深度学习之GRU网络
1、GRU概述
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
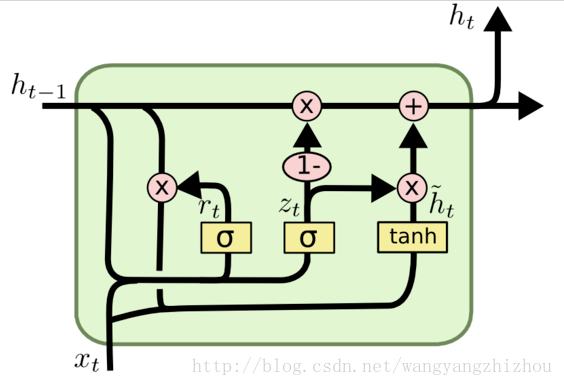
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 $\tilde{h}_t$ 上,重置门越小,前一状态的信息被写入的越少。
2、GRU前向传播
根据上面的GRU的模型图,我们来看看网络的前向传播公式:
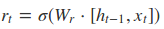
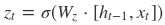
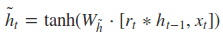
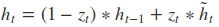
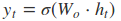
其中[]表示两个向量相连,*表示矩阵的乘积。
3、GRU的训练过程
从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将他们分割出来:
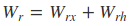
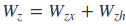
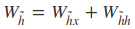
输出层的输入:
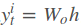
输出层的输出:
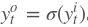
在得到最终的输出后,就可以写出网络传递的损失,单个样本某时刻的损失为:
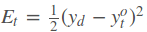
则单个样本的在所有时刻的损失为:
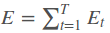
采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):
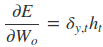
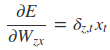
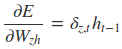
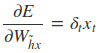
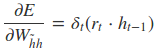
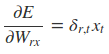
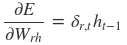
其中各中间参数为:
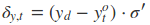
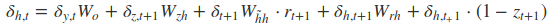
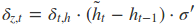
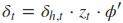
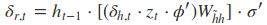
在算出了对各参数的偏导之后,就可以更新参数,依次迭代知道损失收敛。
概括来说,LSTM和CRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。此外GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM的。不过对于两个网络的好坏还是得看具体的应用场景。
参考文献:
***本文为参考各位大神博客的笔记*
深度学习之GRU网络的更多相关文章
- 深度学习图像分割——U-net网络
写在前面: 一直没有整理的习惯,导致很多东西会有所遗忘,遗漏.借着这个机会,养成一个习惯. 对现有东西做一个整理.记录,对新事物去探索.分享. 因此博客主要内容为我做过的,所学的整理记录以及新的算法. ...
- 调参侠的末日? Auto-Keras 自动搜索深度学习模型的网络架构和超参数
Auto-Keras 是一个开源的自动机器学习库.Auto-Keras 的终极目标是允许所有领域的只需要很少的数据科学或者机器学习背景的专家都可以很容易的使用深度学习.Auto-Keras 提供了一系 ...
- 深度学习|基于LSTM网络的黄金期货价格预测--转载
深度学习|基于LSTM网络的黄金期货价格预测 前些天看到一位大佬的深度学习的推文,内容很适用于实战,争得原作者转载同意后,转发给大家.之后会介绍LSTM的理论知识. 我把code先放在我github上 ...
- 深度学习之ResNet网络
介绍 Resnet分类网络是当前应用最为广泛的CNN特征提取网络. 我们的一般印象当中,深度学习愈是深(复杂,参数多)愈是有着更强的表达能力.凭着这一基本准则CNN分类网络自Alexnet的7层发展到 ...
- 深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成: 生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器 判别器D(Discriminator):判断这张图像是真实的 ...
- 深度学习之TCN网络
论文链接:https://arxiv.org/pdf/1803.01271.pdf TCN(Temporal Convolutional Networks) TCN特点: 可实现接收任意长度的输入序列 ...
- 深度学习之Seq_seq网络
知识点 """ 机器翻译: 历史: 1.逐字翻译 2.基于统计学的机器翻译 3.循环网络和编码 翻译过程: 输入 -- > encoder -->向量 --& ...
- 训练深度学习网络时候,出现Nan是什么原因,怎么才能避免?——我自己是因为data有nan的坏数据,clear下解决
from:https://www.zhihu.com/question/49346370 Harick 梯度爆炸了吧. 我的解决办法一般以下几条:1.数据归一化(减均值,除方差,或者加入n ...
- [译]深度学习(Yann LeCun)
深度学习 严恩·乐库 约书亚•本吉奥 杰弗里·希尔顿 摘要深度学习是计算模型,是由多个处理层学习多层次抽象表示的数据.这些方法极大地提高了语音识别.视觉识别.物体识别.目标检测和许多其他领域如药物 ...
随机推荐
- java——初识
java是现在最火的高级编程语言之一,功能强,应用广. java可以做什么? 1. 开发桌面应用程序 2. 开发面向Internet的应用程序 开发java程序的基本步骤: 1. 编写源程序:mypr ...
- python面向对象学习(四)继承
目录 1. 单继承 1.1 继承的概念.语法和特点 1.2 方法的重写 1.3 父类的 私有属性 和 私有方法 2. 多继承 2.1 多继承的使用注意事项 2.2 新式类与旧式(经典)类 1. 单继承 ...
- clean 伪目标
下面的"clean"目标,是一个"伪目标", clean: rm *.o temp 我们生成了许多文件编译文件,我们也应该 ...
- 工作笔记-table问题汇总(vue单文件组件)
1.vue: computed里定义的数据,在其他地方不能再重新赋值,会报错: Computed property "xxxxxx" was assigned to but it ...
- javascript 里面 with 关键字
1.with的基本概念 with语句的作用是将代码的作用域设置到一个特定的作用域中,目的是为了简化多次编写访问同一对象的工作.基本语法如下: with (expression) statement 下 ...
- POJ1509 Glass Beads(最小表示法 后缀自动机)
Time Limit: 3000MS Memory Limit: 10000K Total Submissions: 4901 Accepted: 2765 Description Once ...
- Human Motion Analysis with Wearable Inertial Sensors——阅读2
Human Motion Analysis with Wearable Inertial Sensors 实时人体运动跟踪已经应用于生物医学领域的许多应用:临床步态分析,运动康复,跌倒检测,关节生物力 ...
- getCacheDir()、getFilesDir()、getExternalFilesDir()、getExternalCacheDir()
一.getCacheDir.getCacheDir getCacheDir()方法用于获取/data/data//cache目录 getFilesDir()方法用于获取/data/data//file ...
- Retrieve OpenGL Context from Qt 5.5 on OSX
In the latest Qt 5.5, the QOpenGLWidget is much better and has less bugs than the QGLWidget, but it ...
- WPF控件库:文字按钮的封装
需求:封装按钮,按钮上面只显示文字.在鼠标移上去.鼠标点击按钮.以及将按钮设为不可用时按钮的背景色和前景色需要发生变化 实现:继承Button类,封装如下6个属性: #region 依赖属性 /// ...