Inception-Resnet-V2
零、Inception-Resnet-V2的网络模型
整体结构如下,整体设计简洁直观:
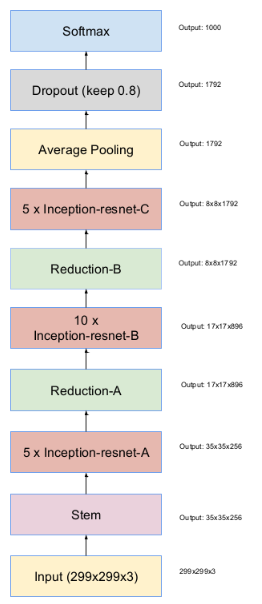
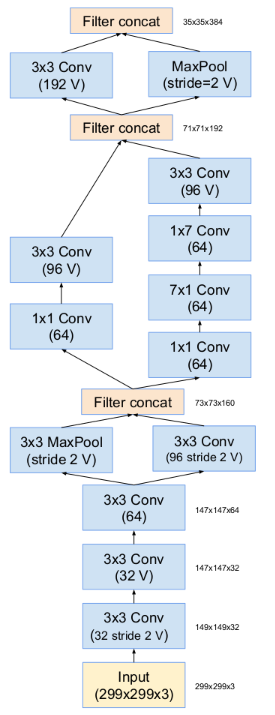
其中的stem部分网络结构如下,inception设计,并且conv也使用了7*1+1*7这种优化形式:
inception-resnet-A部分设计,inception+残差设计:
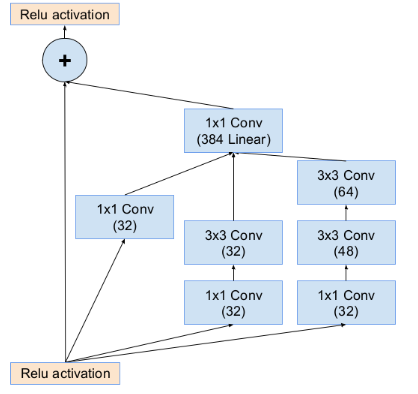
截自https://my.oschina.net/gyspace/blog/893788
一、Inception
基本思想:不需要人为决定使用哪个过滤器,或是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
细节:网络中存在softmax分支,原因——即便是隐藏单元和中间层也参与了特征计算,它们也能预测图片的分类,它在Inception网络中起到一种调整的效果,防止过拟合。
二、Resnet
残差网络就是残差块的堆叠,这样可以把网络设计的很深;
残差网络和普通网络的差异是,al+2在进行非线性变化前,把al的数据拷贝了一份与zl+2累加后进行了非线性变换;
对于普通的卷积网络,用梯度下降等常用的优化算法,随着网络深度的增加,训练误差会呈现出先降低后增加的趋势,而我们期望的理想结果是随着网络深度的增加训练误差逐渐减小,而Resnet随着网络深度的增加训练误差会一直减小。
三、1*1卷积的主要作用有以下几点:
1、降维( dimension reductionality )。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20。
2、加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
当1*1卷积出现时,在大多数情况下它作用是升/降特征的维度,这里的维度指的是通道数(厚度),而不改变图片的宽和高。
Inception-Resnet-V2的更多相关文章
- GoogLeNet 之 Inception v1 v2 v3 v4
论文地址 Inception V1 :Going Deeper with Convolutions Inception-v2 :Batch Normalization: Accelerating De ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- Feature Extractor[ResNet v2]
0. 背景 何凯明大神等人在提出了ResNet网络结构之后,对其做了进一步的分析工作,详细的分析了ResNet 构建块能起作用的本质所在.并通过一系列的实验来验证恒等映射的重要性,并由此提出了新的构建 ...
- inception - resnet
只有reduction-A是共用的,只是改了其中的几个参数 linear是线性激活. 结构是一样的
- AI:IPPR的数学表示-CNN结构进化(Alex、ZF、Inception、Res、InceptionRes)
前言: 文章:CNN的结构分析-------: 文章:历年ImageNet冠军模型网络结构解析-------: 文章:GoogleLeNet系列解读-------: 文章:DNN结构演进Histor ...
- 海康威视研究院ImageNet2016竞赛经验分享
原文链接:https://zhuanlan.zhihu.com/p/23249000 目录 场景分类 数据增强 数据增强对最后的识别性能和泛化能力都有着非常重要的作用.我们使用下面这些数据增强方法. ...
- 学习笔记TF034:实现Word2Vec
卷积神经网络发展趋势.Perceptron(感知机),1957年,Frank Resenblatt提出,始祖.Neocognitron(神经认知机),多层级神经网络,日本科学家Kunihiko fuk ...
- 谷歌开源的TensorFlow Object Detection API视频物体识别系统实现教程
视频中的物体识别 摘要 物体识别(Object Recognition)在计算机视觉领域里指的是在一张图像或一组视频序列中找到给定的物体.本文主要是利用谷歌开源TensorFlow Object De ...
- 第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理
Google在TensorFlow1.0,之后推出了一个叫slim的库,TF-slim是TensorFlow的一个新的轻量级的高级API接口.这个模块是在16年新推出的,其主要目的是来做所谓的“代码瘦 ...
- Tensorflow 使用slim框架下的分类模型进行分类
Tensorflow的slim框架可以写出像keras一样简单的代码来实现网络结构(虽然现在keras也已经集成在tf.contrib中了),而且models/slim提供了类似之前说过的object ...
随机推荐
- Matlab命令合集 妈妈再也不用担心我不会用matlab了
matlab命令 一.常用对象操作:除了一般windows窗口的常用功能键外.1.!dir 可以查看当前工作目录的文件. !dir& 可以在dos状态下查看.2.who 可以查看当前工作空间变 ...
- yii框架模型操作
命令行自动生成model模型类 php yii gii/model --ns=app\\modules\\v1\\models --tableName=SCM_tbInvBalance_new --m ...
- [原创]spring及springmvc精简版--继承数据源,声明式事物
1.前期:导入c3p0 jar包,相关数据库连接jar包,我用的是mysql 2.关注事物管理器的配置和AOP配置 代码: 核心关注bean配置文件 application.xml <?xml ...
- [C++] 麻将胡牌算法
麻将的玩法规则众多,核心的玩法是一致的,本文将根据联发科2017年编程挑战赛的复赛题规则来实现. 牌的表示方式 ABCDEFGHI代表一到九萬,abcdefghi代表一到九条,123456789代表一 ...
- INSPIRED启示录 读书笔记 - 第3章 产品管理与项目管理
互联网让两者变得不同 在传统的零售软件领域,产品经理常常兼任项目经理的工作,随着互联网的发展,两者的职责区别也越来越明显 产品管理的职责是探索(定义)有价值的.可用的.可行的产品 项目管理的职责是关注 ...
- Vue.js学习笔记 第二篇 样式绑定
Class绑定的对象语法 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- Kubernetes pod网络解析
在Kubernetes中,会为每一个pod分配一个IP地址,pod内的所有容器都共享这个pod的network namespace,彼此之间使用localhost通信. 那么pod内所有容器间的网络是 ...
- maven junit.framework不存在问题解决
问题 在使用maven进行一个工程的编译,已加入junit包的依赖,编译的时候却总是报“junit.framework不存在”错误. pom.xml中junit包加入如下: <dependenc ...
- jupyter && ipython notebook简介
2017-08-19 最近用了一下 ipython notebook 也就是 jupyter,这里有一个介绍还不错: http://www.cnblogs.com/howiewang/p/jupyte ...
- 【codevs1002】搭桥(prim)
题目描述: 这是道题题意有点迷(或者是我语文不好),但其实实际上求的就是图中连通块的个数,然后在连通块与连通块之间连边建图跑最小生成树.但是……这个图可能是不连通的……求桥的数量和总长 于是我立刻想到 ...