scrapy 爬取豆瓣互联网图书
- 安装scrapy
-
conda install scrapy
-
- 生成一个scrapy项目
-
scrapy startproject douban
-
- settings文件
-
# -*- coding: utf-8 -*- # Scrapy settings for douban project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'douban' SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban (+http://www.yourdomain.com)'
# USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'douban.middlewares.DoubanSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'douban.middlewares.MyCustomDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
-
- 编写爬虫文件,位于spiders下面
-
import scrapy from douban.items import DoubanItem class MeijuSpider(scrapy.Spider):
name = 'doubanmovie'
allowed_domains=['book.douban.com']
start_urls=['https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91']
number=1;
def parse(self, response):
self.number = self.number+1;
# print(response.text)
objs=response.xpath('//*[@id="subject_list"]/ul/li')
# print(objs)
# print('test',response.xpath('//*[@id="content"]/div/div[1]/div/div/table[1]/tr/td[2]/div/a/text()').extract_first())
print(len(objs))
for i in objs :
item=DoubanItem()
item['name']=i.xpath('./div[2]/h2/a/text()').extract_first() or ''
item['score']=i.xpath('./div[2]/div[2]/span[2]/text()').extract_first() or ''
item['author']=i.xpath('./div[2]/div[1]/text()').extract_first() or ''
item['describe']=i.xpath('./div[2]/p/text()').extract_first() or ''
yield item
next_page = response.xpath('//*[@id="subject_list"]/div[2]/span[4]/a/@href').extract()
print(self.number);
if(self.number >11):
next_page = response.xpath('//*[@id="subject_list"]/div[2]/span[5]/a/@href').extract()
print(next_page)
if next_page:
next_link=next_page[0];
print("https://book.douban.com"+next_link)
yield scrapy.Request("https://book.douban.com"+next_link,callback=self.parse)
-
- 编写pipe文件
-
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class DoubanPipeline(object):
def process_item(self, item, spider):
with open('douban.txt','a',encoding='utf-8') as file:
file.write(str(item['name'].replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip() )
+','+item['score'].replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip()
+','+str(item['author']).replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip()
+','+item['describe'].replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip()
+ "\n"
)
-
- 执行
- 编写一个start.py文件
from scrapy.cmdline import execute
execute("scrapy crawl doubanmovie".split()) - 效果
-
- 编写一个start.py文件
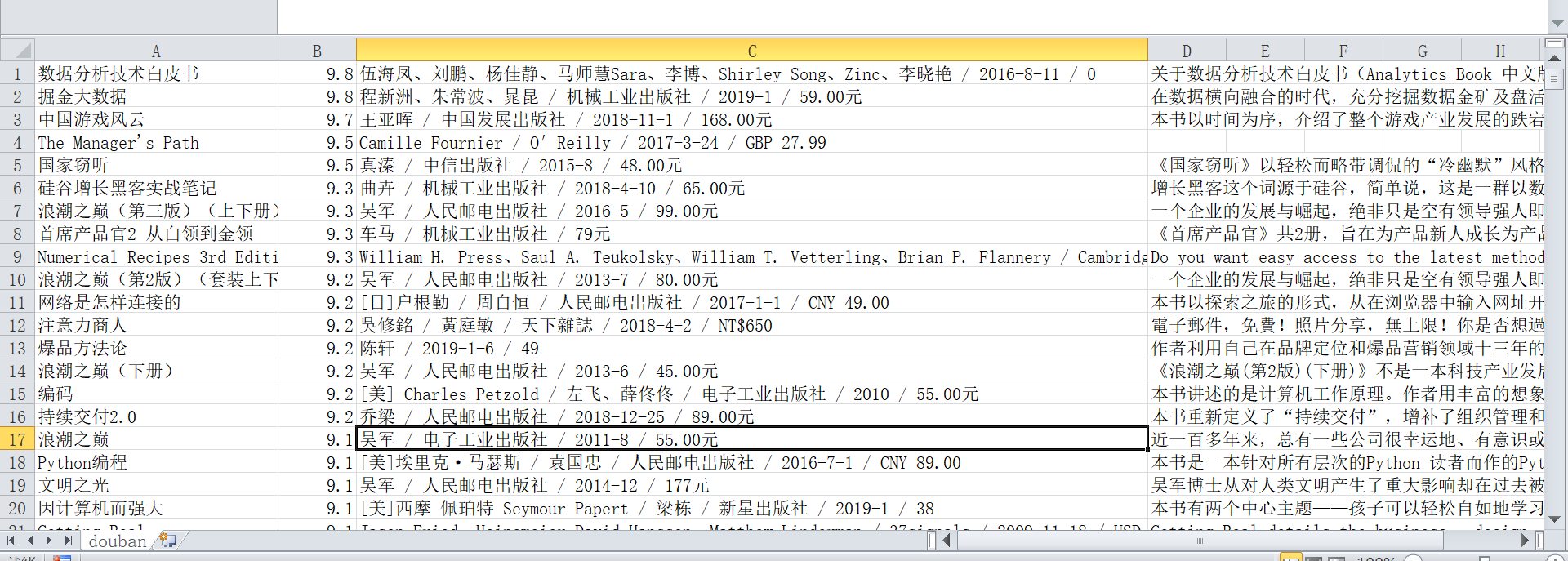
scrapy 爬取豆瓣互联网图书的更多相关文章
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- Scrapy爬取豆瓣图书数据并写入MySQL
项目地址 BookSpider 介绍 本篇涉及的内容主要是获取分类下的所有图书数据,并写入MySQL 准备 Python3.6.Scrapy.Twisted.MySQLdb等 演示 代码 一.创建项目 ...
- 使用scrapy爬取豆瓣上面《战狼2》影评
这几天一直在学习scrapy框架,刚好学到了CrawlSpider和Rule的搭配使用,就想着要搞点事情练练手!!! 信息提取 算了,由于爬虫运行了好几次,太过分了,被封IP了,就不具体分析了,附上& ...
- scrapy爬取豆瓣电影信息
最近在学python,对python爬虫框架十分着迷,因此在网上看了许多大佬们的代码,经过反复测试修改,终于大功告成! 原文地址是:https://blog.csdn.net/ljm_9615/art ...
- Scrapy爬取豆瓣电影top250的电影数据、海报,MySQL存储
从GitHub得到完整项目(https://github.com/daleyzou/douban.git) 1.成果展示 数据库 本地海报图片 2.环境 (1)已安装Scrapy的Pycharm (2 ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- python系列之(3)爬取豆瓣图书数据
上次介绍了beautifulsoup的使用,那就来进行运用下吧.本篇将主要介绍通过爬取豆瓣图书的信息,存储到sqlite数据库进行分析. 1.sqlite SQLite是一个进程内的库,实现了自给自足 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
随机推荐
- cmd常用命令总结
1.cmd不同盘符之间切换 方法(1): cd /d 路径如:cd /d c:/windows 方法(2): d:2.cls 清空cmd窗口dir 查看文件夹下的目录md 创建文件夹rd 删除文件夹c ...
- Azure CosmosDB (4) 在一致性(Consistency)可用性(Availability)和性能(Performance)之间的权衡
<Windows Azure Platform 系列文章目录> 我个人感觉,这个概念和分布式系统中的CAP原则是类似的: CAP原则指的是在一个分布式系统中,Consistency(一致性 ...
- Javascript神器之webstorm
推荐个编辑器主题下载的一个网站. Color Themes 网址:http://color-themes.com [点这里直接跳转] 但是,只支持几个编辑器. 各种颜色搭配的主题,随你选择!我个 ...
- json,pickle,shelve模块,xml处理模块
常用模块学习—序列化模块详解 什么叫序列化? 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化? 你打游戏过程 ...
- C# 6.0:String Interpolation
在开发中经常需要对字符串进行格式化处理.我们一般使用String.Format()方法,它会将指定字符串中的每个格式项替换为相应对象的值的文本等效项.虽然这很普通,但有时会容易使人迷惑并造成错误.因为 ...
- 廖雪峰Java8JUnit单元测试-2使用JUnit-1使用Before和After
1. @Before和@After 同一个单元测试内的多个测试方法: 测试前都需要初始化某些对象 测试后可能需要清理资源fileInputStream.close() @Test public voi ...
- codeblock字体问题
有的时候在codeblock中打下划线,会显示空格, 这个时候可以修改一下字体 settings->editor->editor settings最上面的fonts框中选择choose,然 ...
- Shiro的认证和权限控制
权限控制的方式 从类别上分,有两大类: - 认证:你是谁?–识别用户身份. - 授权:你能做什么?–限制用户使用的功能. 权限的控制级别 从控制级别(模型)上分: - URL级别-粗粒度 - 方法级别 ...
- python 最大连续子数组的和
抛出问题: 求一数组如 l = [0, 1, 2, 3, -4, 5, -6],求该数组的最大连续子数组的和 如结果为[0,1,2,3,-4,5] 的和为7 问题分析: 这个问题很简单,直接暴力法,上 ...
- Navicat操作SQL server 2008R2文件.bak文件还原
项目操作过程中,利用Navicat操作SQL Server2008R2数据备份,结果发现数据丢失了很多,不得不先对数据丢失部分进行差异对比,然后再重新输入. 1.利用Navicat导出的数据格式为sq ...