Spark程序
Spark认识&环境搭建&运行第一个Spark程序
2017-07-09 17:17 by 牛仔裤的夏天, 181 阅读, 0 评论, 收藏, 编辑
摘要:Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度。这里总结下对Spark的认识、虚拟机Spark安装、Spark开发环境搭建及编写第一个scala程序、运行第一个Spark程序。
1.Spark是什么
Spark是一个快速且通用的集群计算平台
2.Spark的特点
1)Spark是快速的
Spark扩充了流行的Mapreduce计算模型
Spark是基于内存的计算
2)Spark是通用的
Spark的设计容纳了其它分布式系统拥有的功能
批处理,迭代式计算,交互查询和流处理等
3)Spark是高度开放的
Spark提供了Python,Java,Scala,SQL的API和丰富的内置库。
Spark和其它的大数据工具整合的很好,包括hadoop,kafka等
3.Spark的组件
Spark包括多个紧密集成的组件

Spark Core:
包含Spark的基本功能,包含任务调度,内存管理,容错机制等
内部定义了RDDs(弹性分布式数据集)
提供了很多APIs来创建和操作这些RDDs
应用场景,为其他组件提供底层的服务
Spark SQL:
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样
应用场景,企业中用来做报表统计
Spark Streaming:
是实时数据流处理组件,类似Storm
Spark Streaming提供了API来操作实时流数据
应用场景,企业中用来从Kafka接收数据做实时统计
Mlib:
一个包含通用机器学习功能的包,Machine learning lib
包含分类,聚类,回归等,还包括模型评估和数据导入。
MLib提供的上面这些方法,都支持集群上的横向扩展。
应用场景,机器学习。
Graphx:
是处理图的库(例如,社交网络图),并进行图的并行计算。
像Spark Streaming,Spark SQL一样,它也继承了RDD API。
它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
应用场景,图计算。
Cluster Managers:
就是集群管理,Spark自带一个集群管理是单独调度器。
常见集群管理包括Hadoop YARN,Apache Mesos
4.紧密集成的优点
Spark底层优化了,基于Spark底层的组件也得到了相应的优化。
紧密集成,节省了各个组件组合使用时的部署、测试等时间。
向Spark增加新的组件时,其它组件,可立刻享用新组件的功能。
5.Spark与Hadoop的比较
Hadoop应用场景:离线处理、对时效性要求不高
Spark应用场景:时效性要求高的场景、机器学习等领域
Doug Cutting的观点:这是生态系统,每个组件都有其作用,各善其职即可。Spark不具有HDFS的存储能力,要借助HDFS等持久化数据。大数据将会孕育出更多的新技术。
6.Spark运行环境
Spark是Scala写的,运行在JVM上,所以运行环境Java7+
如果使用Python API,需要安装Python2.6+或者Python3.4+
版本对应:Spark1.6.2 - Scala2.10 Spark2.0.0 - Scala2.11
7.Spark安装
Spark下载地址:http://spark.apache.org/downloads.html 注:搭Spark不需要Hadoop,如有hadoop集群,可下载相应的版本。
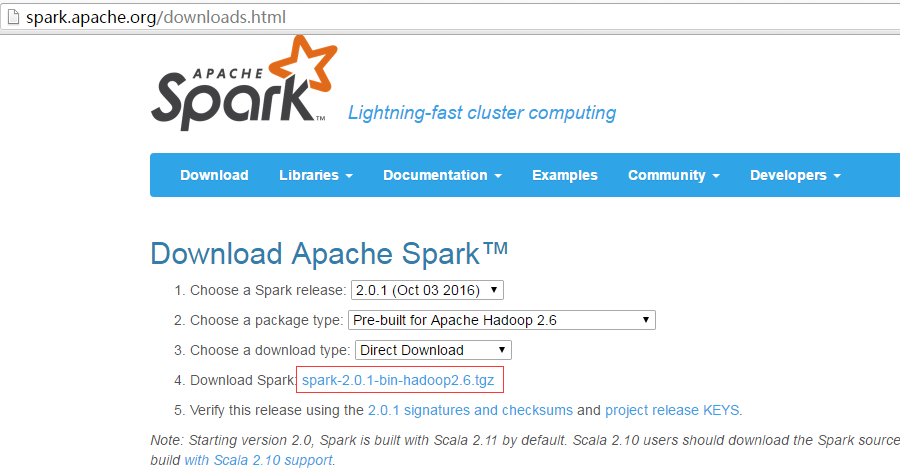
这里安装在CentOS6.5虚拟机上,将下载好的文件上传虚拟机,并执行解压:tar -zxvf spark-2.0.1-bin-hadoop2.6.tgz
Spark目录:
bin包含用来和Spark交互的可执行文件,如Spark shell。
examples包含一些单机Spark job,可以研究和运行这些例子。
Spark的Shell:
Spark的shell能够处理分布在集群上的数据。
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成。
快速使用迭代式计算,实时查询、分析一般能够在shells中完成。
Spark提供了Python shells和Scala shells。
这里以Scala shell为例,演示读取本地文件并进行操作:
进入Scala shell:./spark-shell
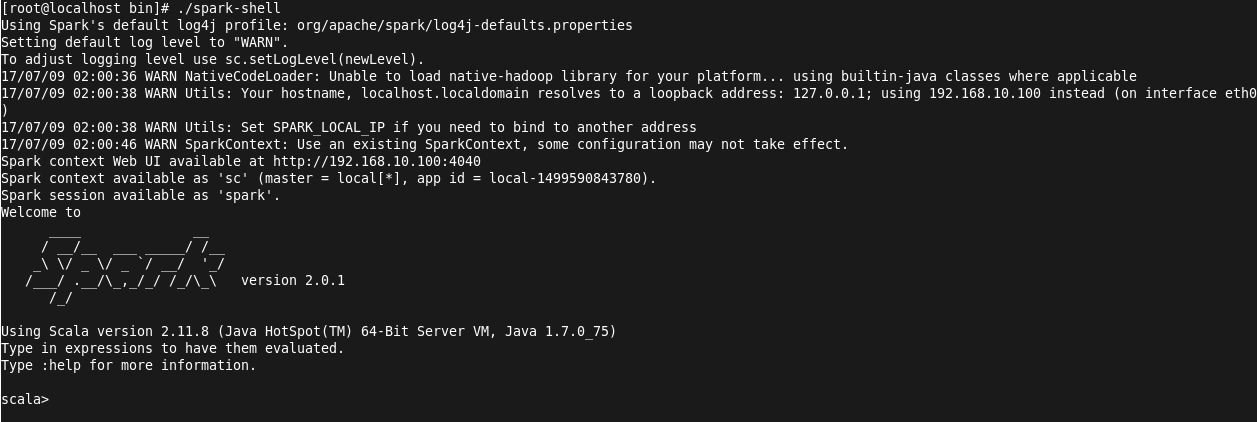
创建测试文件helloSpark并输入内容:
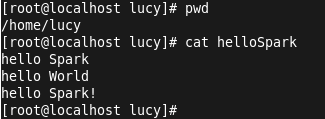
输入val lines=sc.textFile("/home/lucy/hellospark") 加载文件内容,输入lines.count()进行统计行数: ( 注:sc为spark content)
ssh的配置:(ssh localhost需要输入密码,这在运行spark程序时是不可以的)
ssh-keygen (生成秘钥)
.ssh目录下cat xxx_rsa.pub> authorized_keys
chmod 600 authorized_keys
8.Spark开发环境搭建
Scala 下载地址: http://www.scala-lang.org/download/2.11.6.html 注:默认安装选项会自动配置环境变量,安装路径不能有空格。
IntelliJ IDEA 下载地址:https://www.jetbrains.com/idea/
注册码地址:http://idea.lanyus.com
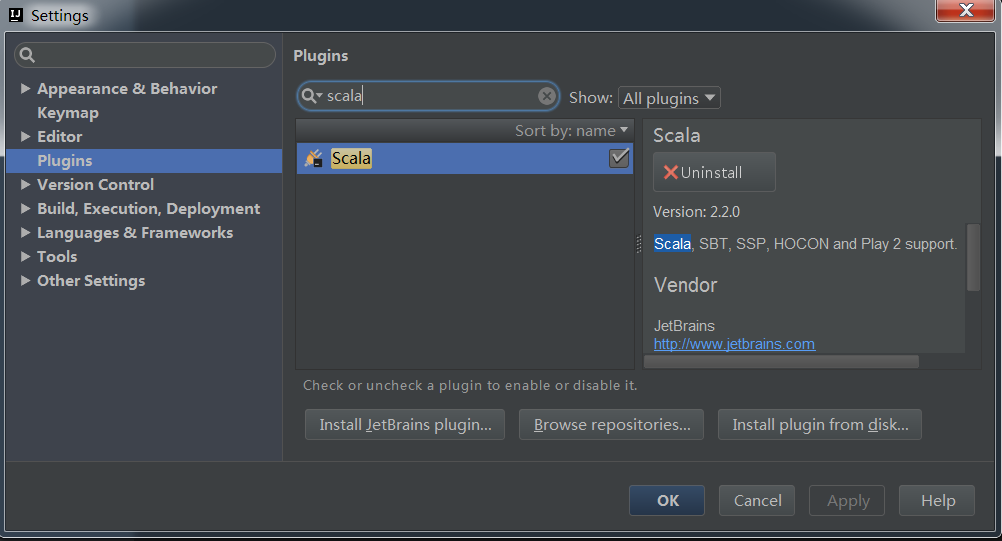
由于这里下载的ideaIU-15.0.2.exe,已经包含有Scala插件,如果不包含需要下载。查看是否已有scala插件可以新建项目,打开Files->settings选择Plugins,输入scala查看:
9.编写第一个Scala程序
依次点击File->New->Project,选择Scala->SBT,下一步,打开如下窗口:
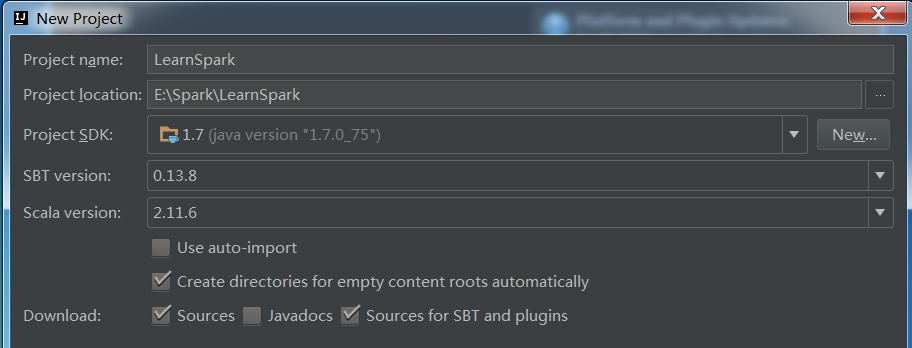
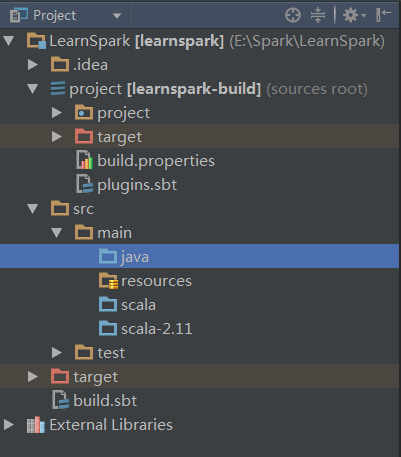
这里Scala选择为2.11.6,创建完成后会进行初始化操作,自动下载jar包等。下载时常看具体网络情况。待所有进度条完成后,项目目录已经出来了,如下:
编辑build.sbt:
name := "LearnSpark"
version := "1.0"
scalaVersion := "2.11.1"
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.0.2"
编辑完成后,点击刷新,后台自动下载对应的依赖:

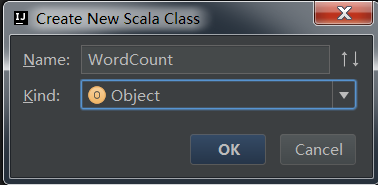
src->scala右击新建scala类WordCount

import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Lucy on 2017/7/4.
*/
object WordCount {
def main(args: Array[String]) {
val conf=new SparkConf().setAppName("wordcount")
val sc=new SparkContext(conf)
val input=sc.textFile("/home/lucy/helloSpark")
val lines=input.flatMap(line=>line.split(" "))
val count=lines.map(word=>(word,1)).reduceByKey{case (x,y)=>x+y}
val output=count.saveAsTextFile("/home/lucy/hellosparkRes")
}
}
代码编写完成后,进行打包(配置jar包,build):
配置jar包:File->Project Structure,选择Artifacts,点击+号:
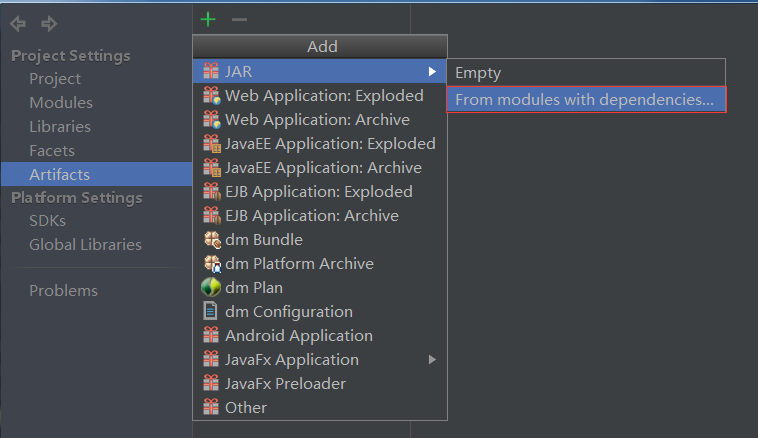

这里不打包依赖。配置jar包完成后,Build->Build Artifacts,等待build完成。
10.运行第一个Spark程序
这里需要先启动集群:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
这里的地址为:启动master后,在浏览器输入localhost:8080,查看到的master地址

启动成功后,jps查看进程:
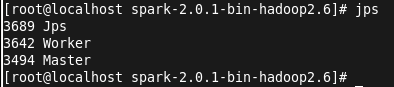
接下来执行提交命令,将打好的jar包上传到linux目录,jar包在项目目录下的out\artifacts下。
提交作业: ./bin/spark-submit --master spark://localhost:7077 --class WordCount /home/lucy/learnspark.jar
可以在4040端口查看job进度:

查看结果:
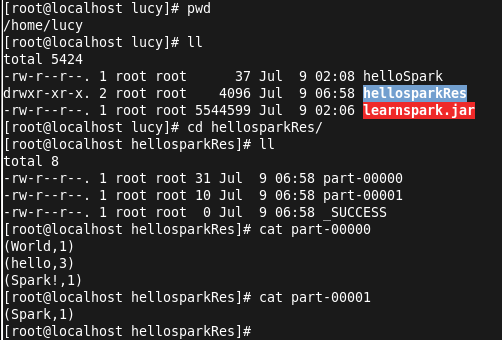
由于按照空格分割字符串,所以这里将Spark! 视为一个单词。至此,任务运行结束!
Spark程序的更多相关文章
- 如何运行Spark程序
[hxsyl@CentOSMaster spark-2.0.2-bin-hadoop2.6]# ./bin/spark-submit --class org.apache.spark.examples ...
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- Spark认识&环境搭建&运行第一个Spark程序
摘要:Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度.这里总结下对Spark的认识.虚拟机Spark安装.Spark开发环境搭建及编写第一个scala程序.运 ...
- IntelliJ IDEA在Local模式下Spark程序消除日志中INFO输出
在使用Intellij IDEA,local模式下运行Spark程序时,会在Run窗口打印出很多INFO信息,辅助信息太多可能会将有用的信息掩盖掉.如下所示 要解决这个问题,主要是要正确设置好log4 ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 使用IDEA运行Spark程序
使用IDEA运行Spark程序 1.安装IDEA 从IDEA官网下载Community版本,解压到/usr/local/idea目录下. tar –xzf ideaIC-13.1.4b.tar.gz ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [Spark]如何设置使得spark程序不输出 INFO级别的内容
Spark程序在运行的时候,总是输出很多INFO级别内容 查看了网上的一些文章,进行了试验. 发现在 /etc/spark/conf 目录下,有一个 log4j.properties.template ...
- eclipse运行spark程序时日志颜色为黑色的解决办法
自从开始学习spark计算框架以来,我们老师教的是local模式下用eclipse运行spark程序,然后我在运行spark程序时,发现控制台的日志颜色总是显示为黑色,哇,作为程序猿总有一种强迫症,发 ...
- Spark程序运行常见错误解决方法以及优化
转载自:http://bigdata.51cto.com/art/201704/536499.htm Spark程序运行常见错误解决方法以及优化 task倾斜原因比较多,网络io,cpu,mem都有可 ...
随机推荐
- python字符串常用内建函数总结
自己总结一些常用字符串函数,理解比较粗糙 1.字符串内建函数-大小写转换函数 (1)str.capitalize Help on method_descriptor: capitalize(...) ...
- oracle 12c rac vip和监听故障
环境:aix 7.1 ,oracle 12.1.0.2 rac -3节点. 硬件故障后,硬件工程师更换了内联网卡,不知为何资源VIP也有问题,只好先添加了VIP srvctl add vip -nod ...
- (四)、python 集合与格式化
一.set 集合 集合:可以包含多个元素,用逗号分割“,” 集合的作用:去重,关系运算, 1.不同元素组成2.无序3.集合中元素必须是不可变类型(可hash,可作为字典的key) 使用方法: 1) ...
- js判断两个日期是否在几个月之内
//比较两个时间 time1,time2均为日期类型 //判断两个时间段是否相差 m 个月 function completeDate(time1 , time2 , m) { var diffyea ...
- 什么是高防服务器?如何搭建DDOS流量攻击防护系统
关于高防服务器的使用以及需求,从以往的联众棋牌到目前发展迅猛的手机APP棋牌,越来越多的游戏行业都在使用高防服务器系统,从2018年1月到11月,国内棋牌运营公司发展到了几百家. 棋牌的玩法模式从之前 ...
- Java学习笔记十四:如何定义Java中的类以及使用对象的属性
如何定义Java中的类以及使用对象的属性 一:类的重要性: 所有Java程序都以类class为组织单元: 二:什么是类: 类是模子,确定对象将会拥有的特征(属性)和行为(方法): 三:类的组成: 属性 ...
- pwa学习笔记--简介
1. 介绍 Progressive Web App , (渐进式增强 WEB 应用) 简称 PWA ,是提升WebApp的体验的一种新方法,能给用户原生应用的体验. PWA 本质上是 Web App ...
- Black And White (DFS 训练题)
G - Black And White ================================================================================ ...
- 简单整理React的Context API
之前做项目时经常会遇到某个组件需要传递方法或者数据到其内部的某个子组件,中间跨越了甚至三四层组件,必须层层传递,一不小心哪层组件忘记传递下去了就不行.然而我们的项目其实并没有那么复杂,所以也没有使用r ...
- Java——static关键字---18.09.27
static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块,但在Java语言中没有全局变量的概念. static关键字主要有两种作用: 一.为某特定数据类 ...