mysql 开发基础系列11 存储引擎memory和merge介绍
一. memory存储引擎
memoery存储引擎是在内存中来创建表,每个memory表只实际对应一个磁盘文件格式是.frm. 该引擎的表访问非常得快,因为数据是放在内存中,且默认是hash索引,但服务关闭,表中的数据就会丢失掉。
-- 下面创建一个memory表,并从city表获得记录
CREATE TABLE tab_memory ENGINE=MEMORY
SELECT city_id,country_id FROM city GROUP BY city_id
-- 给momory 表创建索引时,可以指定是hash索引还是btree索引
CREATE INDEX mem_hash USING HASH ON tab_memory(city_id);
SHOW INDEX FROM tab_memory

DROP INDEX mem_hash ON tab_memory;
CREATE INDEX mem_hash USING BTREE ON tab_memory(city_id)
SHOW INDEX FROM tab_memory

总结:服务器需要足够的内存来维护所有在同一时间使用的memory表,当不再需要时,要释放,应执行 delete from 或 truncate table 或删除表drop table。
每个memory表放置的数据量大小,受到max_heap_table_size系统变量的约束,初始值是16MB. 通过max_rows 子句指定表的最大行数。
memory类型 一般应用于临时表,如统计操作的中间结果表。
二. merge 存储引擎
merge 引擎是一组MyISAM表的组合,这些MYISAM表必须结构完全相同,merge表本身并没有数据,对表的增删改查 实际是对内部的myisam表进行操作。
对于merge类型表的插入操作有三种类型:first是插入在第一个表,last是插入到最后一个表,不定义或为NO表示不能对merge表执行插入操作,对于merge表的drop操作,内部的表没有任何影响。merge 在磁盘上保留两个文件,一个是.frm文件存储表定义,另一个是.mrg文件包含组合表的信息。
-- 下面来测试下,创建三个结构相同的表 payment_2006,payment_2007,payment_all(merge类型)。
CREATE TABLE payment_2006(
country_id SMALLINT,
payment_date DATETIME,
amount DECIMAL(15,2),
KEY inx_fx_country_id (country_id)
)ENGINE =MYISAM CREATE TABLE payment_2007(
country_id SMALLINT,
payment_date DATETIME,
amount DECIMAL(15,2),
KEY inx_fx_country_id (country_id)
)ENGINE =MYISAM CREATE TABLE payment_all(
country_id SMALLINT,
payment_date DATETIME,
amount DECIMAL(15,2),
INDEX (country_id)
)ENGINE =MERGE UNION=(payment_2006,payment_2007) INSERT_METHOD=LAST; -- 分别向payment_2006和payment_2007表插入数据
INSERT INTO payment_2006 VALUES(1,'2006-05-01',100000),(2,'2006-08-01',150000);
INSERT INTO payment_2007 VALUES(1,'2007-05-01',200000),(2,'2007-08-01',350000);
-- 查询payment_all
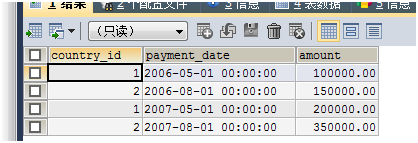
SELECT * FROM payment_all;
下图发现该paymnet_all表合并了二表的结果集:
-- 下面向payment_all表插入数据 表定义是INSERT_METHOD=LAST;
INSERT INTO payment_all VALUES(3,'2006-05-01',112000);
-- 查询
SELECT * FROM payment_2007;
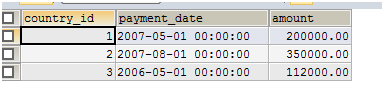
总结: MERGE表并不能智能地将记录写到对应的表中,而分区表是可以的,通常我们使用merge表来透明地对多个表进行查询和更新操作。
三..如何选择合适的存储引擎
myisam: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性,并发性要求不是很高,例如数据仓储。
innodb: 用于事务处理应用程序,支持外键,对事务的完整性较高,并发条件下数据一致性,包括很多的更新和删除操作,它能避免删除和更新导致的锁定,还提供了提交和回滚,例如计算费用对数据准确性要求高的。
memory: 数据保存在ram(内存)中,访问速度快,但对表的大小有限制,要确保数据是可以恢复的,常用于更新不太频繁的小表,用以快速访问。
merge: 它是myisam表以逻辑方式组合的引擎,将myisam表分布在多个磁盘上,可以有效改善merge表的访问效率。例如数据仓储等。
mysql 开发基础系列11 存储引擎memory和merge介绍的更多相关文章
- mysql 开发基础系列10 存储引擎 InnoDB 介绍
一. 概述: InnoDB存储引擎提供了具有提交,回滚,和崩溃恢复能力的事务安全,对比MYISAM 的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引.它的特点有如下: ...
- mysql 开发基础系列9 存储引擎 MyISAM 介绍
MyISAM是mysql 默认存储引擎,它不支持事务,外键.但访问速度快,对事务完整性没有要求或者以select,insert 为主的应用基本上都可以使用这个引擎.每个MyISAM在磁盘上存储成3个文 ...
- mysql 开发基础系列12 选择合适的数据类型(上)
一. char 与varchar比较 在上图的最后一行的值只适用在"非严格模式",关于严格模式后面讲到.在“开发基础系列4“ 中讲到CHAR 列删除了尾部的空格.由于char是固定 ...
- mysql 开发基础系列8 表的存储引擎
一. 表的存储引擎 1. 概述 插件式存储引擎是mysql数据库最重要的特性之一, 用户可以根据应用的需要选择如何存储和索引数据,是否使用事务等.在mysql 5.0里支持的引擎包括: MyISAM, ...
- mysql 开发基础系列15 索引的设计和使用
一.概述 所有mysql 列类型都可以被索引,是提高select查询性能的最佳方法. 根据存储引擎可以定义每个表的最大索引数和最大索引长度,每种引擎对每个表至少支持16个索引,总索引长度至少为256字 ...
- mysql 开发基础系列20 事务控制和锁定语句(上)
一.概述 在mysql 里不同存储引擎有不同的锁,默认情况下,表锁和行锁都是自动获得的,不需要额外的命令, 有的情况下,用户需要明确地进行锁表或者进行事务的控制,以便确保整个事务的完整性.这样就需要使 ...
- mysql 开发基础系列21 事务控制和锁定语句(下)
1. 隐含的执行unlock tables 如果在锁表期间,用start transaction命令来开始一个新事务,会造成一个隐含的unlock tables 被执行,如下所示: 会话1 会话2 ...
- mysql 开发基础系列17 存储过程和函数(上)
一. 概述 存储过程和函数是事先经过编译并存储在数据库中的一段sql语句集合,可以简化应用开发人员的很多工作,减少数据在数据库与应用服务器之间的传输,提高数据处理效率是有好处的.存储过程和函数的区别在 ...
- mysql 开发基础系列1 表查询操作
在安装完数据库后,不管是windows 还是linux平台, mysql的sql命令都大同小异,相关命令都是相同的,每个命令结束后 都以 ; 结尾, 注意在windows平台中表名是不区分大小写 ...
随机推荐
- 高斯混合模型(GMM) - 混合高斯回归(GMR)
http://www.zhihuishi.com/source/2073.html 高斯模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数(正态分布曲 ...
- 464. Can I Win
https://leetcode.com/problems/can-i-win/description/ In the "100 game," two players take t ...
- cpu的工作原理
- CSS基础一
css作用 css将内容和样式相分离,便于修改样式.HTML 写网页的内容,CSS写内容的样式 CSS构成 p{ /*p为标签,也可以称为选择器,选择包住的内容的格式*/ font-size:12px ...
- ajax相关知识总结
一.原生AJAX的兼容版本实现 function createXhr(){ var Xhr = null; //浏览器的判断 if(window.XMLHttpRequest){ //ie789 ch ...
- Unity3D编辑器扩展(六)——模态窗口
前面我们已经写了5篇关于编辑器的,这是第六篇,也是最后一篇: Unity3D编辑器扩展(一)——定义自己的菜单按钮 Unity3D编辑器扩展(二)——定义自己的窗口 Unity3D编辑器扩展(三)—— ...
- api controller 接口接收json字符串参数
{"data":{"alarmRepeatTimes":2,"currentMode":1,"moduleResetTimeout ...
- 2019/3/7 Java学习之多线程(基础)
Java学习之多线程 讲到线程,就必须要懂得进程,进程是相当于一个程序的开始到结束,而线程是依赖于进程的,没有进程,就没有线程.线程也分主线程和子线程,当在主线程开启子线程时,主线程结束,而子线程还可 ...
- windows mysql zip 安装
https://www.cnblogs.com/iathanasy/p/8461429.html
- 读书笔记二 How Does the Internet work?
原文链接: https://web.stanford.edu/class/msande91si/www-spr04/readings/week1/InternetWhitepaper.htm 先写写 ...