c++ 日志输出库 spdlog 简介(2)
继续上一篇,example.cpp解析。
1、set_pattern 自定义日志格式
官方参考:https://github.com/gabime/spdlog/wiki/3.-Custom-formatting
可以为所有的log制定格式,也可以为指定的log制定格式,注意下面代码中rotating_logger为指针变量。
auto rotating_logger = spd::rotating_logger_mt("some_logger_name", "logs/rotating.txt", , );
// Customize msg format for all messages
spd::set_pattern("*** [%H:%M:%S %z] [thread %t] %v ***");
rotating_logger->info("This is another message with custom format");
//Customize msg format for a specific logger object:
rotating_logger->set_pattern("[%H:%M:%S %f] [thread %t] %v ***");
详细的格式说明在github上有,在此截图如下:
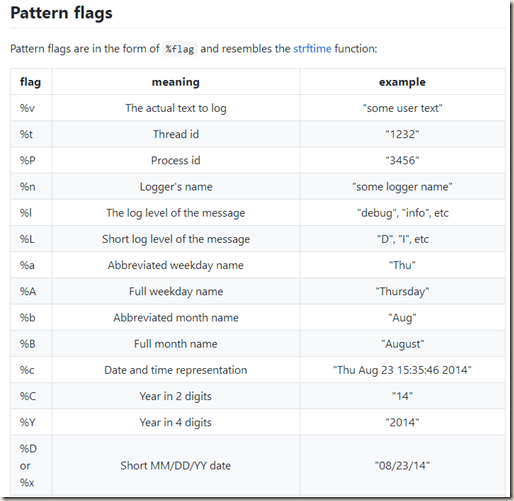
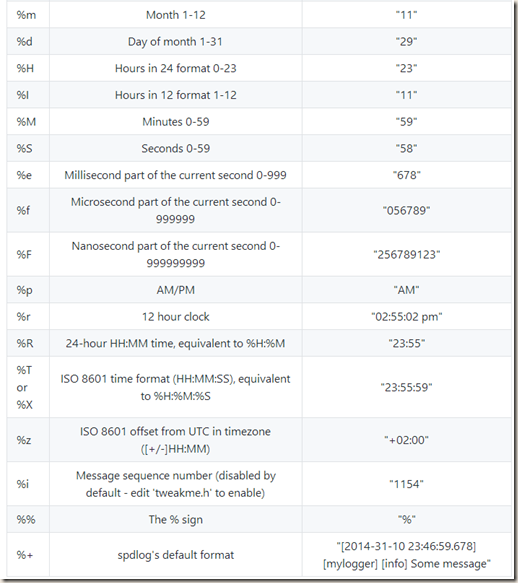
2、set_level 设置日志级别
低于设置级别的日志将不会被输出。各level排序,数值越大级别越高:
// Runtime log levels
spd::set_level(spd::level::info); //Set global log level to info
console->debug("This message should not be displayed!");
console->set_level(spd::level::debug); // Set specific logger's log level
console->debug("This message should be displayed..");
第一行日志debug级别低于设定的级别info,在level为info时不会被输出。
第二行日志debug级别与设定的级别相同,所以可以显示出来。

typedef enum
{
trace = ,
debug = ,
info = ,
warn = ,
err = ,
critical = ,
off =
} level_enum;
3、编译阶段修改日志输出级别 SPDLOG_TRACE 和 SPDLOG_DEBUG
官方参考:https://github.com/gabime/spdlog/wiki/8.-Tweaking
当定义了宏定义 SPDLOG_TRACE_ON 时,可以用SPDLOG_TRACE语句输出trace级别的log,SPDLOG_DEBUG_ON也是同理。
#define SPDLOG_TRACE_ON
#define SPDLOG_DEBUG_ON
// Compile time log levels
// define SPDLOG_DEBUG_ON or SPDLOG_TRACE_ON
SPDLOG_TRACE(console, "Enabled only #ifdef SPDLOG_TRACE_ON..{} ,{}", , 3.23);
SPDLOG_DEBUG(console, "Enabled only #ifdef SPDLOG_DEBUG_ON.. {} ,{}", , 3.23);
需要注意的是,如果不使用set_level命令设置log的输出级别,默认级别就是info级别,此时即使定义了这两个宏,debug和trace信息也不会输出。所以使用时需要先用set_level把级别设为trace才可以。
console->set_level(spd::level::trace); // Set specific logger's log level
// Compile time log levels
// define SPDLOG_DEBUG_ON or SPDLOG_TRACE_ON
SPDLOG_TRACE(console, "Enabled only #ifdef SPDLOG_TRACE_ON..{} ,{}", , 3.23);
SPDLOG_DEBUG(console, "Enabled only #ifdef SPDLOG_DEBUG_ON.. {} ,{}", , 3.23);
以下是输出结果:

注意trace和debug的输出不太一样,打开spdlog.h,查看SPDLOG_TRACE的定义,可以发现trace中还输出了文件的位置(“__FILE__”)。
#ifdef SPDLOG_TRACE_ON
# define SPDLOG_STR_H(x) #x
# define SPDLOG_STR_HELPER(x) SPDLOG_STR_H(x)
# ifdef _MSC_VER
# define SPDLOG_TRACE(logger, ...) logger->trace("[ " __FILE__ "(" SPDLOG_STR_HELPER(__LINE__) ") ] " __VA_ARGS__)
# else
# define SPDLOG_TRACE(logger, ...) logger->trace("[ " __FILE__ ":" SPDLOG_STR_HELPER(__LINE__) " ] " __VA_ARGS__)
# endif
#else
# define SPDLOG_TRACE(logger, ...) (void)
#endif #ifdef SPDLOG_DEBUG_ON
# define SPDLOG_DEBUG(logger, ...) logger->debug(__VA_ARGS__)
#else
# define SPDLOG_DEBUG(logger, ...) (void)
#endif
4、同步和异步设置 Asynchronous logging
官方说明:https://github.com/gabime/spdlog/wiki/6.-Asynchronous-logging
默认情况下是不开启异步模式的,开启异步模式方式如下:
size_t q_size = ; //queue size must be power of 2
spdlog::set_async_mode(q_size);
队列大小:
队列占用的内存 = 设置的队列大小 * slot的大小, 64位系统下slot大小为104字节。由此可根据系统的log输出总量来确定队列大小。

队列机制:
异步模式下,所有输出的日志将先存入队列,再由工作者线程从队列中取出日志并输出。当队列存满时,需要根据设置好的队列存满策略来处置新来的日志(阻塞消息或者丢弃消息)。如果工作者线程中抛出了异常,向队列写入下一条日志时异常会再次抛出,可以在写入队列时捕捉工作者线程的异常。

队列存满时(Full queue policy)两种应对方式:
(1)阻塞新来的日志,直到队列中有剩余空间。这是默认的处理方式。
(2)丢弃新来的日志。如下:
spdlog::set_async_mode(q_size, spdlog::async_overflow_policy::discard_log_msg)
两种应对方式如下:
// Async overflow policy - block by default.
//
enum class async_overflow_policy
{
block_retry, // Block / yield / sleep until message can be enqueued
discard_log_msg // Discard the message it enqueue fails
};
5、处理spdlog的异常 set_error_handler
官方说明:https://github.com/gabime/spdlog/wiki/Error-handling
当输出日志时发生异常时,spdlog会向std::err 打印一条语句,为了避免输出的异常语句刷屏,打印频率被限制在每分钟一条。
下面函数执行时,由于最后一条输出log的语句中四个参数只给了一个,所以spdlog调用了异常处理函数,输出异常。
void err_handler_example()
{
//can be set globaly or per logger(logger->set_error_handler(..))
spdlog::set_error_handler([](const std::string& msg)
{
std::cerr << "my err handler: " << msg << std::endl;
});
spd::get("console")->info("some invalid message to trigger an error {}{}{}{}", );
}

6、apply_all 使所有的logger同时输出
所有注册过的logger都会输出End of example 这句话,代表程序结束。
// Apply a function on all registered loggers
spd::apply_all([&](std::shared_ptr<spdlog::logger> l)
{
l->info("End of example.");
});
7、drop -- 释放logger
在程序结束时,应该调用drop_all() 释放所有logger。
There is a bug in VS runtime that cause the application dead lock when it exits. If you use async logging, please make sure to call spdlog::drop_all() before main() exit. If some loggers are not in the registry, those should be released manually as well. stackoverflow: std::thread join hangs if called after main exits when using vs2012 rc
// Release and close all loggers
spdlog::drop_all();
或者单独drop某个logger
spd::drop("console");
spd::drop("basic_logger");
c++ 日志输出库 spdlog 简介(2)的更多相关文章
- c++ 日志输出库 spdlog 简介(1)
参考文章: log库spdlog简介及使用 - 网络资源是无限的 - CSDN博客 http://blog.csdn.net/fengbingchun/article/details/78347105 ...
- c++ 日志输出库 spdlog 简介(4)- 多线程txt输出日志
在上一节的代码中加入了向文本文件中写入日志的代码: UINT CMFCApplication1Dlg::Thread1(LPVOID pParam) { try{ size_t q_size = ; ...
- c++日志输出库 spdlog 简介(3)多线程控制台输出日志
spdlog源码分析:https://www.cnblogs.com/eskylin/p/6483199.html spdlog的异步模式使得spdLog可以支持多线程,于是写了一个多线程的小例子: ...
- 细说Java主流日志工具库
概述 在项目开发中,为了跟踪代码的运行情况,常常要使用日志来记录信息. 在Java世界,有很多的日志工具库来实现日志功能,避免了我们重复造轮子. 我们先来逐一了解一下主流日志工具. java.util ...
- Haproxy安装配置及日志输出问题
简介: 软件负载均衡一般通过两种方式来实现:基于操作系统的软负载实现和基于第三方应用的软负载实现.LVS就是基于Linux操作系统实现的一种软负载,HAProxy就是开源的并且基于第三应用实现的软负载 ...
- Java主流日志工具库
在项目开发中,为了跟踪代码的运行情况,常常要使用日志来记录信息.在Java世界,有很多的日志工具库来实现日志功能,避免了我们重复造轮子.我们先来逐一了解一下主流日志工具. 1.java.util.lo ...
- 基于java.util.logging实现轻量级日志记录库(增加根据当前类class初始化,修复线程池模型(javaEE)下的堆栈轨迹顺序与当前调用方法不一致问题)
前言: 本章介绍自己写的基于java.util.logging的轻量级日志记录库(baseLog). 该版本的日志记录库犹如其名,baseLog,是个实现日志记录基本功能的小库,适合小型项目使用,方便 ...
- python的日志模块:logging;django的日志系统;django日志输出时间修改
Django的log,主要是复用Python标准库中的logging模块,在settings.py中进行配置 源代码 1.__init__.py包含以下类: StreamHandler Formatt ...
- Python 日志输出
昨天的任务是需要记录各操作的性能数据,所以需要用这种格式来输出日志:{"adb_start_time": 1480040663, "tag_name": &qu ...
随机推荐
- 接口测试工具postman/jmeter基本使用
一.接口的分类: 最常用的两种接口webservice接口和http api接口:1.webservice接口走soap协议通过http传输,请求报文和返回报文都是XML格式,现在测试的时候都通过工具 ...
- jquery.cookie用法及其注意点
jquery.cookie是一个轻量级的cookie插件,由于已被封装好,可拿来即用. 基本的创建.读取.删除见另一篇文章 浅谈localStorage.sessionStorage 与cookie ...
- LevelDB源码分析-Get
Get LevelDB提供了Get接口用于给定key的查找: Status DBImpl::Get(const ReadOptions &options, const Slice &k ...
- servlet3.1
Servlet3.1新增的新特性强制更改sessionId 由HttpServletRequest 的changeSessionId()方法实现 非阻塞式IO 非阻塞式IO我们应该知道Servlet底 ...
- 数据库类型空间效率探索(五)- decimal/float/double/varchar
以下测试为userinfo增加一列,列类型分别为decimal.float.double.varchar.由于innodb不支持optimize,所以每次测试,都会删除表test.userinfo,重 ...
- GitLab代码行数统计--统计增加与删除行数
#!/bin/bashmaster_dev='master'date_star='2018-11-01'date_end='2018-11-30'path1=`find /home/gitlab_da ...
- js数组去除重复数据
一个有重复数据的数组,准备一个空数组,遍历有重复数据的数组同时用indexOf对比那个空数组判断是否有一样的,不一样的push进去空数组 let arr = dataInfo.map(item =&g ...
- [leetcode]31. Next Permutation下一个排列
Implement next permutation, which rearranges numbers into the lexicographically next greater permuta ...
- js学习(4) 函数
JavaScript有三种声明函数的方法 (1)function命令 function print(s) { console.log(s); } (2)函数表达式 1.var print = func ...
- 七、eclipse添加离线约束,使不联网也能有一些代码的提示,例如dubbo
eclipse添加离线约束,使不联网也能有一些代码的提示,例如dubbo 1.将dubbo.xsd文件放到一个无中文目录下 2.eclipse->windows->preferences- ...