爬虫 scrapy 笔记
scrapy 基础
1、 创建一个spider项目
a) Scrapy startproject project_name [project_dir]
b) Cd project 进入项目
2、 命令:
a) Global commands:
i. startproject 创建项目
ii. genspider 创建一个爬虫
iii. settings
iv. runspider
v. shell
vi. fetch
vii. view
viii. version
b) Project-only commands:
i. crawl
ii. check
iii. list
iv. edit
v. parse
vi. bench
3、 创造一个爬虫
$ scrapy genspider -l
Available templates:
Basic 默认
crawl
csvfeed
xmlfeed
a) Scrapy genspider mydomain mydomain.com ---》basic
b) Scrapy genspider –t crawl mydomain mydomain.com
4、 运行spider
a) Scrapy crawl myspider
理解一个scrapy:
Spider.py :
1、 start_url:是要爬取的第一个URL地址,可以有多个值
2、 parse(response):是request请求的结果,使用response.text()获取页面信息。
3、 response是一个‘scrapy.http.response.html.HtmlResponse’对象,可以使用xpath和css来提取数据。
4、 提取出来的数据是一个‘selector’或者‘selectorList’对象,可以使用get(),或者getall()来获取内容。
5、 Getall()是获取一个列表,get()是获取列表的第一个值
6、 如果数据解析出来,可以使用yield一个一个返回,也可以一次使用return返回多个。
7、 Item:建议使用item,数据结构化处理,数据更清晰。
8、 Pipline:用来处理item数据:
a) Open_spider():再启动爬虫时执行,可以做一些预处理操作
b) Process_item():处理spider.py传过来的数据可以保存、去重等操作。
c) Close_spider():关闭爬虫时执行,坐一些善后操作。
注:要使用pipline,必须先在setting中激活pipline
Request 与 Response 请求与响应
Request:参数
1、 URL:request对象发送请求的URL
2、 Callback:请求之后的回调函数
3、 Method:默认Get,可以设置为其他方式,如果是post,建议使用formRequest
4、 Headers:请求头:对于一般固定的设置放在setting中,非固定的可以在发送请求的时候指定
5、 Meta:比较常用,用于在不同的请求之间使用传递使用
6、 Encoding:编码,默认是utf-8
7、 Dot_filter:表示不由调度器过滤,在使用多次重复请求的使用用的比较多,比如:验证码失败的时候
8、 Errback:在发生错误的时候执行的函数。
Response:对象属性,可以用来提取数据
1、 meta:从其他请求传过来的meta属性,可以用来保持多个请求之间的数据连接
2、 encoding:返回当前字符串编码和解码的格式
3、 text:将返回的数据作为Unicode字符串返回
4、 body:将返回的数据作为bytes字符串返回
5、 xpath:xpath选择器
6、 css:css选择器
POST请求:
1、重写‘start_requests’方法
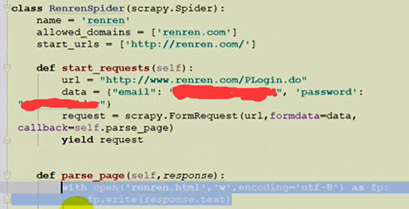
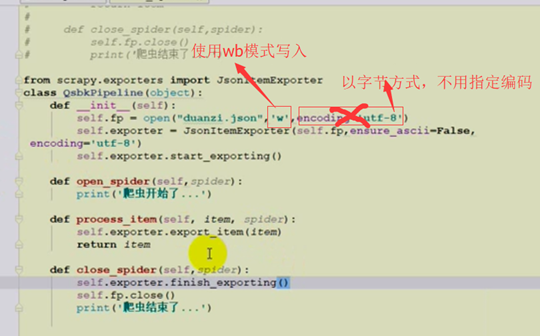
以json的形式导出:pipline操作
1、使用JSonItemExporter 先是保存在列表中,最后在finish一次写入,占用内存。满足json格式
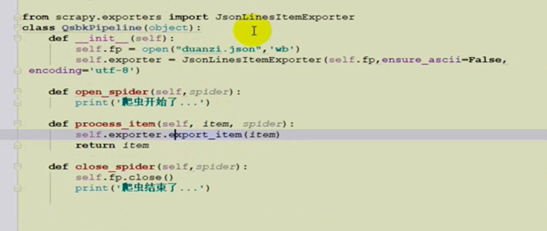
2、JsonLinerItemExporter、多次写入不是json格式,数据比较安全,防止发生意外
================crawlspider ====
需要使用“LinkExtrator”和“Rule”。这两个东西是(crawlspider)爬虫的主要内容。
1 、allow设置规则的方法:要能够限制在我们我们想要的URL上面,不要跟其他的URL产生相同的正则表达式即可。
2、使用Fallow的情况:如果在爬取页面的时候,需要将满足条件的URL连接进行跟进,那么就设置为True,否则设置为False。
3、callkack:如果这个URL对应的页面,只是为了获取更多的URL,并不需要里面的数据,那么可以不指定callkack。如果想要获取URL对应的页面的数据,那么就需要指定一个callback。
===========scrapy shell URL==========
1、可以方便我们做一些数据提取的测试代码。
2、如果想要执行scrapy命令,要先进入scrapy的环境中
3、如果想要读取某个项目的配置信息,那么应该先进入这个项目,在执行“scrapy shell URL”命令。
反 爬虫:
验证码:阿里云接口识别
File pipline文件下载管道
image pipline图片下载管道
下载器中间件:自定义 重写两个方法
1、process_request()
参数1:request 发送请求的request
参数2:spider 发送请求的spider
返回值:
1、 None: 如果返回none,scrapy继续执行该请求,执行其他的中间件的相应方法,直到合适的下载器函数被相应调用。
2、 Response: 如果返回response,那么scrapy将不会调用其他的process_request方法,将直接返回这个response对象,已经激活的中间件的process_response方法则会在每个response返回时调用
3、 Request :不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据
4、 如果这个方法抛出异常,则会调用process_exception方法
2、process_response()
参数:
1、 request:请求对象
2、 response:被处理的response对象
3、 spider:spider对象
返回值:
1、 response:会将这个新的response对象传递给其他中间件,最终给爬虫
2、 request:下载器链被切断,返回的request会重新被下载器调度下载
3、 异常:那么将调用request的errback方法,如果没有指定这个方法,那么会抛出异常
爬虫 scrapy 笔记的更多相关文章
- Scrapy笔记10- 动态配置爬虫
Scrapy笔记10- 动态配置爬虫 有很多时候我们需要从多个网站爬取所需要的数据,比如我们想爬取多个网站的新闻,将其存储到数据库同一个表中.我们是不是要对每个网站都得去定义一个Spider类呢? 其 ...
- Python 爬虫个人笔记【目录】
个人笔记,仅供参考 目录 Python爬虫笔记(一) Python 爬虫笔记(二) Python 爬虫笔记(三) Scrapy 笔记(一) Scrapy 笔记(二) Scrapy 笔记(三) Pyth ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy笔记(1)- 入门篇
Scrapy笔记01- 入门篇 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说, ...
- Scrapy笔记02- 完整示例
Scrapy笔记02- 完整示例 这篇文章我们通过一个比较完整的例子来教你使用Scrapy,我选择爬取虎嗅网首页的新闻列表. 这里我们将完成如下几个步骤: 创建一个新的Scrapy工程 定义你所需要要 ...
- Scrapy笔记03- Spider详解
Scrapy笔记03- Spider详解 Spider是爬虫框架的核心,爬取流程如下: 先初始化请求URL列表,并指定下载后处理response的回调函数.初次请求URL通过start_urls指定, ...
- Scrapy笔记05- Item详解
Scrapy笔记05- Item详解 Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API, ...
- Scrapy笔记06- Item Pipeline
Scrapy笔记06- Item Pipeline 当一个item被蜘蛛爬取到之后会被发送给Item Pipeline,然后多个组件按照顺序处理这个item. 每个Item Pipeline组件其实就 ...
- Scrapy笔记07- 内置服务
Scrapy笔记07- 内置服务 Scrapy使用Python内置的的日志系统来记录事件日志. 日志配置 LOG_ENABLED = true LOG_ENCODING = "utf-8&q ...
随机推荐
- Shell - 文本处理
珠玉在前,不再赘言. 常用命令 LinuxShell文本处理工具集锦 数据工程师常用的Shell命令 文件和目录管理 简明教程 AWK简明教程 SED简明教程 命令详解 linux sort,uniq ...
- Data - Spark简介
Spark简介 Spark是基于内存计算的大数据并行计算框架,可用于构建大型的.低延迟的数据分析应用程序. HomePage:http://spark.apache.org/ GitHub:https ...
- 机器学习技法笔记:11 Gradient Boosted Decision Tree
Roadmap Adaptive Boosted Decision Tree Optimization View of AdaBoost Gradient Boosting Summary of Ag ...
- 机器学习技法笔记:04 Soft-Margin Support Vector Machine
Roadmap Motivation and Primal Problem Dual Problem Messages behind Soft-Margin SVM Model Selection S ...
- MarkDown基础语法记录
基础语法记录,其中有一些博客园暂不支持 <!--标题--> # 一级标题 # ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ###### 六级标题 一级标题 ...
- Unsupervised learning无监督学习
Unsupervised learning allows us to approach problems with little or no idea what our results should ...
- Docker总结(脑图图片)
- Linux_CentOS-服务器搭建 <六>
修改MySQL编码: 二话不说先登录: mysql -u root -p 查看下神奇的mysql系统变量及其值: show variables like '%character%'; //记住分号哦, ...
- 从零开始学 Web 之 Ajax(四)接口文档,验证用户名唯一性案例
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- mysql真的不能做搜索引擎吗?
大家都对电商的商品查询并不陌生,比如我们想根据商品名称查询所有商品信息. 有些技术的童鞋第一念头是搜索引擎:有些技术的童鞋第一念头是模糊查询,如like?(如果商品信息存放到mysql里,我们一般使用 ...