pip安装pycrypto报错:Microsoft Visual C++ 14.0 is required. 和 SSLError: HTTPSConnectionPool的解决办法
今天本打算把【Python3爬虫】网易云音乐爬虫 的代码敲一遍, 但是在安装pycrypto老是报错,
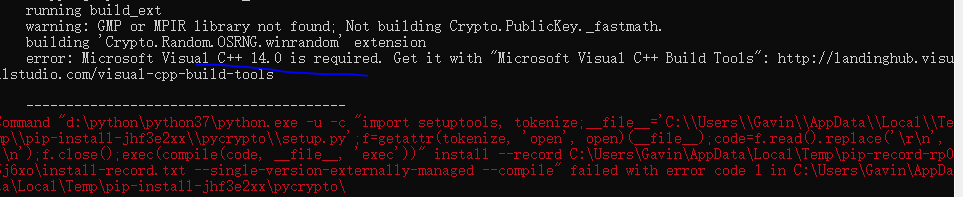
由于我计算是win10, 并且也有vs2017
python3环境下安装pycrypto的一些问题
Python踩坑之路-Python-3.6 安装pycrypto 2.6.1各种疑难杂症及解决方案
windows 下的python 安装pycrypto
pip安装pycrypto报错:Microsoft Visual C++ 14.0 is required. 的解决办法
而我的 解决 方式和pip安装pycrypto报错:Microsoft Visual C++ 14.0 is required. 的解决办法 一致:
1.首先安装必要的C++的东西,

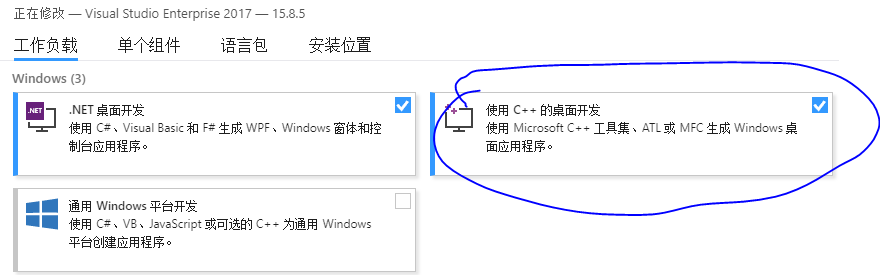
先前也是选择性的安装一些 必要的插件, 搞了很久, 后来火了,直接安装c++桌面开发
2。设置VCINSTALLDIR环境变量, 比如VS2015 的设置为:D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC,但是我是vs2017就设置为D:\Program Files (x86)\Microsoft Visual Studio\2017\Enterprise\VC 居然不对,后来搜索stdint.h文件才发现应是D:\Program Files (x86)\Microsoft Visual Studio\2017\Enterprise\VC\Tools\MSVC\14.14.26428\
实际上我还设置了饿个环境变量 VS140COMNTOOLS = D:\Program Files (x86)\Microsoft Visual Studio\2017\Enterprise\VC\Auxiliary\Build
VS100COMNTOOLS=%VS140COMNTOOLS%
3. 重新打开CMD,键入set CL=/FI"%VCINSTALLDIR%\\INCLUDE\\stdint.h" 。再用pip安装就可以成功。
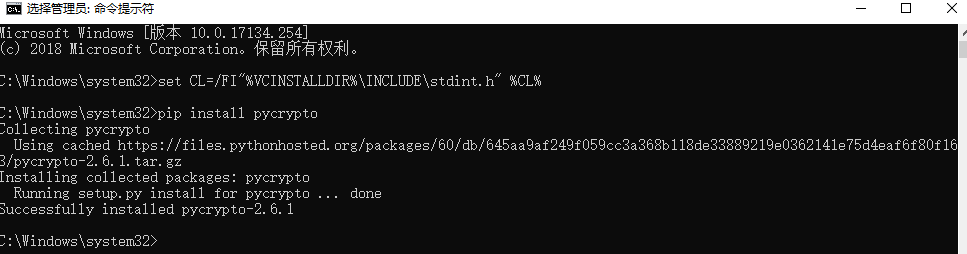
注:在实践过程中,发现pip有可能报 UnicodeDecodeError: 'utf-8' codec can't decode byte... 错误,这时需要将CMD的终端编码用“CHCP 65001”命令改为“UTF-8”后再安装。
在成功安装之后,如果import的时候没有Crypto而只有crypto,先打开Python安装目录下的Lib\site-packages\crypto文件夹,如果里面有Cipher文件夹,就返回到Lib\site-packages目录下把crypto重命名为Crypto,然后应该就可以成功导入了
由于是请求https,所以有时候很容易遇到如下错误
requests.exceptions.SSLError: HTTPSConnectionPool(host='music.163.com', port=443):

解决办法:代码调用了urllib3.disable_warnings()函数,来确保不会发生警告。
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
r = requests.get('https://www.12306.cn', verify=False)
print(r.status_code)
或者
import requests
import logging
logging.captureWarnings(True)
r = requests.get('https://www.12306.cn', verify=False)
print(r.status_code)
最后的python 代码:
# 爬取保存指定歌曲的所有评论并生成词云
import jieba
import codecs
import base64
import requests
from math import floor, ceil
from random import random
from Crypto.Cipher import AES
from wordcloud import WordCloud
from multiprocessing import Pool
from requests.packages import urllib3 headers = {'Host': 'music.163.com',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/66.0.3359.181 Safari/537.36'
} # 爬取并保存评论内容
def get_comments(data):
# data=[song_id,song_name,page_num]
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(data[]) + '?csrf_token='
# 得到两个加密参数
text, key = get_params(data[])
# 发送post请求
urllib3.disable_warnings()
res = requests.post(url, headers=headers, data={"params": text, "encSecKey": key}, verify=False)
if res.status_code == :
print("正在爬取第{}页的评论".format(data[]))
# 解析
comments = res.json()['comments']
# 存储
with open(data[] + '.txt', 'a', encoding="utf-8") as f:
for i in comments:
f.write(i['content'] + "\n")
else:
print("爬取失败!") # 生成词云
def make_cloud(txt_name):
with open(txt_name + ".txt", 'r', encoding="utf-8") as f:
txt = f.read()
# 结巴分词
text = ''.join(jieba.cut(txt))
# 定义一个词云
wc = WordCloud(
font_path="font.ttf",
width=,
height=,
max_words=,
max_font_size=,
min_font_size=
)
# 生成词云
wc.generate(text)
# 保存为图片
wc.to_file(txt_name + ".png") # 生成随机字符串
def generate_random_string(length):
string = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
# 初始化随机字符串
random_string = ""
# 生成一个长度为length的随机字符串
for i in range(length):
random_string += string[int(floor(random() * len(string)))]
return random_string # AES加密
def aes_encrypt(msg, key):
# 如果不是16的倍数则进行填充
padding = - len(msg) %
# 这里使用padding对应的单字符进行填充
msg += padding * chr(padding)
# 用来加密或者解密的初始向量(必须是16位)
iv = ''
# AES加密
cipher = AES.new(key, AES.MODE_CBC, iv)
# 加密后得到的是bytes类型的数据
encrypt_bytes = cipher.encrypt(msg)
# 使用Base64进行编码,返回byte字符串
encode_string = base64.b64encode(encrypt_bytes)
# 对byte字符串按utf-8进行解码
encrypt_text = encode_string.decode('utf-8')
# 返回结果
return encrypt_text # RSA加密
def rsa_encrypt(random_string, key, f):
# 随机字符串逆序排列
string = random_string[::-]
# 将随机字符串转换成byte类型数据
text = bytes(string, 'utf-8')
# RSA加密
sec_key = int(codecs.encode(text, encoding='hex'), ) ** int(key, ) % int(f, )
# 返回结果
return format(sec_key, 'x').zfill() # 获取参数
def get_params(page):
# 偏移量
offset = (page - ) *
# offset和limit是必选参数,其他参数是可选的
msg = '{"offset":' + str(offset) + ',"total":"True","limit":"20","csrf_token":""}'
key = '0CoJUm6Qyw8W8jud'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a87' \
'6aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9' \
'd05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b' \
'8e289dc6935b3ece0462db0a22b8e7'
e = ''
# 生成长度为16的随机字符串
i = generate_random_string()
# 第一次AES加密
enc_text = aes_encrypt(msg, key)
# 第二次AES加密之后得到params的值
encText = aes_encrypt(enc_text, i)
# RSA加密之后得到encSecKey的值
encSecKey = rsa_encrypt(i, e, f)
return encText, encSecKey def main():
song_id =
song_name = "伯乐"
# 构造url
u = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(song_id) + '?csrf_token='
# 构造参数
t, k = get_params()
# 构造data
d = {'params': t, 'encSecKey': k}
# 发送post请求并得到结果
urllib3.disable_warnings()
r = requests.post(u, headers=headers, data=d, verify=False)
# 提取评论总数(除开热评)
page_count = ceil((r.json()['total'] - ) / )
# 构造所有参数
data_list = [(song_id, song_name, i + ) for i in range(int(page_count))]
# 构造进程池
pool = Pool(processes=)
# 获取评论
print("开始爬取,请等待...")
pool.map(get_comments, data_list)
# 生成词云
make_cloud(song_name) if __name__ == "__main__":
main()
font.ttf
pip安装pycrypto报错:Microsoft Visual C++ 14.0 is required. 和 SSLError: HTTPSConnectionPool的解决办法的更多相关文章
- win10 64位 python3.6 django1.11 MysqlDB No module named 'MySQLdb' 安装MysqlDB报错 Microsoft Visual C++ 14.0 is required
在python3.6中操作数据库,再按python2.7安装MySQLdb进行数据库连接已经不可用了,我使用的是另外一个方法:PyMySQL,安装好之后还是不能直接连接MySQL的,启动项目后报No ...
- Scrapy安装报错 Microsoft Visual C++ 14.0 is required 解决办法
Scrapy安装报错 Microsoft Visual C++ 14.0 is required 解决办法原因:Scrapy需要的组 twisted 需要 C++环境编译. 方法一:根据错误提示去对应 ...
- 在安装pdfplumber时报错 Microsoft Visual C++ 14.0 is required.
在安装pdfplumber时报下列错误: 解决方法: 更新pip ,因为pip 版本太旧 来自为知笔记(Wiz)
- Scrapy 解决Scrapy安装时报错"Microsoft Visual C++ 14.0 is required"
问题描述 当前环境win10,python_3.6.1,64位.在windows下,在dos中运行pip install Scrapy报错:error: Microsoft Visual C++ 14 ...
- 安装scrapy 出现error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools 错误
安装scrapy 出现以下 错误: error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C ...
- Python安装scrapy提示 error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools&quo ...
- pycharm 关于模块安装出现的“[error] Microsoft Visual C++ 14.0 is required” 解决办法
刚才正准备对pycharm进行一番操作的时候,噔 噔磴噔噔 “no module define xxx” ,那我当然要把xxx给搞到pycharm上来啊, 不一会功夫 ,biu~ “[error] ...
- 完美解决pip install scrapy,安装Scrapy错误:Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
1,在Python3.6 安装Scrapy 出现以下报错 2,错误分析 红色报的错误指向的是Twisted 1,Twisted 没安装上 2,Twisted 没安装成功 3,Twisted 版本与Py ...
- Python: Windows下pip安装库出错:Microsoft Visual C++ 9.0 is required < Unable to find vcvarsall.bat
由于vs编译环境问题,需要设定vs2008的环境变量,如果机器上装有其他版本的vs比如vs2012, 可以做设定例如SET VS90COMNTOOLS=%VS120COMNTOOLS%即可
随机推荐
- lvs - mask标记
将两个服务绑定在一个集群服务中 如何将两种请求绑定在一个集群中通过一个director来调度, 这里需要iptable工具配合实现.首先在prerouting链上做一个标记,通过标记来调度 起两个服务 ...
- Python 经典类和新式类
#!/usr/bin/env python# -*- coding:utf-8 -*-# 作者:Presley# 邮箱:1209989516@qq.com# 时间:2018-10-21# 新式类和经典 ...
- Thinkphp3.1 php 链接SqlServer
ThinkPHP链接 M("lk_employeeInfo","Null/表前缀","sqlsrv://账号:密码@服务器:端口/数据库") ...
- java分页实现
虽然现在有很多好用的框架,对分页进行支持,很简单的就把分页的效果做出来,但是如果自己手写是一个怎样的流程的?今天就来说说它,手动实现分页效果. 一.分页的思路 首先我们得知道写分页代码时的思路,保持思 ...
- Python 解决 :NameError: name 'reload' is not defined 问题
对于 Python 2.X: import sys reload(sys) sys.setdefaultencoding("utf-8") 1 2 3 对于 <= Pytho ...
- hdu5745(dp+bitset)
题目:http://acm.hdu.edu.cn/showproblem.php?pid=5745 C++ bitset的用法:https://www.cnblogs.com/magisk/p/880 ...
- POJ 3264 Balanced Lineup 【线段树】
<题目链接> 题目大意: 求给定区间内最大值与最小值之差. 解题分析: 线段树水题,每个节点维护两个值,分别代表该区间的最大和最小值即可. #include <cstdio> ...
- POJ1062昂贵的聘礼(经典) 枚举区间 +【Dijkstra】
<题目链接> 昂贵的聘礼 Description 年轻的探险家来到了一个印第安部落里.在那里他和酋长的女儿相爱了,于是便向酋长去求亲.酋长要他用1000 ...
- RESTful架构&简单使用Django rest framework
RESTful架构 1 什么是REST REST全称是Representational State Transfer,中文意思是表述性状态转移. 它首次出现在2000年Roy Fielding的博士论 ...
- Django分页(一)
Django分页(一) 手动实现简单分页 HTML <!DOCTYPE html> <html lang="en"> <head> <me ...