Shell文本处理四剑客
5.1 【grep】
全面搜索正则表达式(GREP)是一种强大的文本搜索工具,能使用正则 表达式搜索文本,并把匹配的行打印出来
过滤来自一个文件或标准输入匹配模式内容
除了grep外,还有egrep,fgrep,egrep是grep的扩展,相当于grep -E ,fgrep下相当于grep -f,用的较少
文件的正则 描述
-E,--extended-regexp 模式是扩展正则表达式
-P,perl-regexp 模式是perl正则表达式
-e,regexp=PATHERN 使用模式匹配,可指定多个模式匹配
-f,--file=FILE 从文件每一行获取匹配模式
-i,--ignore-ease 忽略大小写
-w,word-regexp 模式匹配
-x,--line-regexp 模式匹配
整行
-v,--invert-math 打印不匹配的行
输出控制 描述
-m,--max-count=NUM 输出匹配的结果num
-n,--line-number 打印行号
-H,--with-filename 打印每个匹配的文件名
-h, --no-filename 不输出文件名
-o,--only-matching 只打印匹配的内容
-q,--quit 不输出正常信息
-s,--no-messages 不输出错误信息
-r,--recursive 递归目录
-c,--count 只打印每个文件匹配的行数
内容行控制 描述
-B,--berfore-context=NUM 打印匹配的前几行
-A,--after-context=NUM 打印匹配的后几行
-C,--contect=NUM 打印那匹配的前后几行
示例:
1)输出1.sh和2.sh相同的行
root@localhost ~]# grep -f 1.sh 2.sh
2)输出2.sh文件中在1.sh文件不同的行
root@localhost ~]# grep -v -f 1.sh 2.sh
3)匹配多个模式
root@localhost ~]# echo "a bc de" | xargs -n1 | grep -e 'a' -e 'bc'
a
bc
4)去除空格httpd.conf文件空行或开头#号引用的行
[root@localhost ~]# grep -E -v "^$|^#" /etc/httpd/conf/httpd.conf
5)匹配开头不分大小写的单词
[root@localhost ~]# echo "A a B c"| xargs -n1| grep -i a
[root@localhost ~]# echo "A a B c"| xargs -n1| grep '[A a]'
A
a
6)只显示匹配的字符串
[root@localhost ~]# echo "this is a test" | grep -o 'is'
is
is
root@localhost ~]# grep -c "nginx" /etc/passwd #统计nginx字符的总行数
1
[root@localhost ~]# grep -i "nginx" /etc/passwd
nginx:x:500:500::/home/nginx:/sbin/nologin
[root@localhost ~]# grep -n "nginx" /etc/passwd #打印”nginx”的行以及行号
20:nginx:x:500:500::/home/nginx:/sbin/nologin
[root@localhost ~]# grep -v "nginx" /etc/passwd #取反,不打印nginx行
5.2【Sed】
sed是一个非交互文本编辑。对文本文件和标准输入进行编辑,标准输入可以来自键盘输入,文本重定向,字符串,变量,甚至来自于管道的文本,与VIM编辑器类似,它一次处理一行内容,sed可以编辑一个或多个文件,简化对文件的反复操纵,编写转换程序等
在处理文本时把当前处理的行存储在临时缓冲区中,称为“模式空间”紧接着用SED命令处理缓冲区的内容,处理完成之后把缓冲区的内容输出至屏幕或者写入文件
逐行处理直到文件末尾,然而如果打印在屏幕上,实质文件内容并没有改变。除非你使用重定向存储或者写入文件
x #为指定行号
x,y #指定从x到y的行号范围
/pattern #查询包含模式的行
/pattern/pattern/ #查询包含两个模式的行
/pattern/,x #从与pattern的匹配行到x号行之间的行
/x/pattern/ #从x号行到与pattern的匹配行之间的行
x,y! #查询不包括x和y行号的行
r #从另一个文件中读取文件
w #将文本写入到一个文件
y #变换字符
q #第一模式匹配完成退出
{} #在定位行执行的命令组
p #打印匹配行
= #打印文本行号
a\ #在定位行号之后追加文本信息
i\ #在定位行号之前插入文本信息
d #删除定位行
c\ #用新文本替换定位文本
s #使用替换模式替换相应模式
n #读取下一个输入行,用下一个命令处理新的行
N #将当前读入行的下一行读取到当前的模式空间
h #将模式缓冲区的文本复制到保持缓冲区
H #将模式缓冲区的文本追加到保持缓冲区
x #互换模式缓冲区和保持缓冲区的内容
g #将保持缓冲区的内容复制到模式缓冲区
G #将保持缓冲区的内容追加到模式缓冲区
如果用户希望在某个条件下脚本中的某个命令被执行,或者是希望模式空间
#N,D,P:处理多行模式空间的问题
#H,h,G,g,x:将模式空间的内容放入存储空间以便接下来的编辑
#:、b、t、:在脚本中实现分支与条件结构
[匹配打印(p]
1)打印匹配blp5名称开头的行
[root@localhost ~]# tail /etc/services | sed -n '/^blp5/p'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
2)打印第一行
[root@localhost ~]# tail /etc/services | sed -n '1p'
nimgtw 48003/udp # Nimbus Gateway
3)打印第一行至第三行
[root@localhost ~]# tail /etc/services | sed -n '1,3p'
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
isnetserv 48128/tcp # Image Systems Network Services
4)打印奇数行
[root@localhost ~]# seq 10 | sed -n '1~2p'
1
3
5
7
9
5)打印匹配行以及后一行
[root@localhost ~]# tail /etc/services | sed -n '/nimgtw/,+1p'
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
6)打印最后一行
[root@localhost ~]# tail /etc/services | sed -n '$p'
iqobject 48619/udp # iqobject
7)不打印最后一行
[root@localhost ~]# tail /etc/services | sed -n '$!p'
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
8)打印第一行至第三行,
[root@localhost ~]# tail /etc/services | sed -n '1p;3p'
nimgtw 48003/udp # Nimbus Gateway
isnetserv 48128/tcp # Image Systems Network Services
9)删除匹配行至最后一行
root@localhost ~]# tail /etc/services | sed '/blp5/,$d'
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
10)删除最后一行
[root@localhost ~]# tail /etc/services | sed '$d'
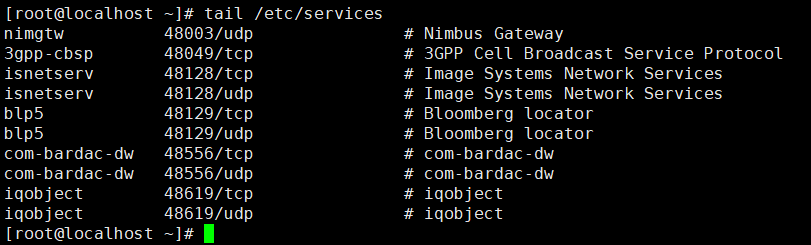
11)在nimgtw的下一行添加去xiaoyu字符串
[root@localhost ~]# tail /etc/services | sed '/nimgtw/axaioyu'
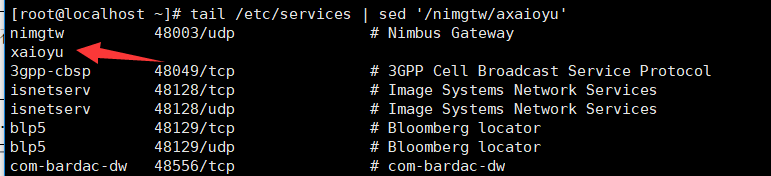
12)在nimgtw的上一行添加word字符串
root@localhost ~]# tail /etc/services | sed '/nimgtw/iword'
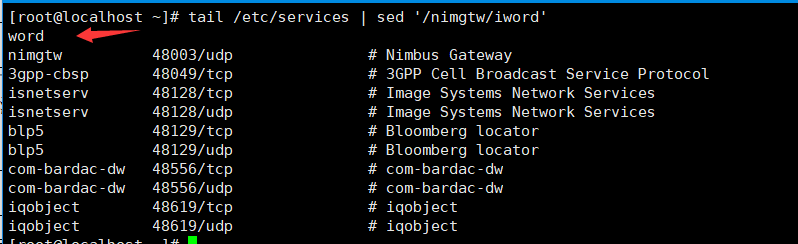
13)在文件中查找以Service结尾的行尾添加字符串work,$表示结尾标识,&标识在sed中添加
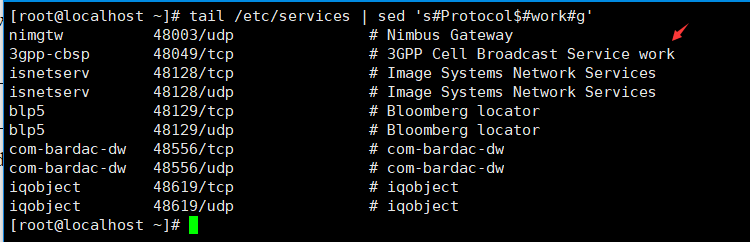
14)在文件中查找以nimgtw的行,在其行首添加字符串word,^表示起始标识,&在sed中表示添加
[root@localhost ~]# tail /etc/services | sed '/nimgtw/s/^/&work/g'
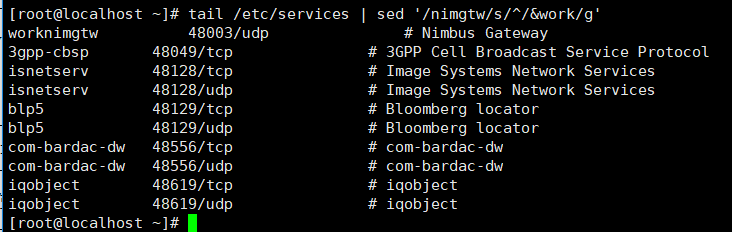
15)多个sed命令组合,使用-e参数
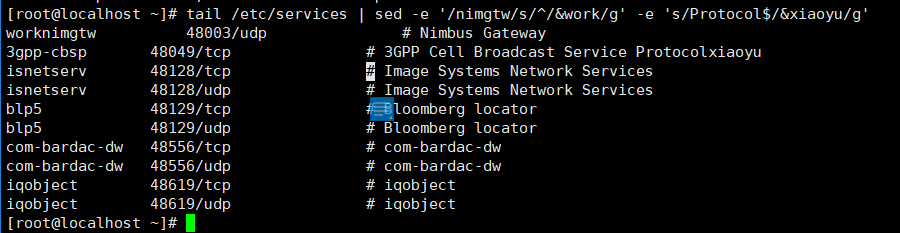
[root@localhost ~]# tail /etc/services | sed -e '/nimgtw/s/^/&work/g' -e 's/Protocol$/&xiaoyu/g'
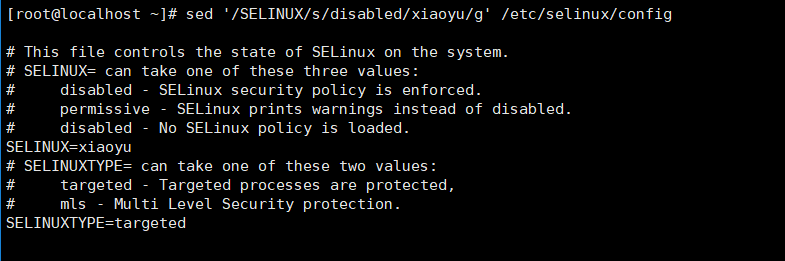
16)系应该Selinux策略enforcing为disabled,查找/SELINUX/行。然后将行enforcing值改成disabled,!s表示不包括SELINXU行
[root@localhost ~]# sed '/SELINUX/s/disabled/xiaoyu/g' /etc/selinux/config
5.3【Find】
主要用于操作系统文件,目录的查找,其语法参数的格式为:
find path -option [-print] [-exe -ok command] {} \;
参数常用参数详解如下:
-name filename #查找为filename的文件
-type b/d/c/l/f #查找块设备,目录,字符设备,管道,符号链接,普通文件
-size n[c] #查长度为n块【或n字节】的文件;
-perm #按执行权限来查找
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问天时间来查找文件
-ctime -n +n #按文件创建天时间来查找文件
PS:-mmin -amin -cmin #根据分钟来进行匹配查找
-nogroup #查找有效的属组的文件
-nouser #查找有效的属主的文件
-prune #忽略某个目录
-maxdepth #差找目录级别深度
1)Find工具-name参数案例
find /data/ -name "*.txt" #查找/data目录下以.txt结尾的文件
find /data/ -name "[A-Z]" #查找/data目录一大写字母开头的文件
find /data/ -name "test.*" #查找目录下以test开否的文件
2)-type参数案列
find /data/ -type d #查找目录下的文件夹
find /data/ !-type d #查找目录下的非文件夹
find /data/ -type -l #查找目录下的链接文件
find /data/ -type d | xarges chmod 755 -R #查找目录类型并将权限设置为755
find /data/ -type f | xarges chmod 644 -R #查找文件类型并将权限设置为644
3)-size参数案列
find /data/ -size +1M #查找文件大小大小1MB的文件
find /data/ -size 10M #查找文件为10MB的文件
find /data/ -size -1M #查找文件小于1MB的文件
4)-perm参数案列 (权限参数)
find /data/ -perm 755 #查找/data/目录权限为755的文件或者目录
find /data/ -perm -007 #查找与-perm777相同,表示所有权限
find /data -perm +644 #查找文件权限在644以上
5)-mtime/-ctime/atime参数案例
atime:文件被读取或者是执行的时间
ctime:文件状态被修改时间
mtime:文件内容被修改时间
find /data/ -mtime +10 -name "*.log" #查找10天以前被修改的log结尾文件
find /data/ -ctime +10 -name "*.txt" #查找10天以前的所创建以txt结尾的文件
find /data/ -atime +10 -name ".txt" #查找10天以前被访问的txt结尾的文件
综合案列~~~~~
#查找/data目录以.log结尾,文件大于10k的文件,同时cp到/tmp目录;
find /data/ -name "*.log" –type f -size +10k -exec cp {} /tmp/ \;
#查找/data目录以.txt结尾,文件大于10k的文件,权限为644并删除该文件;
find /data/ -name "*.log" –type f -size +10k -m perm 644 -exec rm –rf {} \;
#查找/data目录以.log结尾,30天以前的文件,大小大于10M并移动到/tmp目录;
find /data/ -name "*.log" –type f -mtime +30 –size +10M -exec mv {} /tmp/ \;
5.4【AWK】
awk是一个优良的文本处理工具,linux及Unix环境中现有的功能最强大的数据处理引擎之一,awk是一个行级文本高效处理 工具,awk经过该井生成新的版本有Nawk,Gawk,一般默认为Gawk,Gawk是awk的GUN开源免费版本
AWK基本原理是逐行处理文本中的数据,查找与命令行中所给定的内容相匹配的模式,如果发现匹配内容,则进行下一个编程步骤,如果找不到匹配内容,则进行下一行;
器语法参数格式为:awk ‘pattern + {action}’ file
1)awk基本语法参数详解:
#单引号‘’是和shell命令区分开;
#大括号{}表示一个命令分组
#pattern是一个过滤器,表示匹配pattern条件的行才进行Action处理
#action是处理动作,常见动作为Print;
#使用#作为注释,pattern和action可以只有其一,但不能两者都没有;
2)AWK内置变量详解:
#FS 分隔符,默认是空格
#OFS 输出分隔符
#NR 当前行数,从1开始
#NF 当前记录字段个数
#$0 当前记录
#$1~$n 当前记录第n个字段(列)
3)AWK内置函数详解:
#gsub(r,s):在$0中用s代替r;
#length(s):s的长度
案例:
cat /etc/passwd | awk 'length($0)>50{print NR}' #打印配置文件中,长度大于50的行号;
打印第一列同时只显示前五行(以下两种方式)
cat /etc/services | head -5 | awk -F: '{print $1}'
cat /etc/services | awk -F: 'NR>=1&&NR<=5 {print $1}'
# /etc/services
# $Id
#
# Network services, Internet style
# IANA services version
AWK添加自定义字符,过滤到ip
ifconfig eth0 | grep "Bcast" | awk '{print $2}' | awk -F: '{print $2}'
192.168.2.138
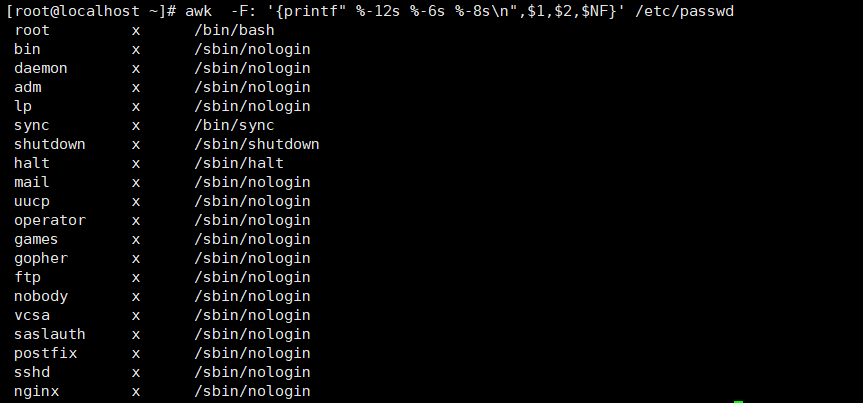
AWK格式化输出passwd内容,printf打印字符串,%格式化输出分隔符,s表示字符串类型,-12表示12个字符,-6表示6个字符;
# awk -F: '{printf" %-12s %-6s %-8s\n",$1,$2,$NF}' /etc/passwd
awk分析Nginx访问日志的状态码404,502,等错误信息页面,统计次数大于20的IP地址
[root@localhost logs]# awk '{if ($9~/502|499|500|503|404/) print $1,$9}' access.log|sort|uniq -c|sort -nr | awk '{if($1>1) print $2}'
统计TCP连接状态
# netstat -antp | awk '/^tcp/{a[$6]++}END{for(v in a)print a [v],v}'
# netstat -an | awk '/tcp/ {print $NF}' | sort | uniq -c
2 ESTABLISHED
5 LISTEN
Shell文本处理四剑客的更多相关文章
- shell 编程四剑客简介 find sed grep awk(微信公众号摘抄)
一,Shell编程四剑客之Find 通过如上基础语法的学习,读者对Shell编程有了更近一步的理解,Shell编程不再是简单命令的堆积,而是演变成了各种特殊的语句.各种语法.编程工具.各种命令的集合. ...
- Shell编程四剑客包括:find、sed、grep、awk
一.Shell编程四剑客之Find Find工具主要用于操作系统文件.目录的查找,其语法参数格式为: find path -option [ -print ] [ -exec -ok command ...
- linux四剑客-grep/find/sed/awk/详解-技术流ken
四剑客简介 相信接触过linux的大家应该都学过或者听过四剑客,即sed,grep,find,awk,有人对其望而生畏,有人对其爱不释手.参数太多,变化形式太多,使用超级灵活,让一部分人难以适从继而望 ...
- HTML布局四剑客-Flex,Grid,Table,Float
前言 在HTML布局中有很多的选择,同一种表现方式可以使用不同的方法来实现.下面来对四种最常见的布局方式进行阐述和解释,它们分别是Float,Table,Grid和Flex Float 第一位出场的就 ...
- Linux 命令之 linux 四剑客
Linux命令-- 四剑客 一:Linux命令 之 AWK 符号:^ 开头 $ 结尾 awk 是一种处理文本的语言,一个强大的文本分析命令! 1:提取文件中的每行的第二个 提取前文本中内容为 命令: ...
- Linux - 常见Shell文本处理方法
Common Shell Text Processing 珠玉在前,不再赘言. Linux Shell 文本处理工具集锦:http://blog.jobbole.com/99063/ 数据工程师常用的 ...
- python 函数“四剑客”的使用和介绍
python函数四剑客:lambda.map.filter和reduce. 一.lambda(匿名函数) 1. 学习lambda要注意一下几点: lambda语句被用来创建新的函数对象,并且在运行的时 ...
- shell文本处理工具总结
shell文本处理工具总结 为了效率,应该熟练的掌握自动化处理相关的知识和技能,能力就表现在做同样的一件事情,可以做的很好的同时,耗时还很短. 再次总结shell文本处理的相关规则,对提高软件调试效率 ...
- Linux shell文本处理工具
搞定Linux Shell文本处理工具,看完这篇集锦就够了 Linux Shell是一种基本功,由于怪异的语法加之较差的可读性,通常被Python等脚本代替.既然是基本功,那就需要掌握,毕竟学习She ...
随机推荐
- Android Day1
[2013-10-04 9:49] 复习第一课. Building Your First App; 1.安装好SDK 后,启动Eclipse,新建一个Android工程.设置使用默认. 2.检查文件 ...
- python连接kafka生产者,消费者脚本
# -*- coding: utf-8 -*- ''''' 使用kafka-Python 1.3.3模块 # pip install kafka==1.3.5 # pip install kafka- ...
- Anaconda安装新模块
如果使用import导入的新模块没有安装,则会报错,下面是使用Anaconda管理进行安装的过程:1.打开Anaconda工具,如图: 2.可通过输入 conda list 查看已安装的模块 3.如果 ...
- ASP.NET 验证码绘制
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- Python Redis pipeline操作
Redis是建立在TCP协议基础上的CS架构,客户端client对redis server采取请求响应的方式交互. 一般来说客户端从提交请求到得到服务器相应,需要传送两个tcp报文. 设想这样的一个场 ...
- which命令和bin目录
命令: which 作用: 查看执行命令所在位置 使用: which ls which useradd 等等... bin和sbin: 绝大多数可执行文件都保存在 /bin./sbin./usr/bi ...
- iOS -- Effective Objective-C 阅读笔记 (2)
1: 多用类型常量, 少用 #define 预处理指令 #define 预处理指令会把碰到的所有 指定名称 一律换位 定义的内容, 这样的话, 假设此指令在某个头文件中, 那么所有引入这个头文件的代码 ...
- RCNN--目标检测
原博文:http://www.cnblogs.com/soulmate1023/p/5530600.html 文章简要介绍RCNN的框架,主要包含: 原图-->候选区域生成-->对每个候选 ...
- gnuradio 创建动态库 libftd3xx.so
首先还是创建好模块gr-kcd cd gr-kcd 打开CMakeLists.txt cmake_minimum_required(VERSION 2.6) project(gr-kcd CXX C) ...
- django之跨表查询及添加记录
一:创建表 书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many); 一本书只应该由一个出版商出 ...