numactl 修改 非统一内存访问架构 NUMA(Non Uniform Memory Access Architecture)模式
当今数据计算领域的主要应用程序和模型可大致分为三大类:
(1)联机事务处理(OLTP)、
(2)决策支持系统(DSS)
(3)企业信息通讯(BusinessCommunications)
上述三类系统设计人员在计算平台的体系结构方面可以选择:
(1)小型独立服务器模式
(2)对称多处理SMP(Symmetrical Multi-Processing)模式
(3)大规模并行处理MPP(Massive Parallel Processing)模式
(4)非统一内存访问架构NUMA(Non Uniform Memory Access Architecture)模式
。因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,
SMP的缺点是可伸缩性有限,因为在存储器接口达到饱和的时候,增加处理器并不能获得更高的性能。
NUMA是什么
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间
(Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(Remote Access)。
所以NUMA(Non-Uniform Memory Access)就此得名。
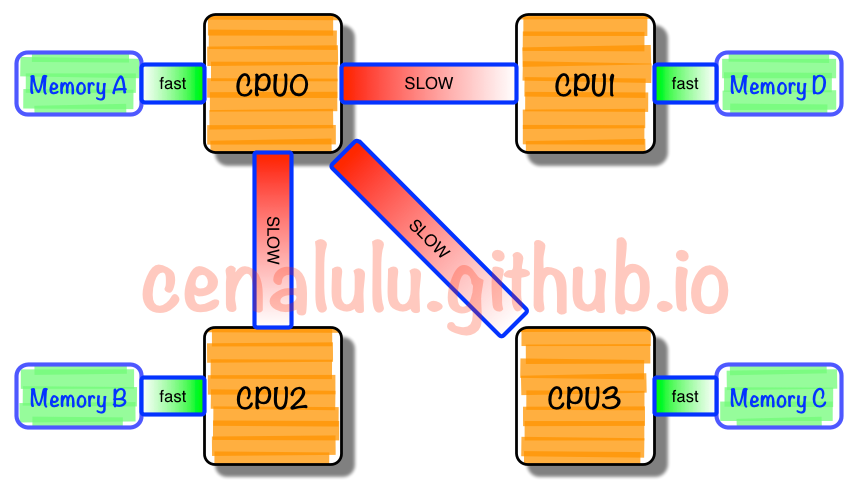
二、NUMA相关的策略
1、每个进程(或线程)都会从父进程继承NUMA策略,并分配有一个优先node。如果NUMA策略允许的话,进程可以调用其他node上的资源。
2、NUMA的CPU分配策略有cpunodebind、physcpubind。
cpunodebind规定进程运行在某几个node之上
physcpubind可以更加精细地规定运行在哪些核上
3、NUMA的内存分配策略有localalloc、preferred、membind、interleave。
localalloc规定进程从当前node上请求分配内存
preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存
interleave规定进程从指定的若干个node上以RR算法交织地请求分配内存
使用numactl –interleave来修改NUMA策略即可。
参考:
cpu三大架构 numa smp mpp
cenalulu: numa
numactl 修改 非统一内存访问架构 NUMA(Non Uniform Memory Access Architecture)模式的更多相关文章
- ARMv8 内存管理架构.学习笔记
http://blog.csdn.net/forever_2015/article/details/50285955 版权声明:未经博主允许不得转载,请尊重原创, 谢谢! 目 录 第1章 分级存储 ...
- Buffer Data RDMA 零拷贝 直接内存访问
waylau/netty-4-user-guide: Chinese translation of Netty 4.x User Guide. 中文翻译<Netty 4.x 用户指南> h ...
- Linux内核内存管理架构
内存管理子系统可能是linux内核中最为复杂的一个子系统,其支持的功能需求众多,如页面映射.页面分配.页面回收.页面交换.冷热页面.紧急页面.页面碎片管理.页面缓存.页面统计等,而且对性能也有很高的要 ...
- 修改oracle数据库内存报错
今天修改oracle数据库内存时, alter system set memory_max_target=10240M scope=spfile;语句正确修改:但重启时却报错 : SQL> al ...
- Linux内核内存管理-内存访问与缺页中断【转】
转自:https://yq.aliyun.com/articles/5865 摘要: 简单描述了x86 32位体系结构下Linux内核的用户进程和内核线程的线性地址空间和物理内存的联系,分析了高端内存 ...
- C++异常机制的实现方式和开销分析 (大图,编译器会为每个函数增加EHDL结构,组成一个单向链表,非常著名的“内存访问违例”出错对话框就是该机制的一种体现)
白杨 http://baiy.cn 在我几年前开始写<C++编码规范与指导>一文时,就已经规划着要加入这样一篇讨论 C++ 异常机制的文章了.没想到时隔几年以后才有机会把这个尾巴补完 :- ...
- Memory Ordering (注意Cache带来的副作用,每个CPU都有自己的Cache,内存读写不再一定需要真的作内存访问)
Memory Ordering Background 很久很久很久以前,CPU忠厚老实,一条一条指令的执行我们给它的程序,规规矩矩的进行计算和内存的存取. 很久很久以前, CPU学会了Out-Of ...
- 【CUDA 基础】4.3 内存访问模式
title: [CUDA 基础]4.3 内存访问模式 categories: - CUDA - Freshman tags: - 内存访问模式 - 对齐 - 合并 - 缓存 - 结构体数组 - 数组结 ...
- CUDA Pro:通过向量化内存访问提高性能
CUDA Pro:通过向量化内存访问提高性能 许多CUDA内核受带宽限制,而新硬件中触发器与带宽的比率不断提高,导致带宽受限制的内核更多.这使得采取措施减轻代码中的带宽瓶颈非常重要.本文将展示如何在C ...
随机推荐
- hive Spark SQL分析窗口函数
Spark1.4发布,支持了窗口分析函数(window functions).在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分 ...
- Canvas入门到高级详解(中)
三. canvas 进阶 3.1 Canvas 颜色样式和阴影 3.1.1 设置填充和描边的颜色(掌握) fillStyle : 设置或返回用于填充绘画的颜色 strokeStyle: 设置或返回用于 ...
- C++ 函数模板的返回类型如何确定?
函数模板 #include <iostream> // 多个参数的函数木板 template<typename T1, typename T2> T2 max(T1 a, T2 ...
- linux服务查看
(1)#service servicename status比如查看防火墙:#service iptables status (2)#chkconfig --list |grep 服务名 比如查看te ...
- mongodb应用
一.概述 NoSQL,指的是非关系型的数据库.NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称.NoSQL用于超大规模数据的存储.(例如谷歌或Fa ...
- vue-cli关闭eslint及配置eslint
有了eslint的校验,可以来规范开发人员的代码,是挺好的.但是有些像缩进.空格.空白行之类的规范,在开发过程中一直报错,有点烦人了. 我们可以在创建工程的时候选择不要安装eslint.就是在安装工程 ...
- 最简单的设计模式——单例模式的演进和推荐写法(Java 版)
前言 如下是之前总结的 C++ 版的:软件开发常用设计模式—单例模式总结(c++版),对比发现 Java 实现的单例模式和 C++ 的在线程安全上还是有些区别的. 概念不多说,没意思,我自己总结就是: ...
- Android Studio中解决jar包重复依赖导致的代码编译错误
在原本的代码中已经使用了OKHTTP和rxjava,然后今天依赖retrofit的时候一直报错 Program type already present: okhttp3.internal.ws.Re ...
- 消息中间件系列四:RabbitMQ与Spring集成
一.RabbitMQ与Spring集成 准备工作: 分别新建名为RabbitMQSpringProducer和RabbitMQSpringConsumer的maven web工程 在pom.xml文 ...
- python程序打包成.exe
安装pyinstaller 方法一:使用pip install pyinstaller 方法二:如果是下载github上的包之后手动安装 包下载 亲测可用:Pyinstaller下载地址,GitHub ...