SparkR-Install
SparkR-Install
标签:too 下载 安装jdk context writing 磁盘 anti 1.5 products
1.下载R
https://cran.r-project.org/src/base/R-3/

1.2 环境变量配置:
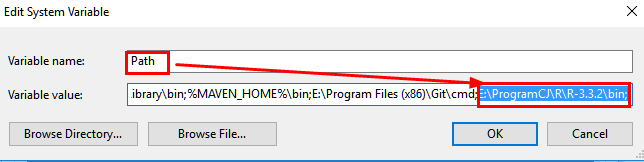
1.3 测试安装:
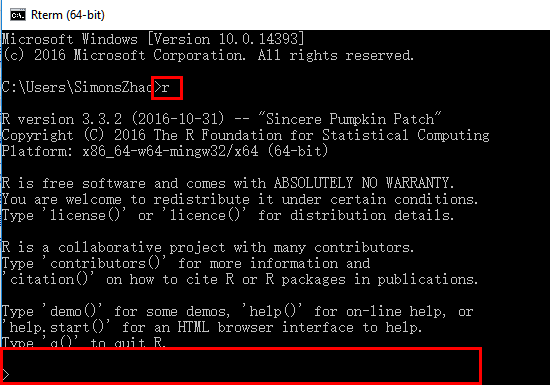
2.下载Rtools33
https://cran.r-project.org/bin/windows/Rtools/
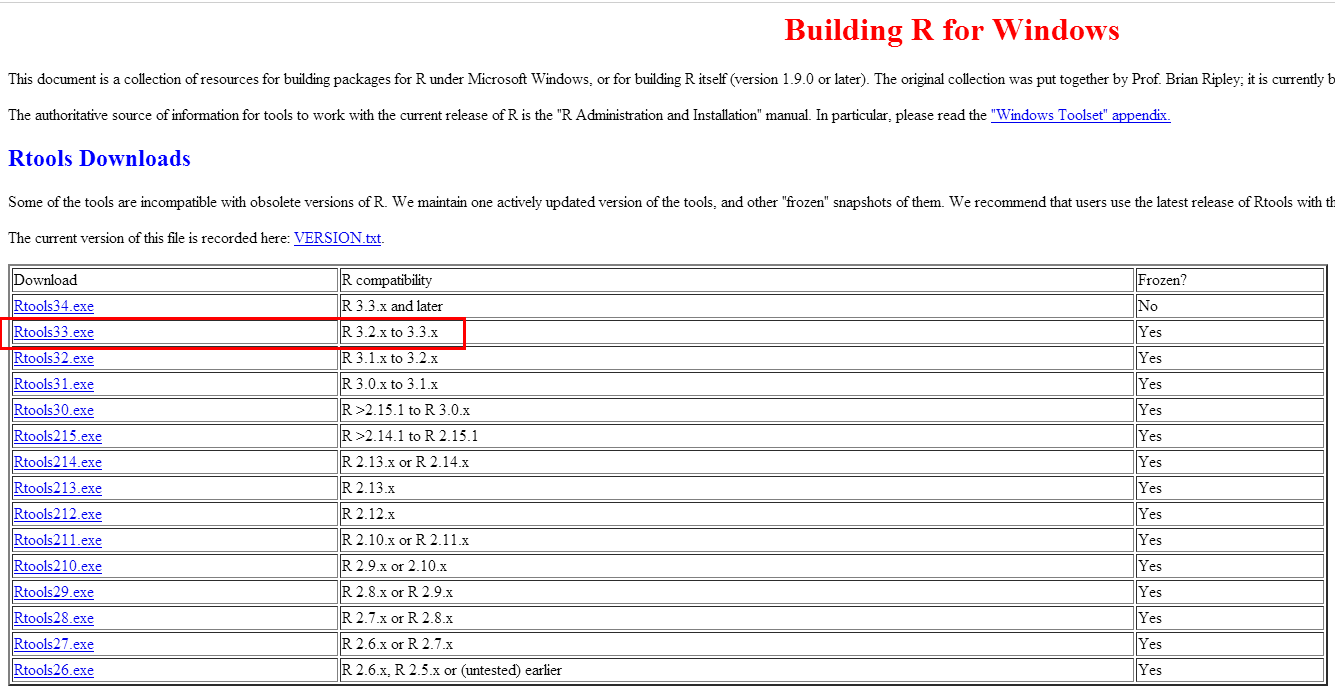
2.1 配置环境变量
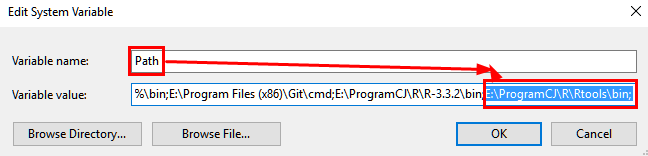
2.2 测试:
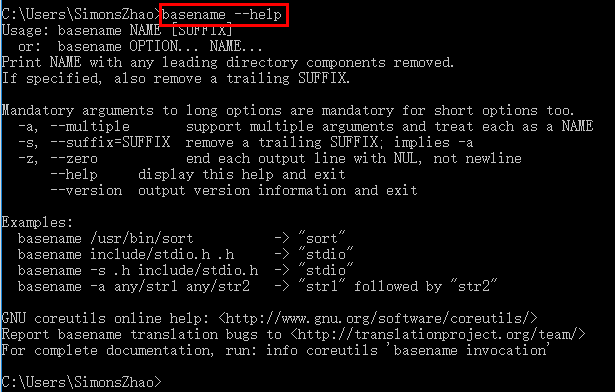
3.安装RStudio
https://www.rstudio.com/products/rstudio/download/ 直接下一步即可安装
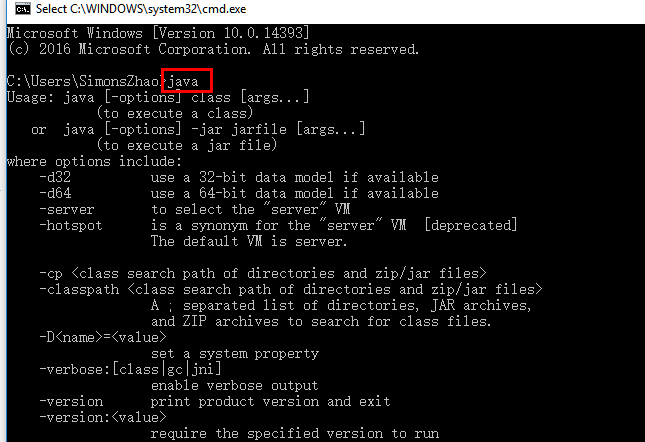
4.安装JDK并设置环境变量
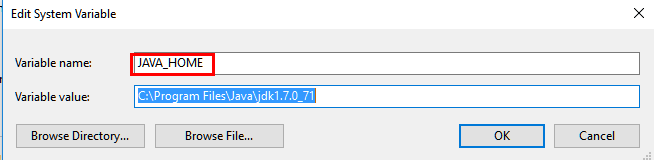
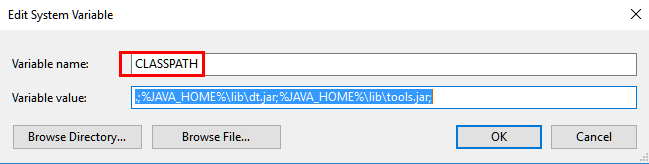
4.1环境变量配置:

4.2测试:

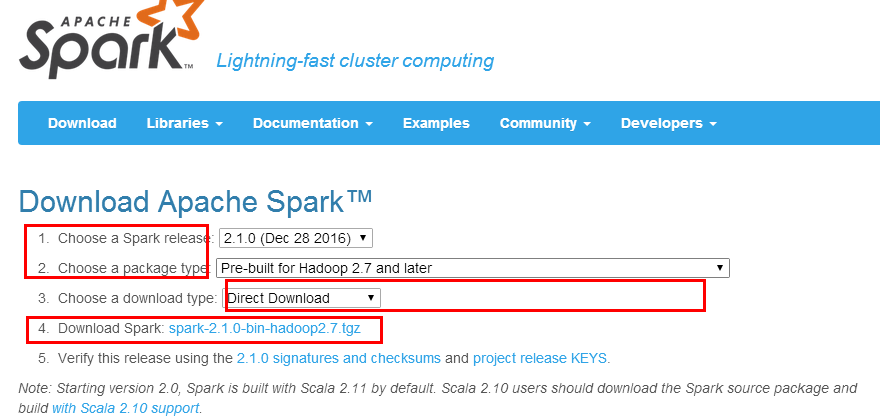
5.下载Spark安装程序
5.1 URL: http://spark.apache.org/downloads.html
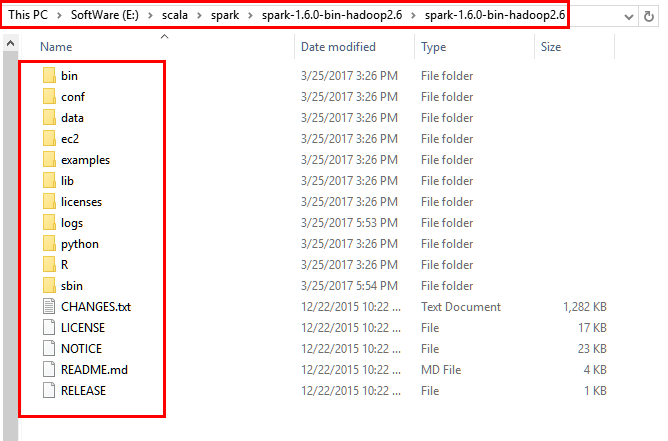
5.2解压到本地磁盘的对应目录
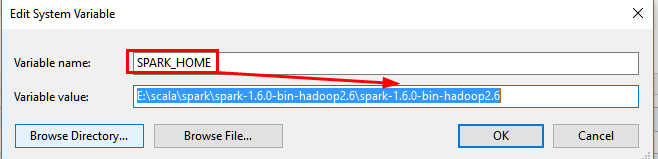
6.安装Spark并设置环境变量

7.测试SparkR
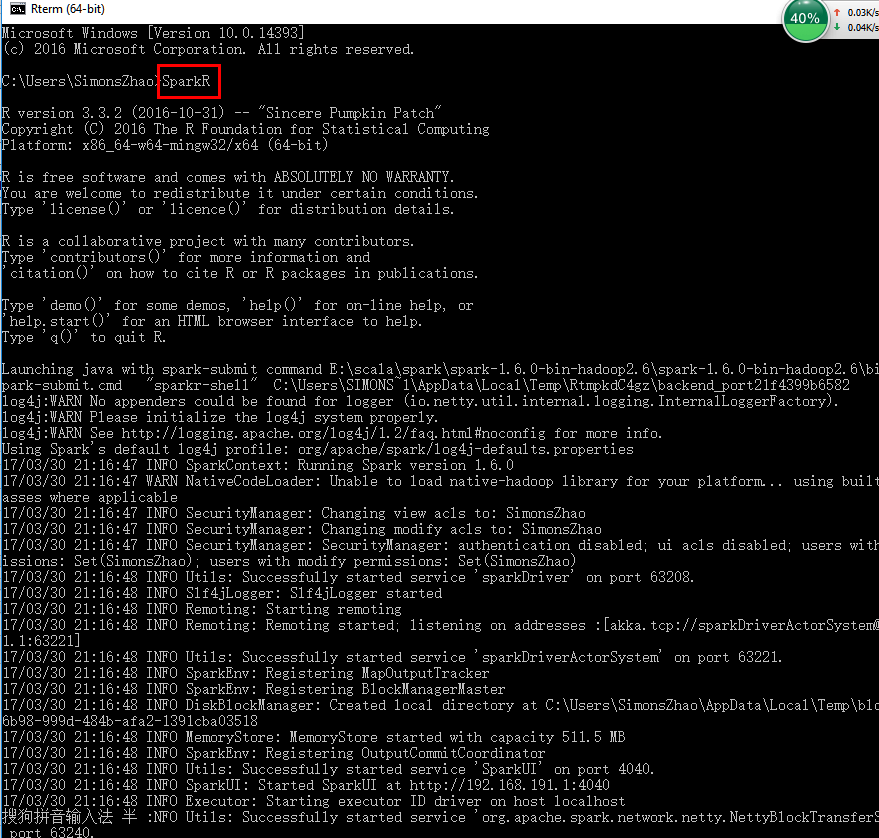
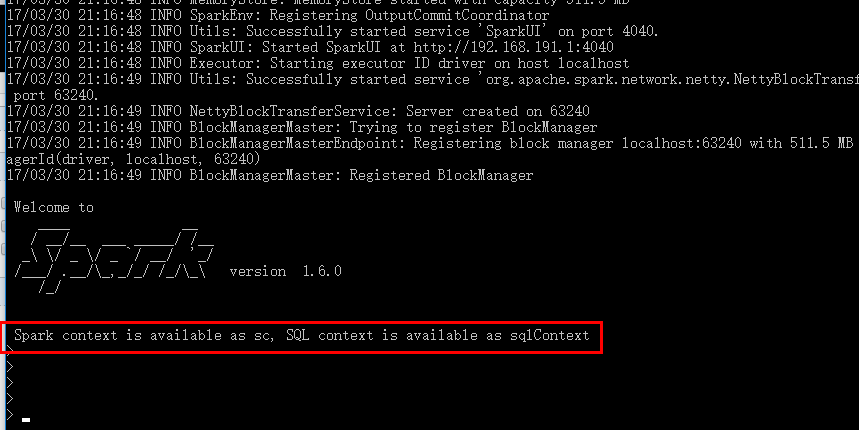
注意:如果发现了提示 WARN NativeCodeLader:Unable to load native-hadoop library for your platform.....using
builtin-java classes where applicable 需要安装本地的hadoop库
8.下载hadoop库并安装
http://hadoop.apache.org/releases.html
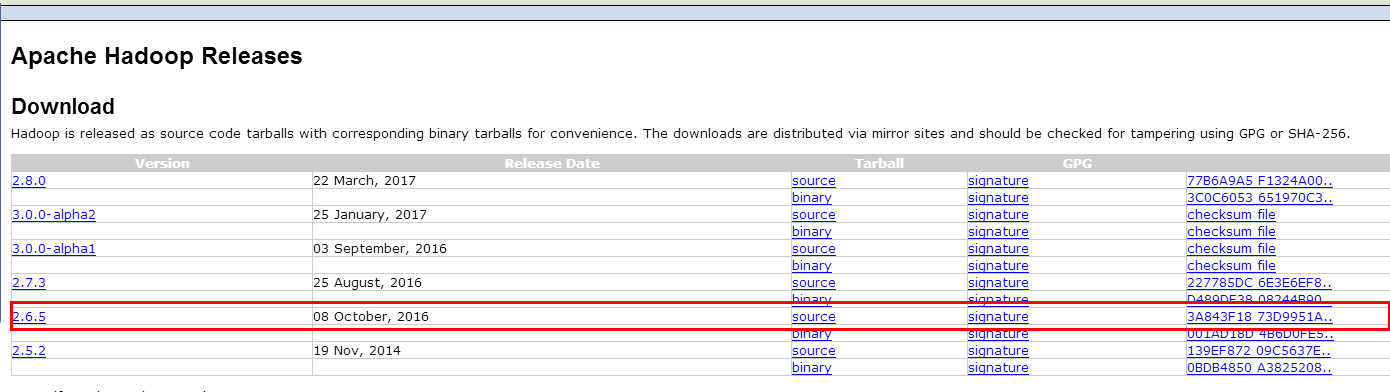
9.设置hadoop环境变量
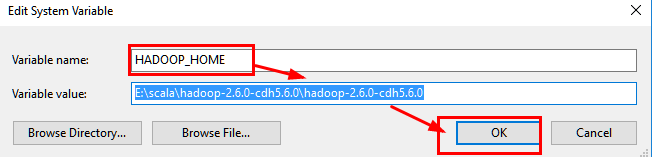
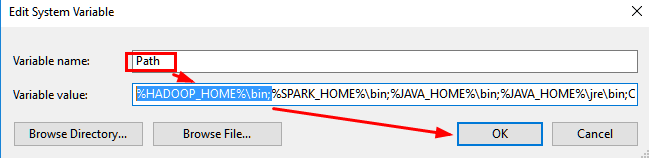
10.重新测试SparkR
10.1 如果测试时候出现以下提示,需要修改log4j文件INFO为WARN,位于\spark\conf下

10.2 修改conf中的log4j文件:
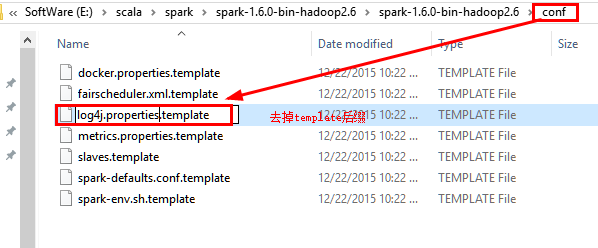
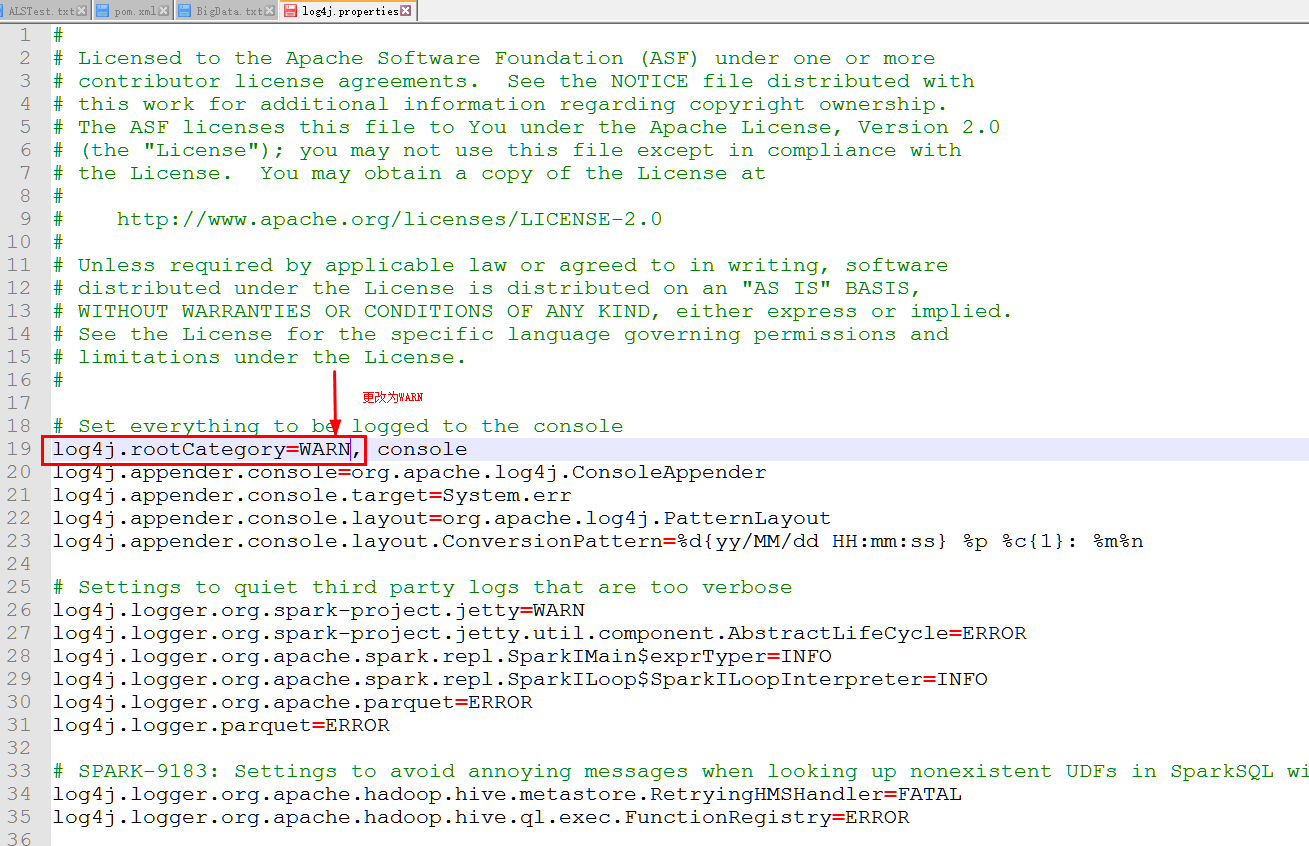
10.3 重新运行SparkR
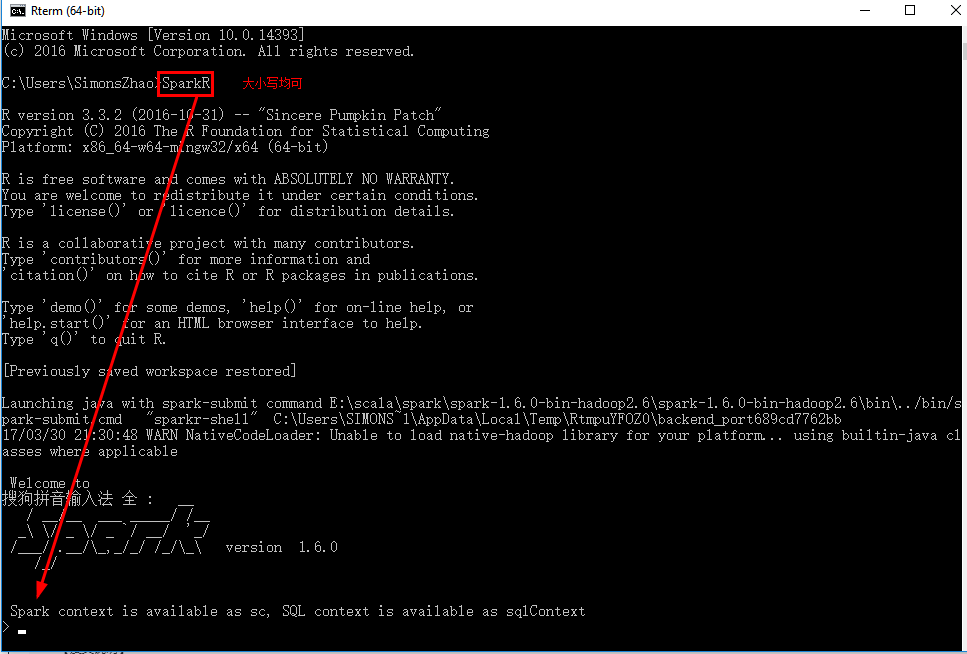
11.运行SprkR代码
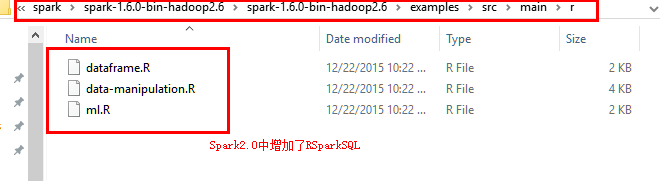
在Spark2.0中增加了RSparkSql进行Sql查询
dataframe为数据框操作
data-manipulation为数据转化
ml为机器学习
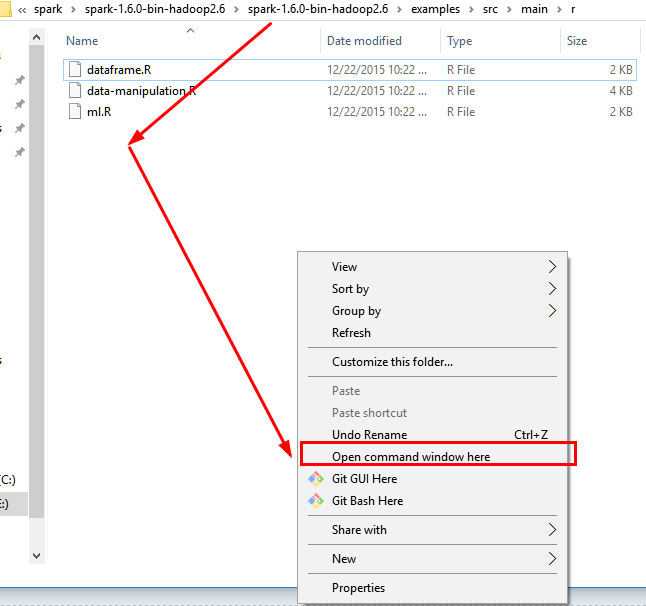
11.1 使用crtl+ALT+鼠標左鍵 打开控制台在此文件夹下
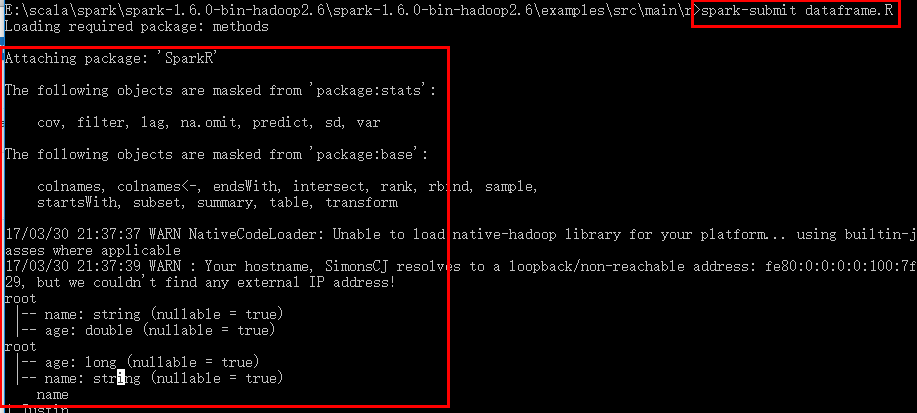
11.2 执行spark-submit xxx.R文件即可
12.安装SparkR包
12.1 将spark安装目录下的R/lib中的SparkR文件拷贝到..\R-3.3.2\library中,注意是将整个Spark文件夹,而非里面每一个文件。
源文件夹:
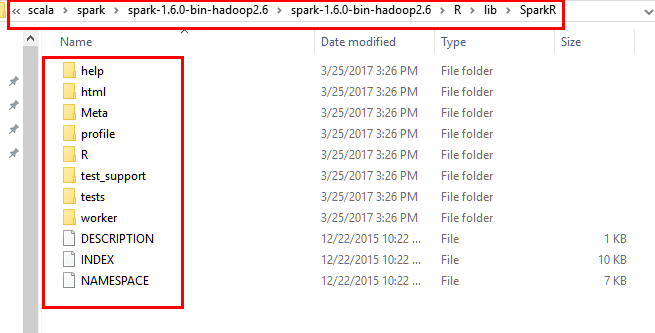
目的文件夹:
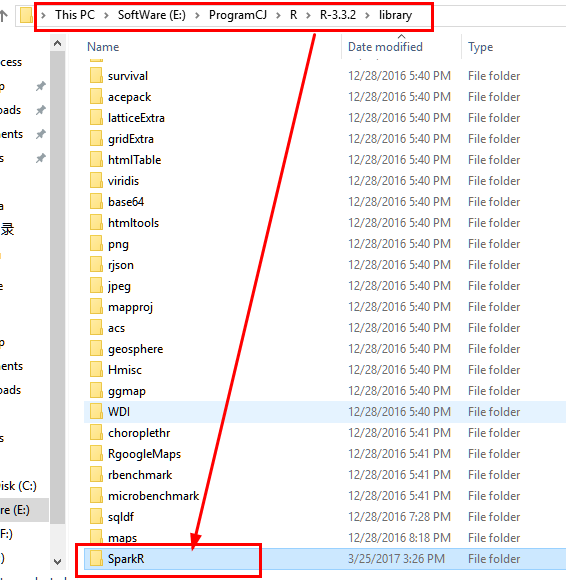
12.2 在RStudio中打开SparkR文件并运行代码dataframe.R文件,采用Ctrl+Enter一行行执行即可
SparkR语言的dataframe.R源代码如下
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# library(SparkR) # Initialize SparkContext and SQLContext
sc <- sparkR.init(appName="SparkR-DataFrame-example")
sqlContext <- sparkRSQL.init(sc) # Create a simple local data.frame
localDF <- data.frame(name=c("John", "Smith", "Sarah"), age=c(19, 23, 18)) # Convert local data frame to a SparkR DataFrame
df <- createDataFrame(sqlContext, localDF) # Print its schema
printSchema(df)
# root
# |-- name: string (nullable = true)
# |-- age: double (nullable = true) # Create a DataFrame from a JSON file
path <- file.path(Sys.getenv("SPARK_HOME"), "examples/src/main/resources/people.json")
peopleDF <- read.json(sqlContext, path)
printSchema(peopleDF) # Register this DataFrame as a table.
registerTempTable(peopleDF, "people") # SQL statements can be run by using the sql methods provided by sqlContext
teenagers <- sql(sqlContext, "SELECT name FROM people WHERE age >= 13 AND age <= 19") # Call collect to get a local data.frame
teenagersLocalDF <- collect(teenagers) # Print the teenagers in our dataset
print(teenagersLocalDF) # Stop the SparkContext now
sparkR.stop()
13.Rsudio 运行结果
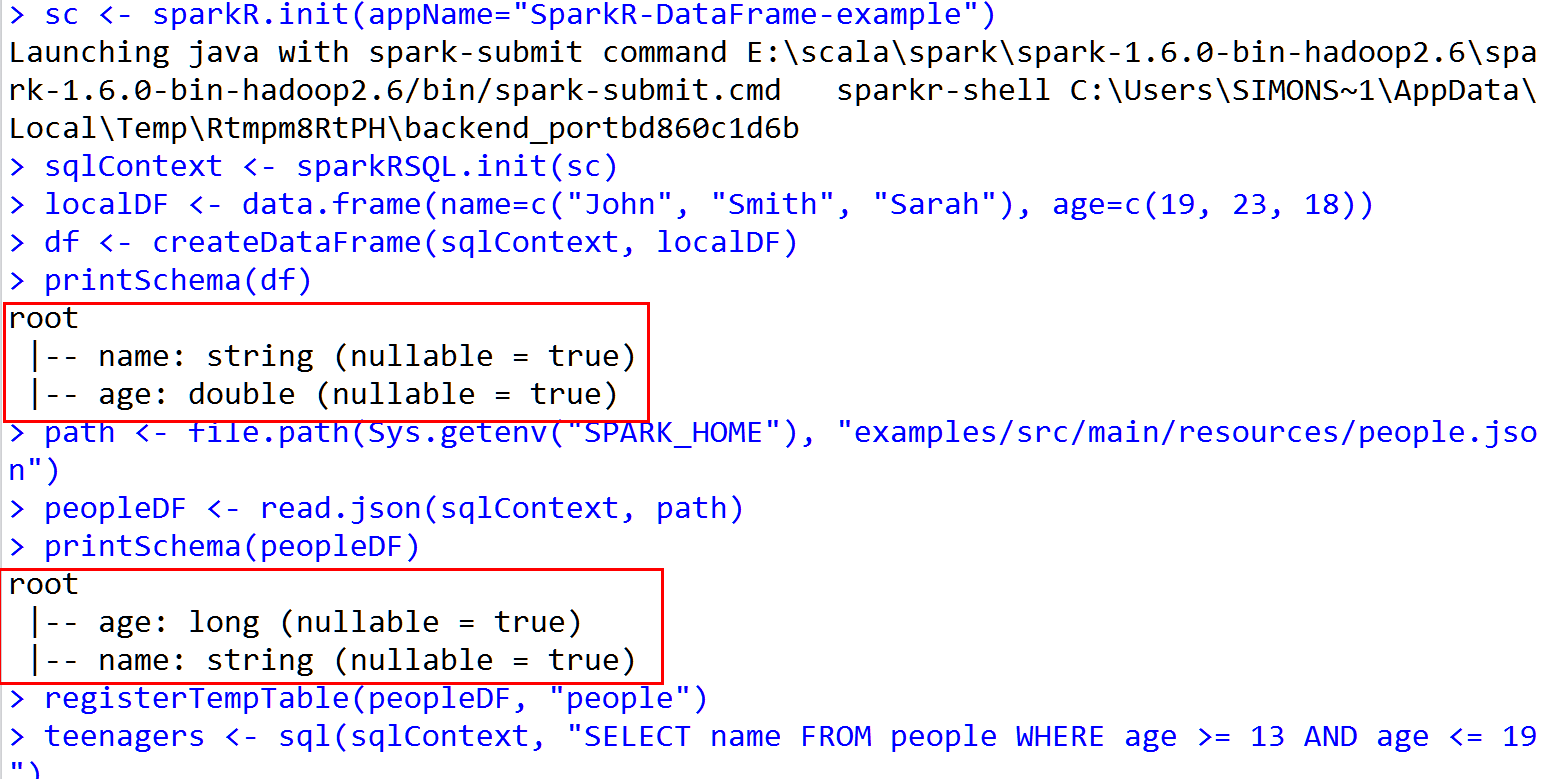
END~
SparkR-Install的更多相关文章
- 在CentOS上安装并运行SparkR
环境配置—— 操作系统:CentOS 6.5 JDK版本:1.7.0_67 Hadoop集群版本:CDH 5.3.0 安装过程—— 1.安装R yum install -y R 2.安装curl-de ...
- Apache Spark技术实战之5 -- SparkR的安装及使用
欢迎转载,转载请注明出处,徽沪一郎. 概要 根据论坛上的信息,在Sparkrelease计划中,在Spark 1.3中有将SparkR纳入到发行版的可能.本文就提前展示一下如何安装及使用SparkR. ...
- shiny server SparkR web展示界面(二)
1. 需要先在Mac OS中安装好R,Rstudio中,这个比较简单,掠过 2. 下载编译好的spark(spark-2.0.0-bin-hadoop2.6.tgz)可以在Spark官网下载到你所需 ...
- shiny server SparkR web展示界面(一)
1. shiny server简介 shiny-server是一种可用把R 语言以web形式展示的服务,下面就讲讲如何在自己的服务器上构建Shiny Server.下一篇主要介绍如何集成sparkR后 ...
- CentOS下SparkR安装部署:hadoop2.7.3+spark2.0.0+scale2.11.8+hive2.1.0
注:之前本人写了一篇SparkR的安装部署文章:SparkR安装部署及数据分析实例,当时SparkR项目还没正式入主Spark,需要自己下载SparkR安装包,但现在spark已经支持R接口,so更新 ...
- SparkR安装部署及数据分析实例
1. SparkR的安装配置 1.1. R与Rstudio的安装 1.1.1. R的安装 我们的工作环境都是在Ubuntu下操作的,所以只介绍Ubuntu下安装R的方法 ...
- Apache Spark 2.2.0 中文文档 - SparkR (R on Spark) | ApacheCN
SparkR (R on Spark) 概述 SparkDataFrame 启动: SparkSession 从 RStudio 来启动 创建 SparkDataFrames 从本地的 data fr ...
- sparkR介绍及安装
sparkR介绍及安装 SparkR是AMPLab发布的一个R开发包,为Apache Spark提供了轻量的前端.SparkR提供了Spark中弹性分布式数据集(RDD)的API,用户可以在集群上通过 ...
- centos 部署 SparkR
---恢复内容开始--- 环境配置—— 操作系统:CentOS 6.5 JDK版本:1.7.0_67 Hadoop集群版本:CDH 5.3.0 安装过程—— 1.(1)安装R yum install ...
- SparkR安装
一.在虚拟机中安装R语言 1.下载R语言压缩包R-3.2.2.tar.gz,放在目标目录下 ★在此特别提醒,尽量安装3.2.?版本的R,更高版本的R容易出现依赖包安装不全的问题. # mv R-3.2 ...
随机推荐
- Java并发编程(九)-- 进程饥饿和公平锁
上一章已经提到“如果一个进程被多次回滚,迟迟不能占用必需的系统资源,可能会导致进程饥饿”,本文我们详细的介绍一下“饥饿”和“公平”. Java中导致饥饿的原因 在Java中,下面三个常见的原因会导致线 ...
- vue给methods中的方法传入当前点击行的值
<template> <!-- 在template中,只能存在一个根组件 --> <div class="event"> <ul> ...
- (转)为什么wait(),notify()和notifyAll()必须在同步块或同步方法中调用
我们常用wait(),notify()和notifyAll()方法来进行线程间通信.线程检查一个条件后就行进入等待状态,例如,在“生产者-消费者”模型中,生产者线程发现缓冲区满了就等待,消费者线程通过 ...
- 考前停课集训 Day4 雷
Day 4 今天Rating掉了两百多 为什么呢 因为是真实力打的 倒数第三 没什么好说的了 这才是我的真实水平 强的人一如既往强 作弊的人一落千丈. 只有我.是的,只有我. 被老师嘲讽了,哎,您真的 ...
- sublime text3中emmet插件的使用
首先,想要快速编码需 要在编辑器中安装常用插件,下面是emmet插件的使用: html5文档结构的生成方式: 1).!+tab键 2).html:5 +tab键 头部head中meta字符集的生成: ...
- PAT Basic 1008
1008 数组元素循环右移问题 (20 分) 一个数组A中存有N(>0)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移M(≥0)个位置,即将A中的数据由(A0A1⋯AN ...
- 关于js的函数
1.获取内容的兼容函数 /* * 一: 获取内容的兼容函数 * setText(obj, str) * 思路: * 1.首先判断浏览器: * 2.如果是IE浏览器,就用innerText: * 3.如 ...
- 爬虫程序获取登录Cookie信息时遇到302,怎么处理
最近要做个爬虫程序爬爬东西,先搞定登录授权这块,没得源代码,所以只能自行搞定了,按平时的直接发起HttpWebRequest(req)请求,带上用户名密码,好了,然后 HttpWebResponse ...
- Mysql常用语句/group by 和 having子句
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ explain: ~~~~~~~~~~~~~~~~~ ...
- javaScript系列 [06]-javaScript和this
在javaScript系列 [01]-javaScript函数基础这篇文章中我已经简单介绍了JavaScript语言在函数使用中this的指向问题,虽然篇幅不长,但其实最重要的部分已经讲清楚了,这篇文 ...