SpringBoot2.0之整合Kafka
maven依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itmayiedu</groupId>
<artifactId>springboot2.0_kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
</parent>
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies> </project>
yml:
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
bootstrap-servers: 192.168.91.1:9092,192.168.91.3:9092,192.168.91.4:9092
consumer:
# 指定一个默认的组名
group-id: kafka2
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: 192.168.91.1:9092,192.168.91.3:9092,192.168.91.4:9092
消费者:消费 topic为“test”的消息
/**
* 消费者使用日志打印消息
*/ @KafkaListener(topics = "test") //监听同一个主题
public void receive(ConsumerRecord<?, ?> consumer) {
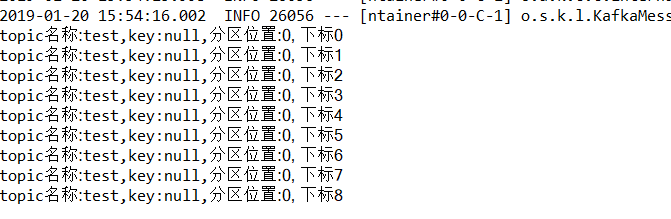
System.out.println("topic名称:" + consumer.topic() + ",key:" + consumer.key() + ",分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
}
可以看到分区都是0昂~ tets创建时候 partition是1哦 就是在proker1上创建的主题
写个controller,自己生产 ,自己消费
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; @RestController
@SpringBootApplication
public class KafkaController { /**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate; /**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("my_test_topic", key, data); //三个参数: topic名称 key 消息数据 }
// test 主题 1 my_test 3 @RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) { //循环发6次kafka消息
send("key" + i, "data" + i);
}
return "success";
} public static void main(String[] args) {
SpringApplication.run(KafkaController.class, args);
} /**
* 消费者使用日志打印消息
*/ @KafkaListener(topics = "my_test_topic") //监听同一个主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" + consumer.key() + ",分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
} }
运行后:

可以看到key与对应的分区存储情况! 分区就是不同的 broker 比如key1 和 key2 存放在 第三个broker~
也可以查看每个节点的日志 000000000.log的情况 我这边显示乱码 我就不多做展示了
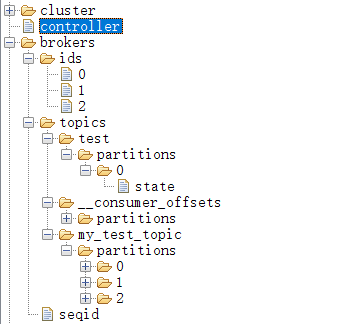
看看我们的zk:
SpringBoot2.0之整合Kafka的更多相关文章
- SpringBoot2.0之整合Apollo
Spring Boot客户端对接阿波罗服务器端 核心源码都在这个压缩包里面 封装好了环境 运行shell脚本就ok了 下面进入到本地maven仓库: 远程仓库apollo的jar包 只能打包到本地或者 ...
- springboot2.0 快速集成kafka
一.kafka搭建 参照<kafka搭建笔记> 二.版本 springboot版本 <parent> <groupId>org.springframework.bo ...
- SpringBoot2.0之整合ElasticSearch
就类比数据库到时候去实现 服务器端配置 集群名字 与yml名字一致 pom: <project xmlns="http://maven.apache.org/POM/4.0.0&qu ...
- SpringBoot2.0之整合ActiveMQ(发布订阅模式)
发布订阅模式与前面的点对点模式很类似,简直一毛一样 注意:发布订阅模式 先启动消费者 公用pom: <project xmlns="http://maven.apache.org/PO ...
- SpringBoot2.0之整合ActiveMQ(点对点模式)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- SpringBoot2.0之整合Dubbo
Dubbo支持协议 Dubbo支持dubbo.rmi.hessian.http.webservice.thrift.redis等多种协议,但是Dubbo官网是推荐我们使用Dubbo协议的. Sprin ...
- 基于 SpringBoot2.0+优雅整合 SpringBoot+Mybatis
SpringBoot 整合 Mybatis 有两种常用的方式,一种就是我们常见的 xml 的方式 ,还有一种是全注解的方式.我觉得这两者没有谁比谁好,在 SQL 语句不太长的情况下,我觉得全注解的方式 ...
- springboot2.0 Mybatis 整合
原文:https://blog.csdn.net/Winter_chen001/article/details/80010967 环境/版本一览: 开发工具:Intellij IDEA 2017.1. ...
- 每天学点SpringCloud(一):使用SpringBoot2.0.3整合SpringCloud
最近开始学习SpringCloud,在此把我学习的过程记录起来,跟大家分享一下,一起学习.想学习SpringCloud的同学赶快上车吧. 本次学习使用得SpringBoot版本为2.0.3.RELEA ...
随机推荐
- PHP设置时区的方法
第一种方法:修改php.ini文件 即:date.timezone = '修改的时区名称' 对全局有效 第二种方法:date_default_timezone_set()动态设置时区,只是当前 ...
- MySQL没有远程连接权限设置
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; flush privileges ...
- python学习【第十篇】单例设计模式
单例设计模式 目的:让类创建对象,在系统中只有唯一的实例,让每一次创建的对象返回的内存地址都是相同的. __new__方法 使用类名创建对象时,python解释器首先会调用__new__方法为对象分配 ...
- <转> python的垃圾回收机制
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾.在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的 ...
- 七、Dockerfile案例三(Mysql安装)
七.Dockerfile案例三(Mysql安装) *特别提醒:新版的mysql:5.7数据库下的user表中已经没有Password字段了(5.5的user表还有) 一.查看docker hub上的版 ...
- 普通摄像机也能做互联网HLS(m3u8)、RTMP、HTTP-FLV直播?是的,采用基于GBT28181协议的EasyGBS流媒体服务
在之前的一篇博客<EasyNVR和EasyDSS云平台联手都不能解决的事情,只有国标GB28181能解决了>我们介绍了很多应用场景里面,RTSP和RTMP直播协议都无法满足应用需求时,国标 ...
- 信息搜集之常见的web组合
环境: Win2003或Win7 Asp解析环境搭建 小旋风 Php解析环境搭建 phpstudy aspx解析环境搭建 IIS jsp解析环境搭建 jspstudy 常规渗透环境网络环境解析 1.操 ...
- Bridged Adapter(网桥模式)
http://www.jianshu.com/p/f59a0695b164 https://technology.amis.nl/2014/01/27/a-short-guide-to-network ...
- Java线程的5种状态及切换
ava中的线程的生命周期大体可分为5种状态. 1. 新建(NEW):新创建了一个线程对象. 2. 可运行(RUNNABLE):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方 ...
- Python菜鸟之路:Django 数据库操作进阶F和Q操作
Model中的F F 的操作通常的应用场景在于:公司对于每个员工,都涨500的工资.这个时候F就可以作为查询条件 from django.db.models import F models.UserI ...