洗礼灵魂,修炼python(51)--爬虫篇—变色龙般的伪装
变色龙原理
变色龙这种动物想必大家都了解,它们会根据周遭环境的局势来改变自己的颜色,伪装自己。
那么爬虫有这种技能吗?当然是有的,先不着急说这个问题。
从上一篇开始,你有没有想过,站在网站管理的角度,如果在同一时间段,大家全部利用爬虫程序对自己的网站进行爬取操作,那么这网站服务器能不能承受这种负荷?肯定不能啊,如果严重超负荷则会时服务器宕机(死机)的,对于一些商业型的网站,宕机一秒钟的损失都是不得了的,这不是一个管理员能承担的,对吧?那管理员会网站服务器做什么来优化呢?我想到的是,写一个脚本,当检测到一个IP访问的速度过快,报文头部并不是浏览器的话,那么就拒绝服务,或者屏蔽IP等,这样就可以减少服务器的负担并让服务器正常进行。
那么既然服务器做好了优化,但你知道这是对爬虫程序的优化,如果你是用浏览器来作为一个用户访问的话,服务器是不会拦截或者屏蔽你的,它也不敢拦你,为什么,你现在是客户,它敢拦客户,不想继续经营了是吧?所以对于如果是一个浏览器用户的话,是可以正常访问的。
所以想到方法了吗?是的,把程序伪造成一个浏览器啊,前面说过服务器会检测报文头部信息,如果是浏览器就不正常通行,如果是程序就拒绝服务。
那么报文是什么?头部信息又是什么?详细的就不解释了,这涉及到http协议和tcp/ip三次握手等等的网络基础知识,感兴趣的自己百度或者谷歌吧。
本篇博文不扯远了,只说相关的重点——怎么查看头部信息。
User-Agent
其实我想有些朋友可能有疑惑,服务器是怎么知道我们使用的是程序或者浏览器呢?它用什么来判断的?这么玄乎?不玄乎,但确实可以,好的,我就用博客园的当前我正在编辑的博文页面为例:
我使用的是火狐浏览器,鼠标右键-查看元素(有的浏览器是审查元素或者检查)
网络(有的是network):
出现报文:

双击它, 右边则会出现详细的信息,选择消息头(有的是headers)

找到请求头(request headers),其中的User-Agent就是我们头部信息:
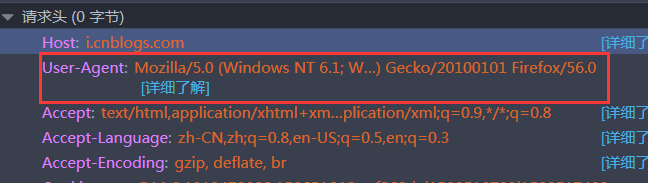
看到是显示的
# -*- coding:utf-8 -*- import urllib url='http://www.baidu.com' #百度网址 html=urllib.urlopen(url)#利用模块urllib里的urlopen方法打开网页 print(dir(html)) #查看对象html的方法 print(urllib.urlopen) #查看对象urllib.urlopen的方法 print(urllib.urlopen()) #查看对象urllib.urlopen实例化后的方法
Traceback (most recent call last):
File "D:\programme\PyCharm 5.0.3\helpers\pycharm\utrunner.py", line 121, in <module>
modules = [loadSource(a[0])]
File "D:\programme\PyCharm 5.0.3\helpers\pycharm\utrunner.py", line 41, in loadSource
module = imp.load_source(moduleName, fileName)
File "G:\programme\Python\python project\test.py", line 8, in <module>
print(urllib.urlopen())
TypeError: urlopen() takes at least 1 argument (0 given)
['__doc__', '__init__', '__iter__', '__module__', '__repr__', 'close', 'code',
'fileno', 'fp', 'getcode', 'geturl', 'headers', 'info', 'next', 'read', 'readline', 'readlines', 'url']
<function urlopen at 0x0297FD30>
由此,这里就必须注意,只有当urllib.urlopen()实例化后才有其后面的方法,urlopen会返回一个类文件对象,urllib.urlopen只是一个对象,而urllib.urlopen()必须传入一个参数,不然则报错。
urlopen提供了如下方法:
- read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
- info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息
- getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到
- geturl():返回请求的url
- headers:返回请求头部信息
- code:返回状态码
- url:返回请求的url
好的,详细的自己去研究了,本篇博文的重点终于来了,伪装一个头部信息
伪造头部信息
由于urllib没有伪造头部信息的方法,所以这里得使用一个新的模块,urllib2
# -*- coding:utf-8 -*-
import urllib2
url='http://www.baidu.com'
head={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
} #头部信息,必须是一个字典
html=urllib2.Request(url,headers=head)
result=urllib2.urlopen(html)
print result.read()
或者你也可以这样:
# -*- coding:utf-8 -*-
import urllib2
url='http://www.baidu.com'
html=urllib2.Request(url)
html.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0') #此时注意区别格式
result=urllib2.urlopen(html)
print result.read()
结果都一样的,我也就不展示了。
按照上面的方法就可以伪造请求头部信息。
那么你说,我怎么知道伪造成功了?还有不伪造头部信息时,显示的到底是什么呢?介绍一个抓包工具——fidder,用这个工具就可以查看到底报文头部是什么了。这里就不展示了,自己下去常识了。并且我可以确切的保证,确实伪造成功了。
这样,我们就把爬虫代码升级了一下,可以搞定普通的反爬虫限制。
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站站长有异议,请联系我立即删除
洗礼灵魂,修炼python(51)--爬虫篇—变色龙般的伪装的更多相关文章
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- 洗礼灵魂,修炼python(70)--爬虫篇—补充知识:json模块
在前面的某一篇中,说完了pickle,但我相信好多朋友都不懂到底有什么用,那么到了爬虫篇,它就大有用处了,而和pickle很相似的就是JSON模块 JSON 1.简介 1)JSON(JavaScrip ...
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(50)--爬虫篇—基础认识
爬虫 1.什么是爬虫 爬虫就是昆虫一类的其中一个爬行物种,擅长爬行. 哈哈,开玩笑,在编程里,爬虫其实全名叫网络爬虫,网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者 ...
- 洗礼灵魂,修炼python(85)-- 知识拾遗篇 —— 深度剖析让人幽怨的编码
编码 这篇博文的主题是,编码问题,老生常谈的问题了对吧?从我这一套的文章来看,前面已经提到好多次编码问题了,的确这个确实很重要,这可是难道了很多能人异士的,当你以为你学懂了,在研究爬虫时你发现你错了, ...
随机推荐
- 【2019北京集训3】逻辑 树剖+2-sat
题目大意:有一颗有$m$个叶子节点的二叉树. 对于叶子节点$i$,$x[i]=(a[i]\ xor\ V_{p[i]})or(b[i]\ xor\ V_{q[i]})$ 对于非叶子节点$i$,$x[i ...
- [EXP]Huawei Router HG532e - Command Execution
#!/bin/python ''' Author : Rebellion Github : @rebe11ion Twitter : @rebellion ''' import urllib2,req ...
- 使用Chrome开发者工具调试Android端内网页(微信,QQ,UC,App内嵌页等)
使用Chrome开发者工具调试Android端内网页(微信,QQ,UC,App内嵌页等) 前言 移动端页面调试一直是好多朋友头疼的问题,iOS 由于其封闭的特性和整体较高的性能,整体适配相对好做,调试 ...
- 【深入 MongoDB 开发】使用正确的姿势连接分片集群
MongoDB分片集群(Sharded Cluster)通过将数据分散存储到多个分片(Shard)上,来实现高可扩展性.实现分片集群时,MongoDB 引入 Config Server 来存储集群的元 ...
- Ubuntu16.04 安装 wps (不推荐安装)
一.下载与安装 1.下载:WPS For Linux 下载地址:http://community.wps.cn/download/ , 下载 wps-office_10.1.0.5672~a ...
- 移动 Ubuntu16.04 桌面左侧的启动器到屏幕底部
与其他 Linux 发行版不同,Ubuntu 多年来一直使用 Unity 做桌面环境,该环境的最突出特点就是桌面左侧有一个启动器栏(Launcher).从 16.04 版本开始,Ubuntu 提供了一 ...
- linux下配置nginx反向代理例子
官方说明: 例子: 虚拟机ip:192.168.85.3,物理机VMware Network Adapter VMnet8 ip:192.168.85.1 1,准备tomcat 准备一tomcat, ...
- TCP/IP 笔记 - 传输控制协议
与UDP不同,TCP提供面向连接的.可靠的.基于字节流的传输层协议,且提供差错纠正. TCP传输的概念 对与分组丢失和比特差错的处理方法,最直接的方法是重发分组,直到它被正确接收. 这需要一种方法来判 ...
- [Golang] GoConvey测试框架使用指南
GoConvey 是一款针对Golang的测试框架,可以管理和运行测试用例,同时提供了丰富的断言函数,并支持很多 Web 界面特性. GoConvey 网站 : http://smartystreet ...
- javascript中的iterable
遍历Array可以采用下标循环,遍历Map和Set就无法使用下标.为了统一集合类型,ES6标准引入了新的iterable类型,Array.Map和Set都属于iterable类型. 具有iterabl ...