抽丝剥茧--从零开始建设k8s监控之水平拆分(五)
前言
书接上文,经过之前的不懈努力,我们已经有了较为完善的监控系统与告警系统,而prometheus的工作模式就像一个单点,拉取数据回来之后存储在自己的磁盘上
当监控数据越来越多,那prometheus单点的压力就会变大,那本文就来讨论一下如何降低单点prometheus的压力
环境准备
| 组件 | 版本 |
|---|---|
| 操作系统 | Ubuntu 22.04.4 LTS |
| docker | 24.0.7 |
| kube-state-metrics | v2.13.0 |
| thanos | 0.36.1 |
水平拆分
水平拆分的目的就是为了拆成多个prometheus,让单个prometheus负载降低,不要这么容易挂掉,并且拆成多个之后,就算挂掉一个,其余的也可以正常工作。比如一个prometheus专门负责节点监控数据采集、一个prometheus专门负责k8s监控数据采集等
1. 根据采集的目标进行拆分
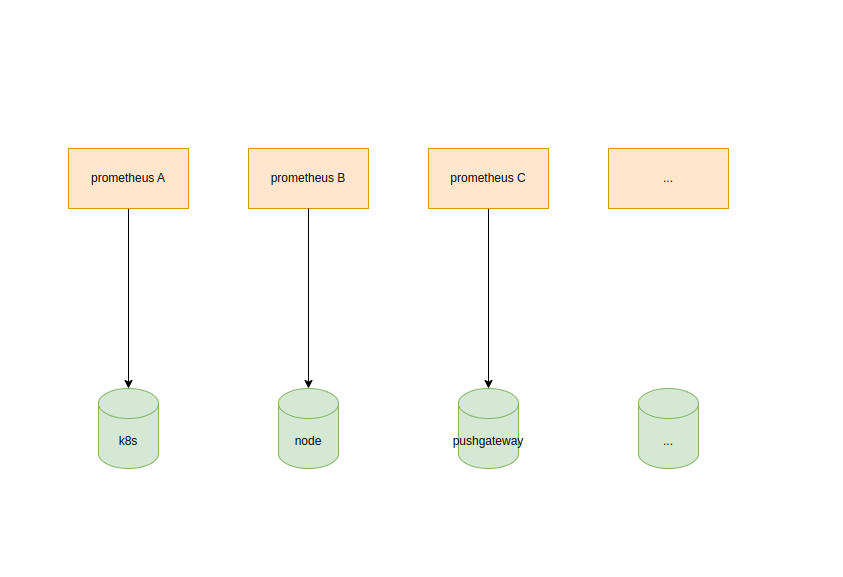
每个业务都有一个prometheus对其进行采集,并且不同prometheus之间解耦
这时候业务部门提出需求,k8s的监控还是太多了,一个prometheus依然不堪重负,那怎么办呢?
2. kube-state-metrics拆分
由于k8s是通过kube-state-metrics这个exporter进行采集,所以我们需要对其进行拆分
2.1 根据namespace进行拆分
这个拆分是显而易见的,不同的namespace采集进入不同的prometheus即可,配置也很简单,只需要修改kube-state-metrics的启动参数即可
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- args:
- --metric-labels-allowlist=pods=[*]
- --metric-annotations-allowlist=pods=[*]
- --namespaces=default # 新增
name: kube-state-metrics
image: registry.cn-beijing.aliyuncs.com/wilsonchai/kube-state-metrics:v2.13.0
ports:
- containerPort: 8080
--namespaces=default 告诉kube-state-metrics只采集namespace为default的数据
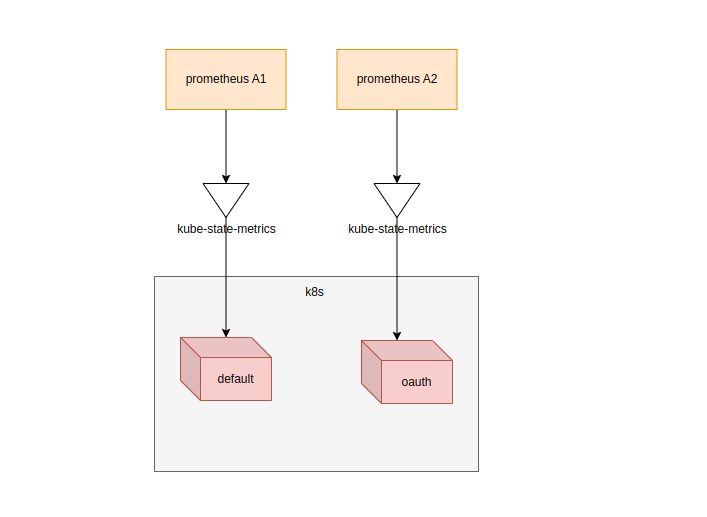
创建多个prometheus以及kube-state-metrics,然后指定采集不同的namespace
这种方法配置简单,但是分配多个kube-state-metrics的采集策略就比较复杂,一旦业务复杂,namespace多起来之后,也会造成频繁修改配置,还有没有更简单的方法呢?
2.2 kube-state-metrics根据shard拆分
在kube-state-metrics的高版本(具体是哪个版本待查,笔者的版本是v2.13.0),支持了自动分片的采集策略,就是让多个kube-state-metrics自己去分片,省去人为配置的烦恼
关于水平分片的例子,可以参考 kube-state-metrics
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
name: kube-state-metrics
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- apps
resourceNames:
- kube-state-metrics
resources:
- statefulsets
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
name: kube-state-metrics
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
serviceName: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v2.13.0
spec:
containers:
- args:
- --pod=$(POD_NAME)
- --pod-namespace=$(POD_NAMESPACE)
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: registry.cn-beijing.aliyuncs.com/wilsonchai/kube-state-metrics:v2.13.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
securityContext:
runAsUser: 65534
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metrics
启动起来之后检查一下metrics的指标数量
curl -s 10.244.0.107:8080/metrics | wc -l
949
curl -s 10.244.0.108:8080/metrics | wc -l
909
看起来已经打散到2个节点去了,如果我再增加一个节点,那指标数量又分散了
curl -s 10.244.0.107:8080/metrics | wc -l
702
curl -s 10.244.0.108:8080/metrics | wc -l
733
curl -s 10.244.0.109:8080/metrics | wc -l
663
这时候只需要把不同的prometheus配置采集不同kube-state-metrics即可,架构也变成了这个样子
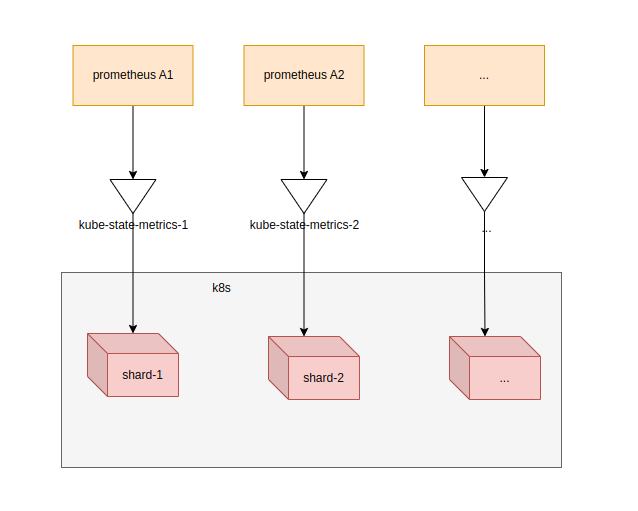
当然kube-state-metrics也是有手动分片模式的,就是通过参数--shard来实现了,只不过有自动分片的话,没有极致特殊的需求,我们还是用自动分片来处理更加合适
多prometheus数据汇聚
当我们拆分了监控数据,用不同的prometheus来采集的时候,又带来了新的问题
- 由于prometheus使用本地磁盘存储数据,所以通过prometheus的web界面查看监控数据时,也只能查看到本prometheus的监控数据,不能跨prometheus查询监控数据
- 使用grafana添加数据源的时候,就出现了多prometheus数据源的情况,造成管理复杂
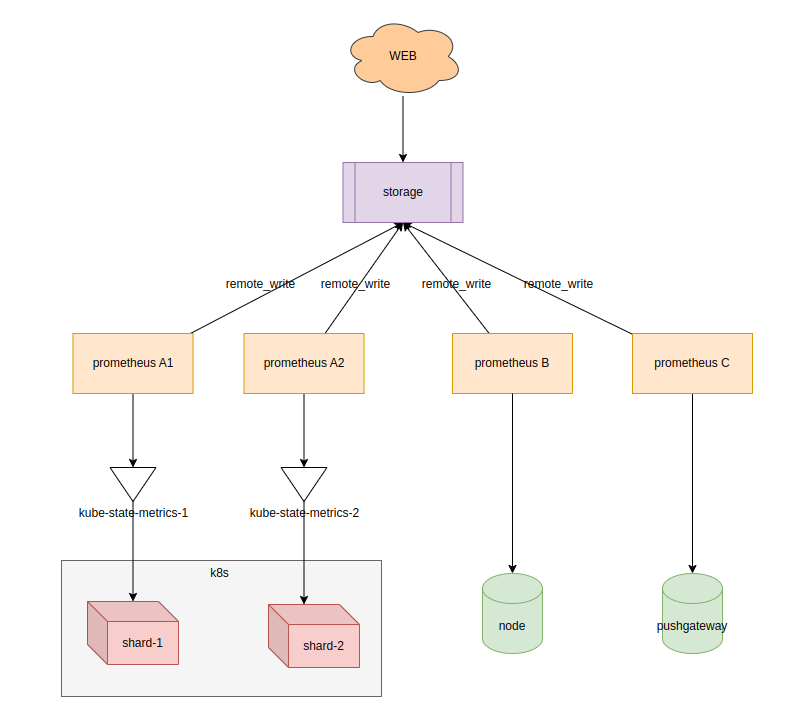
- 有一个公共的storage组件,prometheus通过remote_write的方式,把数据汇聚在这个组件,就可以解决数据分散的问题,并且数据存储的方式就很灵活了,可以存储在本地,然后通过传统的raid做数据备份,也可以直接通过云 平台的对象存储保存历史数据
- 最后再来一个统一的web界面进行查询,同时这个web界面兼容了prometheus的promQL,并且兼容了prometheus的api,可以直接作为数据源添加至grafana中
- 有这种功能的组件就很多了,比如thanos、cortext、influxDB等等,都可以完成这个工作
小结
- 下一小节,通过thanos来详细讨论一下怎么做数据汇聚
联系我
- 联系我,做深入的交流

至此,本文结束
在下才疏学浅,有撒汤漏水的,请各位不吝赐教...
抽丝剥茧--从零开始建设k8s监控之水平拆分(五)的更多相关文章
- [转帖]从零开始入门 K8s | 手把手带你理解 etcd
从零开始入门 K8s | 手把手带你理解 etcd https://zhuanlan.zhihu.com/p/96721097 导读:etcd 是用于共享配置和服务发现的分布式.一致性的 KV 存储系 ...
- [转帖]从零开始入门 K8s:应用编排与管理:Job & DaemonSet
从零开始入门 K8s:应用编排与管理:Job & DaemonSet https://www.infoq.cn/article/KceOuuS7somCYbfuykRG 陈显鹭 阅读数:193 ...
- mysql水平拆分与垂直拆分的详细介绍(转载http://www.cnblogs.com/nixi8/p/4524082.html)
垂直 垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表 通常我们按以下原则进行垂直拆分: 把不常用的字段单独放在一张表; 把text,blob等大字段拆分出来放在附表中; 经常组合查询的 ...
- 【mysql的设计与优化专题(4)】表的垂直拆分和水平拆分
垂直拆分 垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表 通常我们按以下原则进行垂直拆分: 把不常用的字段单独放在一张表; 把text,blob等大字段拆分出来放在附表中; 经常组合查询的 ...
- 数据库水平拆分和垂直拆分区别(以mysql为例)
数据库水平拆分和垂直拆分区别(以mysql为例) 数据库水平拆分和垂直拆分区别(以mysql为例) 案例: 简单购物系统暂设涉及如下表: 1.产品表(数据量10w,稳定) 2.订单表(数据 ...
- MySQL 水平拆分(读书笔记整理)
转:http://blog.csdn.net/mchdba/article/details/46278687 1,水平拆分的介绍 一般来说,简单的水平切分主要是将某个访问极其平凡的表再按照某个字段的某 ...
- mysql的水平拆分和垂直拆分
转:http://www.cnblogs.com/sns007/p/5790838.html 1,水平分割: 例:QQ的登录表.假设QQ的用户有100亿,如果只有一张表,每个用户登录的时候数据库都要从 ...
- MySQL 水平拆分与垂直拆分详解
前言:说到优化mysql,总会有这么个回答:水平拆分,垂直拆分,那么我们就来说说什么是水平拆分,垂直拆分. 一.垂直拆分 说明:一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将 ...
- MYSQL水平拆分与垂直拆分
目前很多互联网系统都存在单表数据量过大的问题,这就降低了查询速度,影响了客户体验.为了提高查询速度,我们可以优化sql语句,优化表结构和索引,不过对那些百万级千万级的数据库表,即便是优化过后,查询速度 ...
- 数据拆分之 垂直拆分 and 水平拆分
https://mp.weixin.qq.com/s?__biz=MzI1NDQ3MjQxNA==&mid=2247488833&idx=1&sn=4f5fe577521431 ...
随机推荐
- 设计即合规: 开放AI生态中的用户数据治理实践
Hugging Face Hub 已成为 AI 协作的核心平台,托管了数万个模型.数据集以及交互式应用程序 (Space). 在开放生态系统中,用户知情同意的管理方式与那些更 "数据饥渴&q ...
- SpringCloud——自定义断言工厂
目录 场景:用户的请求头中需要有指定的用户名和密码才能访问. 断言工厂 参考系统AfterRoutePredicateFactory写法. package com.zjw.factory; impor ...
- Coze 初体验之打造专属的编程助手
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- TVM:Object家族
Object.h概述 命名空间: TVM::runtime 文件中包含的结构: 1.结构体TypeIndex 2.类Object 3.类ObjectPtr 4.类ObjectRef 5.结构体Obje ...
- C#之Bitmap
SetPixel和GetPixel private void btnC_Click(object sender, RoutedEventArgs e) { OpenFileDialog dia = n ...
- 【晴神宝典刷题路】codeup+pat 题解索引(更新ing
记录一下每天的成果,看多久能刷完伐 c2 c/c++快速入门 <算法笔记>2.3小节--C/C++快速入门->选择结构 习题4-10-1 奖金计算 <算法笔记>2.4小节 ...
- Everyone's Favorite Linear, Direct Access, Homogeneous Data Structure: The Array(英翻中)
Arrays are one of the simplest and most widely used data structures in computer programs. Arrays in ...
- 企业AI应用模式解析:从本地部署到混合架构
在人工智能快速发展的今天,企业如何选择合适的大模型应用方式成为了一个关键问题.本文将详细介绍六种主流的企业AI应用模式,帮助您根据自身需求做出最优选择. 1. 本地部署(On-Premise Depl ...
- 阿里二面:main 方法可以被继承吗|转
摘要:java中,main方法可以被重载,可以被调用,可以被继承,可以被重写. 目录 main 函数介绍 main方法能被重载 main方法能被其它方法调用 main方法能被继承 结束语 Refere ...
- 记录第一次公司内部分享:如何基于大模型搭建企业+AI业务
Hello, 大家好,我是程序员海军, 全栈开发 |AI爱好者 | 独立开发. 记录第一次在公司内部分享AI+业务 落地实践. 如今,AI时代带来的无限可能性,很多业务都值得从做一遍. 最近,老大参加 ...