说client的数量相比于网页服务器等会少很多,因此使用长连接应该就可以了。
可以考虑一篇新文章,服务器端口用尽怎么办:
2. 负载均衡机制
现代后端服务端架构中, 为了实现高可用和可伸缩, 一般都会引入单独的模块来提供负载均衡的功能, 称为负载均衡器。根据工作在 OSI 不同的层级, 不同的负载均衡器会提供不同的转发功能。不同的均衡器是根据工作在的 层进行区分的,接下来就最常见的 L4 (工作在 TCP 层)和** L7** (工作在应用层, 如 HTTP) 两种负载均衡器来分析。
我的rpc项目没有实现单独模块的负载均衡,而是直接在客户端实现负载均衡的,因此下面的这些只是一些设计上的学习。
L4 负载均衡器
L4工作在TCP层,就是对TCP的流量进行负载均衡的转发,由于TCP的特性,因此L4的负载均衡器并不能知道某次rpc请求是否处理完毕,只是在发起请求的时候进行负载均衡处理(选择要转发到哪个服务器上)。
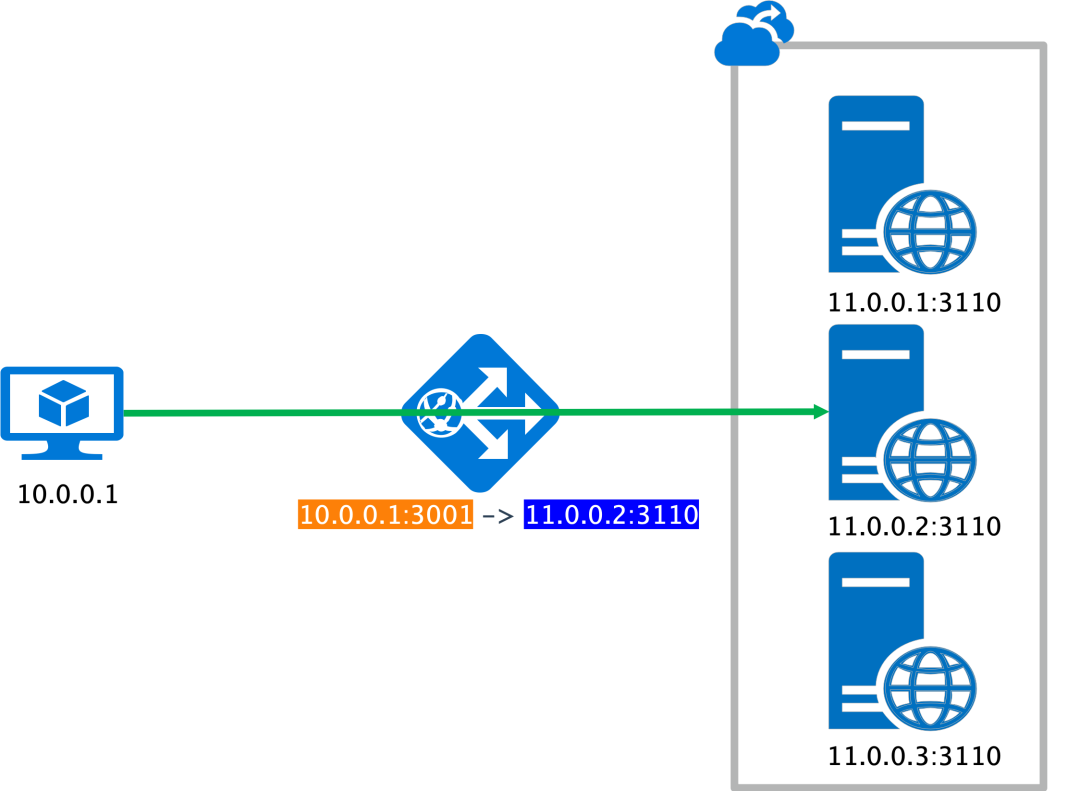
那么这样和RPC长短连接有什么关系呢?
- 长连接:长连接情况下
client会一直保持和某个server的连接,这样的话在某种意义上来说负载均衡就失效了。之所以说是某种意义上失效,是因为**client**的请求一直在某一台服务器上,并没有均衡到其他服务器,但是新的**client**连接进来的时候还是会负载均衡的。这样在client数量很少的时候会导致流量分发不平均: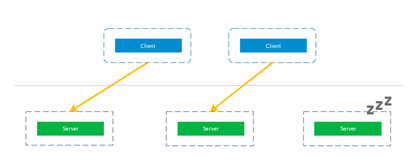
- 短连接:每次请求都会重新连接,因此每次都会负载均衡。
L7 负载均衡器
L7均衡器无论是长连接还是短连接都不会有L4在长连接情况下的负载均衡的问题,原因是因为L7可以进行HTTP协议的解析。
L4负载均衡在长连接情况下导致负载均衡在某种意义下失效的本质原因是负载均衡器在第一次连接的时候负载均衡后,后续不会再负载均衡了。
相比 L4 只能基于连接进行负载均衡, L7 可以进行 **HTTP** 协议的解析.。当 client 发送请求时, client 会先和 L7 握手, L7 再和后端的一个或几个 server 握手,并根据不同的策略将请求分发给这些 server,实现基于请求的负载均衡。
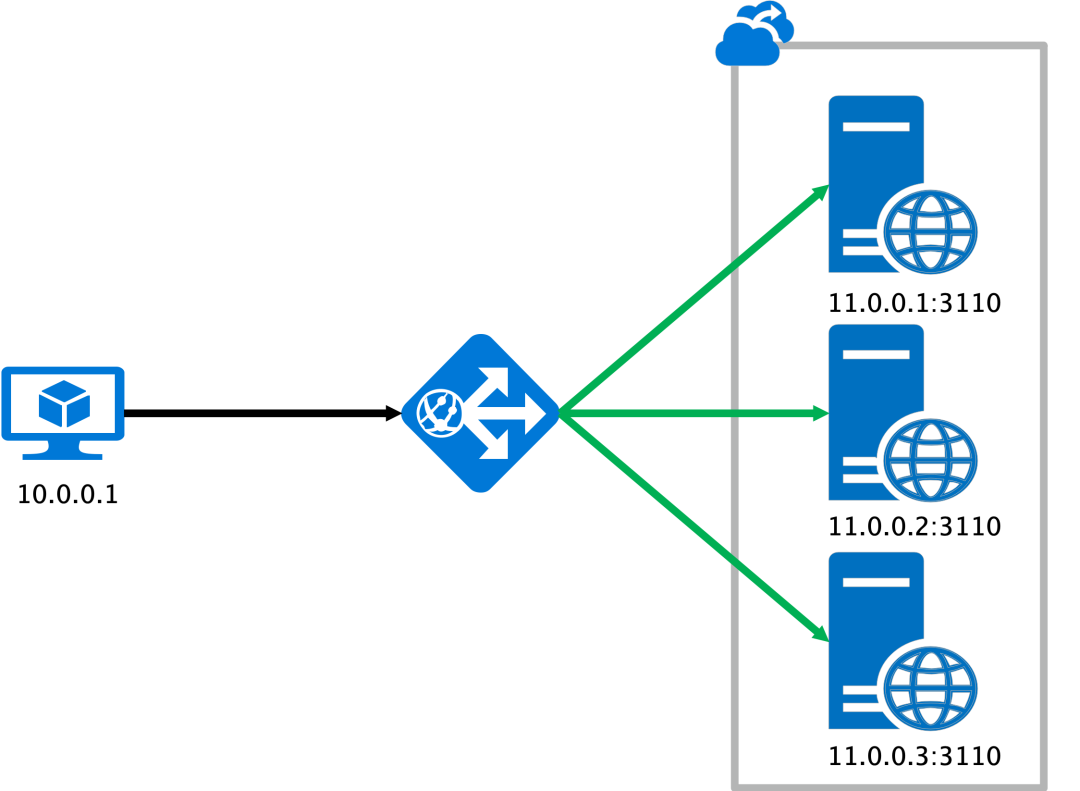
可以看到L7的负载均衡无论是长连接还是短连接都没有负载均衡“失效”的问题,因为L7的负载均衡器是可以读取到请求的具体内容的。
因此使用长连接还是短连接必须要根据实际情况来确定,不能无脑的选择长连接。
如何实现长连接
rpc服务提供方和调用方只要在处理完之后不要断开连接就可以了。在检测到对方断开后也要断开。
// 新的socket连接回调
void RpcProvider::OnConnection(const muduo::net::TcpConnectionPtr &conn)
{
// 如果是新连接就什么都不干,即正常的接收连接即可
if (!conn->connected())
{
// 和rpc client的连接断开了
conn->shutdown();
}
}
/*
在框架内部,RpcProvider和RpcConsumer协商好之间通信用的protobuf数据类型
service_name method_name args 定义proto的message类型,进行数据头的序列化和反序列化
service_name method_name args_size
16UserServiceLoginzhang san123456
header_size(4个字节) + header_str + args_str
10 "10"
10000 "1000000"
std::string insert和copy方法
*/
// 已建立连接用户的读写事件回调 如果远程有一个rpc服务的调用请求,那么OnMessage方法就会响应
// 这里来的肯定是一个远程调用请求
// 因此本函数需要:解析请求,根据服务名,方法名,参数,来调用service的来callmethod来调用本地的业务
void RpcProvider::OnMessage(const muduo::net::TcpConnectionPtr &conn,
muduo::net::Buffer *buffer,
muduo::Timestamp)
{
// 网络上接收的远程rpc调用请求的字符流 Login args
std::string recv_buf = buffer->retrieveAllAsString();
// 从字符流中读取前4个字节的内容
uint32_t header_size = 0;
recv_buf.copy((char *)&header_size, 4, 0);
// 根据header_size读取数据头的原始字符流,反序列化数据,得到rpc请求的详细信息
std::string rpc_header_str = recv_buf.substr(4, header_size);
mprpc::RpcHeader rpcHeader;
std::string service_name;
std::string method_name;
uint32_t args_size;
if (rpcHeader.ParseFromString(rpc_header_str))
{
// 数据头反序列化成功
service_name = rpcHeader.service_name();
method_name = rpcHeader.method_name();
args_size = rpcHeader.args_size();
}
else
{
// 数据头反序列化失败
std::cout << "rpc_header_str:" << rpc_header_str << " parse error!" << std::endl;
return;
}
// 获取rpc方法参数的字符流数据
std::string args_str = recv_buf.substr(4 + header_size, args_size);
// 打印调试信息
std::cout << "============================================" << std::endl;
std::cout << "header_size: " << header_size << std::endl;
std::cout << "rpc_header_str: " << rpc_header_str << std::endl;
std::cout << "service_name: " << service_name << std::endl;
std::cout << "method_name: " << method_name << std::endl;
std::cout << "args_str: " << args_str << std::endl;
std::cout << "============================================" << std::endl;
// 获取service对象和method对象
auto it = m_serviceMap.find(service_name);
if (it == m_serviceMap.end())
{
std::cout << service_name << " is not exist!" << std::endl;
return;
}
auto mit = it->second.m_methodMap.find(method_name);
if (mit == it->second.m_methodMap.end())
{
std::cout << service_name << ":" << method_name << " is not exist!" << std::endl;
return;
}
google::protobuf::Service *service = it->second.m_service; // 获取service对象 new UserService
const google::protobuf::MethodDescriptor *method = mit->second; // 获取method对象 Login
// 生成rpc方法调用的请求request和响应response参数
google::protobuf::Message *request = service->GetRequestPrototype(method).New();
if (!request->ParseFromString(args_str))
{
std::cout << "request parse error, content:" << args_str << std::endl;
return;
}
google::protobuf::Message *response = service->GetResponsePrototype(method).New();
// 给下面的method方法的调用,绑定一个Closure的回调函数
// closure是执行完本地方法之后会发生的回调,因此需要完成序列化和反向发送请求的操作
google::protobuf::Closure *done = google::protobuf::NewCallback<RpcProvider,
const muduo::net::TcpConnectionPtr &,
google::protobuf::Message *>(this,
&RpcProvider::SendRpcResponse,
conn, response);
// 在框架上根据远端rpc请求,调用当前rpc节点上发布的方法
// new UserService().Login(controller, request, response, done)
/*
为什么下面这个service->CallMethod 要这么写?或者说为什么这么写就可以直接调用远程业务方法了
这个service在运行的时候会是注册的service
// 用户注册的service类 继承 .protoc生成的serviceRpc类 继承 google::protobuf::Service
// 用户注册的service类里面没有重写CallMethod方法,是 .protoc生成的serviceRpc类 里面重写了google::protobuf::Service中
的纯虚函数CallMethod,而 .protoc生成的serviceRpc类 会根据传入参数自动调取 生成的xx方法(如Login方法),
由于xx方法被 用户注册的service类 重写了,因此这个方法运行的时候会调用 用户注册的service类 的xx方法
真的是妙呀
*/
service->CallMethod(method, nullptr, request, response, done);
}
rpc服务提供方
如上,不要断开连接即可,然后要记得保存socket对应的fd(文件描述符),因为下次要复用。
rpc请求方
while (m_clientFd == -1)
{ // 没有连接或者连接已经断开,那么就要重新连接呢,会一直不断地重试
xxx
}
当不能正常发送、接受、第一次连接的时候,总而言之就是异常的情况下:m_clientFd==-1,此时会从哈希环中分配尝试一个节点。
写成while是因为可能由于服务下线zookeeper没有及时检测到(zk检测是用心跳,默认是30s),那么连接肯定会失败,此时就会又从哈希环分配其他节点上面,以保证正确的连接。
一些其他层面的优化
其他层面的优化即对socket tcp编程的优化
TCP_NODELAY:禁用Nagle算法,使小数据包能够及时发送。TCP_QUICKACK:启用quickack模式,减少应答延迟。
面试相关
这部分没有知识点,只是假设面试场景。
问:你这边对rpc的长连接和短连接是怎么思考的?
答:我的项目中采用的是长连接。
具体来说,rpc连接类似于HTTP连接,按照对每次响应处理后TCP是否断开分成了长连接和短连接,更具体的还可以分成:短连接,长连接池等等,但是本质上都是长连接和短连接之争。
长连接相比于短连接,在每次处理请求的时候不用重新握手了,对于数量多、体积小、处理快的请求很适用(速度快),但是使用的时候也必须有一些考量,不能无脑的选择长连接,具体来说有两点:
- 服务器和客户端的数量(连接数量):由于使用长连接,端口资源不会马上释放,因此client数量特别多的时候容易导致端口耗尽,考虑到一台服务器大概率不会维护那么多的client,因此使用长连接也是可行的。
- 负载均衡策略:如果是L4的负载均衡器的话有可能导致负载均衡策略在某种意义下失效。但我在项目中是直接在客户端部分实现的一致性hash算法用于负载均衡,并没有外置负载均衡器,是在客户端实现的负载均衡压根没有负载均衡器,因此自然不会收到负载均衡策略的影响。
综上使用的就是长连接了,此外:在长连接中加入了定时器,类似于web 服务器的设计,用来断开长时间没有请求的连接数量,用来缓解端口资源;进行了TCP的一些参数设置,NO_DELAY和QUICK_ACK来加快响应。
本文由博客一文多发平台 OpenWrite 发布!
rpc项目中的长连接与短连接的思考的更多相关文章
- 误人子弟的网络,谈谈HTTP协议中的短轮询、长轮询、长连接和短连接
引言 最近刚到公司不到一个月,正处于熟悉项目和源码的阶段,因此最近经常会看一些源码.在研究一个项目的时候,源码里面用到了HTTP的长轮询.由于之前没太接触过,因此LZ便趁着这个机会,好好了解了一下HT ...
- HTTP协议中的短轮询、长轮询、长连接和短连接
HTTP协议中的短轮询.长轮询.长连接和短连接 引言 最近刚到公司不到一个月,正处于熟悉项目和源码的阶段,因此最近经常会看一些源码.在研究一个项目的时候,源码里面用到了HTTP的长轮询.由于之前没太接 ...
- 转---谈谈HTTP协议中的短轮询、长轮询、长连接和短连接
作者:伯乐在线专栏作者 - 左潇龙 http://web.jobbole.com/85541/ 如有好文章投稿,请点击 → 这里了解详情 引言 最近刚到公司不到一个月,正处于熟悉项目和源码的阶段,因此 ...
- 谈谈HTTP协议中的短轮询、长轮询、长连接和短连接
引言 最近刚到公司不到一个月,正处于熟悉项目和源码的阶段,因此最近经常会看一些源码.在研究一个项目的时候,源码里面用到了HTTP的长轮询.由于之前没太接触过,因此LZ便趁着这个机会,好好了解了一下HT ...
- 【转】HTTP中的长连接和短连接分析
1. HTTP协议与TCP/IP协议的关系 HTTP的长连接和短连接本质上是TCP长连接和短连接.HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议.IP协议主要解决网络路由和寻址问 ...
- HTTP协议中的短轮询、长轮询、长连接和短连接,看到一篇文章有感
关于短轮询.长轮询 短轮询主要是前端实现,JS写个死循环,不停的去请求服务器中的库存量是多少,然后刷新到这个页面当中,这其实就是所谓的短轮询. 长轮询主要取决于服务器,在长轮询中,服务器如果检测到数据 ...
- HTTP协议中的长连接、短连接、长轮询、短轮询
长连接.短连接,指的是TCP连接.长连接是为了复用TCP连接. 长轮询中,服务器如果检测到库存量没有变化的话,将会把当前请求挂起一段时间(这个时间也叫作超时时间,一般是几十秒).在这个时间里,服务器会 ...
- TCP中的长连接和短连接(转载)
原文地址:http://www.cnblogs.com/onlysun/p/4520553.html 次挥手,所以说每个连接的建立都是需要资源消耗和时间消耗的 示意图: ...
- Swoole 中 TCP、UDP 和长连接、短连接
TCP 服务 swoole 文档 - TCP 服务 tcp 服务端 <?php // 1. 创建 swoole 默认创建的是一个同步的阻塞tcp服务 $host = "0.0.0.0& ...
- TCP同步与异步,长连接与短连接【转载】
原文地址:TCP同步与异步,长连接与短连接作者:1984346023 [转载说明:http://zjj1211.blog.51cto.com/1812544/373896 这是今天看到的一篇讲到T ...
随机推荐
- flask+APScheduler定时任务的使用
目录 APScheduler简介 安装 add_job参数详解 结合flask使用 用uwsgi启动项目 用gunicorn+gevent启动flask项目 APScheduler简介 APSched ...
- 2013年ImportNew最受欢迎的10篇文章
2013年即将过去,提前祝大家元旦快乐,ImportNew 整理出了本年度最受欢迎的前10篇Java和Android技术文章,每篇文章仅添加了摘要.如果您是我们的新访客,那下面这些文章不能错过.如果您 ...
- linux故障排查工具之dmesg
dmesg命令是用来在Unix-like系统中显示内核的相关信息的.dmesg全称是display message (or display driver),即显示信息. 实际上,dmesg命令是从内核 ...
- .NET静态代码编织——肉夹馍(Rougamo)5.0
肉夹馍(https://github.com/inversionhourglass/Rougamo),一款编译时AOP组件.相比动态代理AOP需要在应用启动时进行初始化,编译时完成代码编织的肉夹馍减少 ...
- oracle查询某个sql语句客户端ip地址
1. 背景 业务出现异常后,或者某个sql导致系统卡顿.需要问题后需要溯源,需要获取这个sql是在哪个客户端的IP发起的. 2. cs架构 客户端直接连接数据库,可以很方便查询,采用通过sql_id找 ...
- js面试题-代码实现
新 API 最新的 url 参数获取的 API? URLSearchParams // 有如下一个url: http://localhost?a=1&b=2 function getUrlPa ...
- [WPF UI] 为 AvalonDock 制作一套 Fluent UI 主题
AvalonDock 是我这些天在为自己项目做技术选型时发现的一个很好的开源项目,它是一个用于 WPF 的布局控件库,可以帮助我们实现类似 Visual Studio 的布局效果.因为它自带的一些样式 ...
- 【Javaweb】JSP标准标签库
目录 JSTL 1.什么是JSTL 2.版本 3.标签函数库 4.优点 JSTL基本概念 标签(Tag) 标签库(Tag library) 标签库描述文件(Tag Library Descriptor ...
- Qt编写地图综合应用39-覆盖物圆形
一.前言 圆形的应用场景和多边形.矩形基本一致,支持的属性也是一致,比如可以设置线条的颜色.线条的粗细.线条透明度等.也是用来框起一块区域,然后根据坐标点集合,找到该区域内的标注点集合,比如指定某个县 ...
- Datawhale 2025冬令营“嬛嬛,我来啦!”😘
Datawhale2025冬令营 Datawhale 2025 AI冬令营链接:https://www.datawhale.cn/activity/110/21/76?rankingPage=1 赠送 ...