用决策树(CART)解决iris分类问题
首先先看Iris数据集
Sepal.Length——花萼长度 Sepal.Width——花萼宽度
Petal.Length——花瓣长度 Petal.Width——花瓣宽度
通过上述4中属性可以预测花卉属于Setosa,Versicolour,Virginica 三个种类中的哪一类
决策树 by CART
决策树有挺多种,这里讲下CART
CART的执行过程是这样的:
- 用特征值k和下限tk二分子集
- 不断二分,直到到达最大深度或者划分不能再减少不纯度为止
这一下sklearn都会自动帮我们完成,我们调用就行了
如何避免过拟合问题
减小最大深度等等
一个tip:
min_* 的调大
max_*的调小
就是DecisionTreeClassifier里面的参数,具体看文档_(:з」∠)_
损失函数的比较
sklearn提供了两种损失函数gini和entropy
gini是通过计算每个节点的不纯度,具体公式如下↓
\(J(k,t_k) = \frac{m_{left}}{m}G_{left} + \frac{m_{right}}{m}G_{right}\)
entropy在这里就不再赘述了
sklearn默认的是调用gini,因为gini的速度会快点,而且两者最后的效果是差不多的,真要比的话entropy产生的决策树会更平衡点
接下来我们来看代码
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
import numpy as np
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target #目标值
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42) #定义最大深度和确定随机种子
tree_clf.fit(X, y) #训练
print(tree_clf.predict_proba([[5, 1.5]])) #预测返回的是可能性
#以上代码运行后将会产生如下输出 [[ 0. 0.90740741 0.09259259]]
#分别代表属于每一种类别可能的概率
#也可以用如下代码
print(tree_clf.predict[[5,1.5]]) #直接输出属于哪一类
看下上面生成的决策树的样子
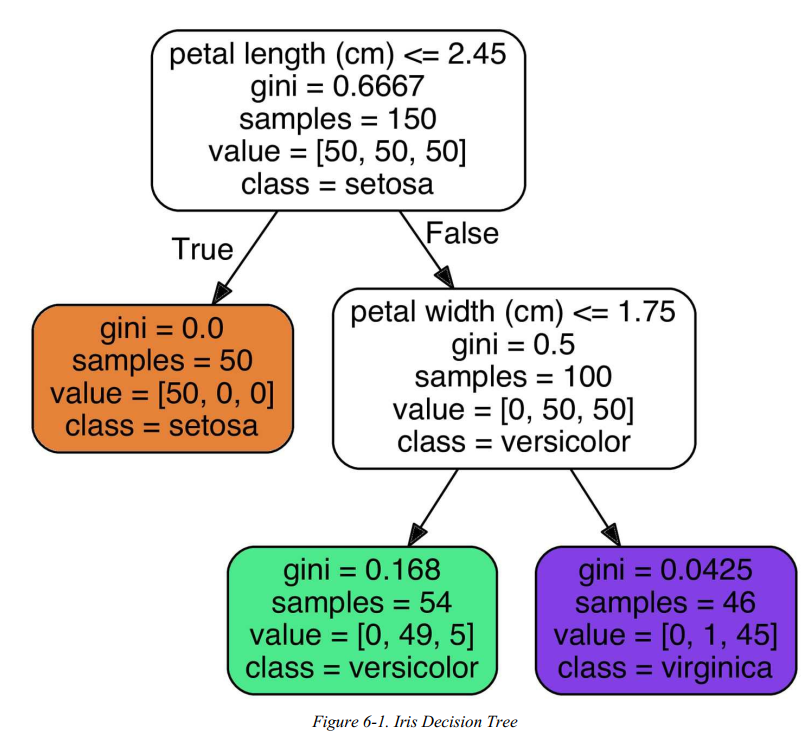
注:
valuse是它划分到各个类的数量
samples 指的是当前节点的数据个数
从左表橙色的点可以看出,gini=0意味着划分到了相同的类别里面
ps.以上代码及图片来自《Hands-On Machine Learning with Scikit-Learn》一书
如需转载请注明出处
喜欢要不支持下(:з」∠)
用决策树(CART)解决iris分类问题的更多相关文章
- 机器学习实战---决策树CART简介及分类树实现
https://blog.csdn.net/weixin_43383558/article/details/84303339?utm_medium=distribute.pc_relevant_t0. ...
- 机器学习实战---决策树CART回归树实现
机器学习实战---决策树CART简介及分类树实现 一:对比分类树 CART回归树和CART分类树的建立算法大部分是类似的,所以这里我们只讨论CART回归树和CART分类树的建立算法不同的地方.首先,我 ...
- 02-23 决策树CART算法
目录 决策树CART算法 一.决策树CART算法学习目标 二.决策树CART算法详解 2.1 基尼指数和熵 2.2 CART算法对连续值特征的处理 2.3 CART算法对离散值特征的处理 2.4 CA ...
- 03机器学习实战之决策树CART算法
CART生成 CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支.这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有 ...
- Keras入门(一)搭建深度神经网络(DNN)解决多分类问题
Keras介绍 Keras是一个开源的高层神经网络API,由纯Python编写而成,其后端可以基于Tensorflow.Theano.MXNet以及CNTK.Keras 为支持快速实验而生,能够把 ...
- 决策树--CART树详解
1.CART简介 CART是一棵二叉树,每一次分裂会产生两个子节点.CART树分为分类树和回归树. 分类树主要针对目标标量为分类变量,比如预测一个动物是否是哺乳动物. 回归树针对目标变量为连续值的情况 ...
- 【笔记】二分类算法解决多分类问题之OvO与OvR
OvO与OvR 前文书道,逻辑回归只能解决二分类问题,不过,可以对其进行改进,使其同样可以用于多分类问题,其改造方式可以对多种算法(几乎全部二分类算法)进行改造,其有两种,简写为OvO与OvR OvR ...
- 采用boosting思想开发一个解决二分类样本不平衡的多估计器模型
# -*- coding: utf-8 -*- """ Created on Wed Oct 31 20:59:39 2018 脚本描述:采用boosting思想开发一个 ...
- 决策树的剪枝,分类回归树CART
决策树的剪枝 决策树为什么要剪枝?原因就是避免决策树“过拟合”样本.前面的算法生成的决策树非常的详细而庞大,每个属性都被详细地加以考虑,决策树的树叶节点所覆盖的训练样本都是“纯”的.因此用这个决策树来 ...
随机推荐
- CNZZ友盟访问明细的采集办法
www.cnzz.com是中文网站统计分析平台,很多站长需要获取网站提供的访问明细,以做分析. 直接采集这个网站的数据相当麻烦,通过浏览器或者fiddlercore就简单多了. 2.0新版,通过浏览器 ...
- 提取PPT文件中的Vba ProjectStg Compressed Atom。Extract PPT VBA Compress Stream
http://msdn.microsoft.com/en-us/library/cc313106(v=office.12).aspx 微软文档 PartI ********************* ...
- 如何恢复Eclipse中被误删除的文件
在使用Eclipse时,可能会不小心误删除一些文件,没关系,Eclipse有个非常强大的功能,能让这些误删除的文件恢复回来,下面就来介绍一下. 工具/原料 Eclipse Kepler 方法/步骤 ...
- Mysql drop function xxxx ERROR 1305 (42000): FUNCTION (UDF) xxxx does not exist
mysql> drop function GetEmployeeInformationByID;ERROR 1305 (42000): FUNCTION (UDF) GetEmployeeInf ...
- artTemplate精彩文章(个人阅读过)
轻量级artTemplate引擎 实现前后端分离—基础篇 :https://www.imooc.com/article/20263 轻量级artTemplate引擎 实现前后端分离—语法篇 : htt ...
- transform: translate(-50%, -50%) 实现块元素百分比下居中
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- Linux基础学习(12)--Linux服务管理
第十二章——Linux服务管理 一.服务简介与分类 1.服务的分类: 注:独立的服务放在内存中(好处:响应的速率快,坏处:独立的服务越多,耗费的内存资源越多):xinetd服务本身是独立的,在内存中, ...
- WPF 将数据源绑定到TreeView控件出现界面卡死的情况
首先来谈一下实现将自定义的类TreeMode绑定到TreeView控件上的一个基本的思路,由于每一个节点都要包含很多自定义的一些属性信息,因此我们需要将该类TreeMode进行封装,TreeView的 ...
- 一个实际的案例介绍Spring Boot + Vue 前后端分离
介绍 最近在工作中做个新项目,后端选用Spring Boot,前端选用Vue技术.众所周知现在开发都是前后端分离,本文就将介绍一种前后端分离方式. 常规的开发方式 采用Spring Boot 开发项目 ...
- scrapy 项目搭建
安装好scrapy后,开始创建项目 项目名:zhaopin 爬虫文件名:zhao 1:cmd -- scrapy startproject zhaopin 2:cd zhaopin,进入项目目 ...