(数据科学学习手札25)sklearn中的特征选择相关功能
一、简介
在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本、精简模型、增强模型的泛化性能等角度考虑,我们常常需要对原始变量进行一系列的预处理及筛选,剔除掉冗杂无用的成分,得到较为满意的训练集,才会继续我们的学习任务,这就是我们常说的特征选取(feature selection)。本篇就将对常见的特征选择方法的思想及Python的实现进行介绍;
二、方法综述
2.1 去除方差较小的变量
这种方法针对离散型变量进行处理,例如,有变量X,其每个取值来自伯努利分布,即每一个样本的观测值为1或0,这种情况下,如果绝大多数观测值都是1或0,那么我们认为这种变量对我们模型的训练,并不起什么显著地作用,这时就可以将这种变量剔除,下面我们来介绍sklearn中进行此项操作的方法:
我们使用sklearn.feature中的VarianceThreshold()来对特征进行选择,它主要的参数为threshold,传入参数格式为 最小容忍比例*(1-最小容忍比例),这里的容忍比例就是我们所说的当离散样本中最多的那一类数量占全体数量的上限,比如设定为 0.8*(1-0.8),就是说对所有变量中最大比例样本对应的比例大于等于80%的变量予以剔除,下面进行简单的演示说明:
from sklearn.feature_selection import VarianceThreshold
import numpy as np '''生成方差接近0的演示变量'''
X = np.array(np.random.binomial(1,0.1,30)).reshape((10,3)) '''生成方差明显远离0的演示变量'''
Y = np.array(np.random.binomial(1,0.5,10)) '''按列拼接矩阵'''
data = np.column_stack([X,Y]) '''初始化我们的低方差特征选择模型'''
sel = VarianceThreshold(threshold=0.8*(1-0.8)) '''原始数据集'''
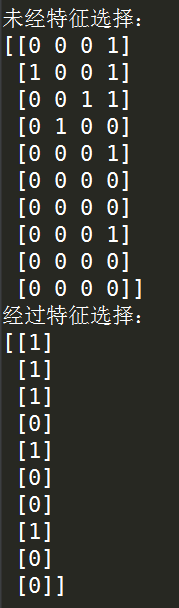
print('未经特征选择:')
print(data) '''利用设定好的模型对演示数据进行特征选择并显示结果'''
print('经过特征选择:')
print(sel.fit_transform(data))
运行结果:
2.2 单变量的特征选择
单变量的特征选择是指通过单变量的统计检验,为每一个待筛选变量进行检验并对其检验结果进行评分,最后根据自定的规则选择留下哪些变量,有以下几种自定规则方法:
1.SelectKBest(score_func,k):其中score_func传入用于计算评分的函数,默认是f_classif,它计算的是单变量与训练target间的方差分析F值(Anova F-value);
k传入用户想要根据评分从高到低留下的变量的个数,默认是10;
2.SelectPercentile(score_func,percentile):其中score_func同上;percentile传入用户想要根据得分从高到低留下的变量个数占总个数的比例,默认10,表示10%;
3.SelectFpr(score_func,alpha):通过控制FPR检验中取伪错误发生的概率来选择特征,其中score_func同上;alpha用来控制置信水平,即p值小于该值时拒绝原假设,即对应的变量被保留(原假设是该特征对分类结果无显著贡献);
4.GenericUnivariateSelect(score_func,mode,param):这是一个整合上述几种方法的广义方法,其中score_func同上;mode用来指定特征选择的方法,可选项有{‘percentile’, ‘k_best’, ‘fpr’, ‘fdr’, ‘fwe’},与上面几种方法相对应;param的输入取决于mode中指定的方式,即指定方式对应的传入参数;
下面我们以鸢尾花数据为例对SelectKBest进行演示,设定k=3,统计检验的方法设置为卡方独立性检验:
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2 '''导入数据'''
iris = load_iris()
'''为分类标签和自变量进行赋值'''
X, y = iris.data, iris.target
print('筛选之前:')
'''特征筛选之前的自变量数据集形状'''
print(X.shape) '''进行SelectKBest,这里设置检验函数为chi2,即卡方独立性检验,设置保留的变量个数为3'''
X_new = SelectKBest(chi2, k=3).fit_transform(X, y)
print('筛选之后:')
print(X_new.shape)
运行结果:

2.3 递归特征消除法
递归特征消除法(Recursive feature elimination)的基本思想是反复地构建多个模型(如回归模型、支持向量机等),例如,在回归任务中,对n个变量,第一轮构造n个模型,每个模型都对应着剔除掉一个变量,选择出其中效果最佳的模型对应的变量,将其剔除,再进入第二轮,这样通过递归构建模型,最终将剩余的变量控制在最佳的水平,这类似交叉验证(cross validation)的过程,我们使用sklearn.feature_selection中的RFECV()来实施这个过程,其具体参数如下:
estimator:该参数传入用于递归构建模型的有监督型基学习器,要求该基学习器具有fit方法,且其输出含有coef_或feature_importances_这种结果;
step:数值型,默认为1,控制每次迭代过程中删去的特征个数,有以下两种情况:
1.若传入大于等于1的整数,则在每次迭代构建模型的过程中删去对应数量的特征;
2.若传入介于0.0到1.0之间的浮点数,则在每次第迭代构造模型的过程中删去对应比例的特征。
cv:控制交叉验证的分割策略,默认是3折交叉验证,有以下几种情况:
1.None,等价于不传入参数,即使用默认设置的3折交叉验证;
2.正整数,这时即指定了交叉验证中分裂的子集个数,即k折中的k;
n_jobs:控制并行运算中利用到的CPU核心数,默认为1,即单核工作,若设置为-1,则启用所有核心进行运算;
函数的返回值:
n_features_:通过交叉验证过程最终剩下的特征个数;
support_:被选择的特征的被选择情况(True表示被选择,False表示被淘汰)
ranking_:所有特征的评分排名
estimator_:利用剩下的特征训练出的模型
下面以威斯康辛州乳腺癌数据作为演示数据,决策树分类为基学习器,具体过程如下:
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_selection import RFECV
from sklearn.metrics import confusion_matrix as cm
from sklearn.model_selection import train_test_split '''载入红酒三分类数据'''
X,y = datasets.load_wine(return_X_y=True) '''分格训练集与测试集'''
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) '''定义基学习器'''
estimator =DecisionTreeClassifier() '''利用基学习器直接来训练(不删除变量)'''
pre_ = estimator.fit(X_train,y_train).predict(X_test) '''打印混淆矩阵'''
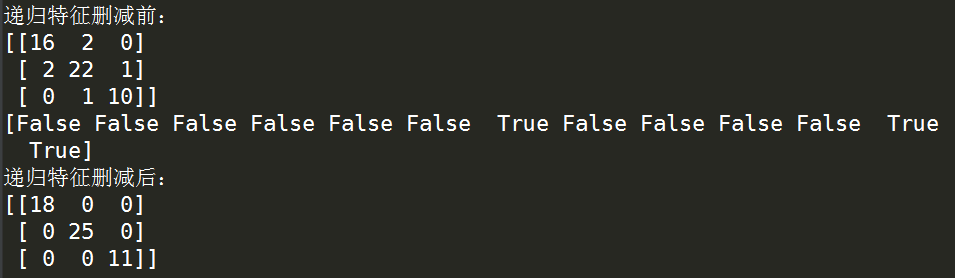
print('递归特征删减前:')
print(cm(y_test,pre_)) '''进行递归特征消除,这里设置每一轮迭代中每次删去一个变量,并进行5折交叉验证来用于评估性能'''
selector = RFECV(estimator,step=1,cv=5) '''保存最后训练出的最优学习器'''
selector = selector.fit(X,y) '''打印特征的剔除情况'''
print(selector.support_) '''利用得到的最优学习器来对验证集进行预测'''
pre = selector.estimator_.predict(X_test[:,selector.support_]) '''打印混淆矩阵'''
print('递归特征删减后:')
print(cm(y_test,pre))
运行结果如下:
2.4 SelectFromModel
这是一种受算法限制比较大的特征筛选方法,使用这种算法的前提是你所选择的算法的返回项中含有coef_或feature_importances_项,即可用来衡量变量优劣的系数,通过这种系数对不同变量进行评分,然后按照设置的数目或比例剔除对应数目的最差变量,在sklearn.feature_selection中我们使用SelectFromModel()来实现上述过程,其主要参数如下:
estimator:基学习器,必须是含有coef_或feature_importances_输出项的有监督学习算法;
threshold:指定留下的特征数量,默认值为"mean",有几种不同的设定策略:
1.字符型时,指定一个特殊的指标,当特征的评分系数小于这个指标时,保留,否则剔除;可选项有"median","mean",也可更加自由地指定为alpha*关键指标,这里的alpha是一个连续实数,例如'1.5*median';
2.数值型,且只能设定为1e-5,适用于含有惩罚项的算法(如逻辑回归,lasso回归等);
prefit:是否进行预训练,即制定的学习器在SelectFromModel之前就已经进行了fit操作,默认为False;
输出项:
estimator_:返回由最终保留的特征训练成的学习器;
threshold_:之前参数设定的变量剔除指标量
注意,这里若想查看所有特征被筛选的情况,需要对保存SelectFromModel fit之后的对象使用.get_support()方法才可以;
这里若使用其返回的训练好的学习器,则predict时不需要根据变量删减情况保存的数组对测试样本进行索引;
下面我们依旧使用威斯康辛州乳腺癌数据作为演示数据,决策树作为基学习器,具体过程如下:
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.metrics import confusion_matrix as cm
from sklearn.model_selection import train_test_split '''载入红酒三分类数据'''
X,y = datasets.load_wine(return_X_y=True) '''分格训练集与测试集'''
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) '''定义基学习器'''
estimator =DecisionTreeClassifier() '''利用基学习器直接来训练(不删除变量)'''
pre_ = estimator.fit(X_train,y_train).predict(X_test) '''打印混淆矩阵'''
print('递归特征删减前:')
print(cm(y_test,pre_)) '''进行递归特征消除,这里设置每一轮迭代中每次删去一个变量,并进行5折交叉验证来用于评估性能'''
selector =SelectFromModel(estimator,threshold='median') '''保存最后训练出的最优学习器'''
selector = selector.fit(X,y) '''打印特征的剔除情况'''
print('打印特征的剔除情况')
print(selector.get_support()) '''利用得到的最优学习器来对验证集进行预测'''
pre = selector.estimator_.predict(X_test) '''打印混淆矩阵'''
print('递归特征删减后:')
print(cm(y_test,pre))
运行结果:
2.5 筛选特征和训练模型基于不同的学习器(基于SelectFromModel)
我们可以把特征选择与真正使用的训练学习器相独立开来,例如我们可以使用支持向量机来作为特征选择中使用到的算法,而将产出的数据用随机森林模型来训练,通过sklearn.pipeline中的Pipeline就可以非常巧妙地将这些过程组合在一起,但这种方法不是很主流,在这里就不展开说,欲了解详情可以查看sklearn的官网相关内容介绍页:http://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html#sklearn.pipeline.Pipeline
以上就是关于机器学习中特征选择的基本内容,如有笔误,望指出。
(数据科学学习手札25)sklearn中的特征选择相关功能的更多相关文章
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
随机推荐
- Win10下使用VSCode配置python运行环境
VSCode配置python运行环境 安装python 到官网下载python,直接安装即可,在安装过程中可以选择将python加入环境变量 安装VSCode 官网下载,直接安装 配置 安装pytho ...
- SpringMvc-自定义视图
1.创建视图: 注意:创建视图的时候需要实现View接口的俩个方法 package com.atguigu.springmvc.views; import java.util.Date; import ...
- Exchange 2016的MAPI over HTTP简介
一.MAPI over HTTP的简介 MAPI(消息处理应用程序编程接口)over HTTP是传输协议,可将传输层移到行业标准HTTP模型中,从而提升Outlook 和 Exchange连接的可靠性 ...
- 关于simotion建立同步/解除同步的问题
关于simotion建立同步/解除同步的问题. 问题: [enable gearing][disable gearing][enable camming][disable camming]都是一个过程 ...
- libxml的使用 编辑节点
libxml读取的基本功能已经介绍过了,现在将介绍libxml编写的基本功能. 编写操作包含节点的添加,删除和修改. 对于添加,我们需要调用xmlNewTextChild函数来添加节点,需要xmlNe ...
- js数据封装处理
var arr = [ { id: "1", date: "2018-07-27", time: "10:00-12:00", schedu ...
- python接口测试-项目实践(一) 测试需求与测试思路
测试需求: 第三方系统提供了3个接口,需要测试前端显示的字符串里的对应数据与接口数据是否一致. 测试分层: 开发人员的设计:每周从接口取一次数据,拼接完成后保存到数据库.再从数据库取数提供接口给前端开 ...
- POJ 1986 Distance Queries 【输入YY && LCA(Tarjan离线)】
任意门:http://poj.org/problem?id=1986 Distance Queries Time Limit: 2000MS Memory Limit: 30000K Total ...
- listBox获取项的方法
获取所有项 ; i < LB.Items.Count;i++ )2 {3 str_arr.Add(LB.Items[i].ToString()); 4 } 获取指定项 string str=LB ...
- Python Notes | Python 备忘笔记
[ File IO ] parameters used in the file IO: 该参数决定了打开文件的模式:只读,写入,追加等.所有可取值见如下的完全列表.这个参数是非强制的,默认文件访问模式 ...