Word2vec之CBOW
一、Word2vec
word2vec是Google与2013年开源推出的一个用于获取word vecter的工具包,利用神经网络为单词寻找一个连续向量看空间中的表示。word2vec是将单词转换为向量的算法,该算法使得具有相似含义的单词表示为相互靠近的向量。
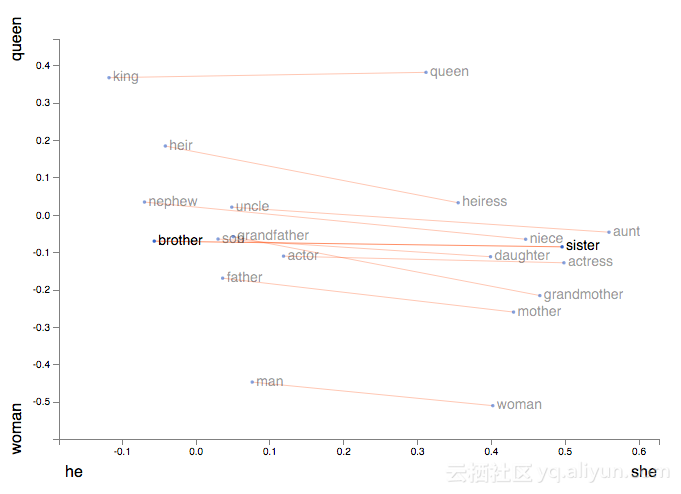
此外,它能让我们使用向量算法来处理类别,例如着名等式King−Man+Woman=Queen。
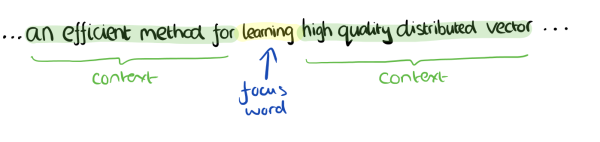
word2vec一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型:
1、CBOW:根据中心词周围的词来预测中心词,有negative sample和Huffman两种加速算法;
2、Skip-Gram:根据中心词来预测周围词;
二者的结构十分相似,理解了CBOW,对于Skip-Gram也就基本理解了。下面主要来讲讲CBOW。
来源:word2vec原理(一) CBOW与Skip-Gram模型基础
二、CBOW

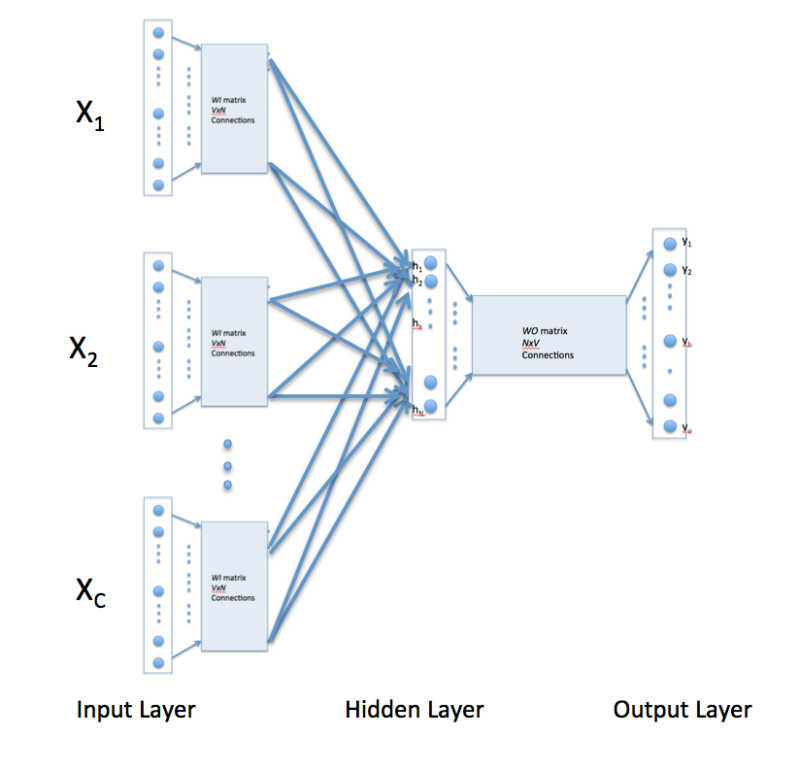
上图为CBOW的主要结构形式。对于上图,假设单词的向量空间维度为V,上下文单词个数为C,求解两个权重均值W和W'。对于上图的解释如下:
1、输入层:上下文单词的onehot形式;
2、隐藏层:将输入层所有onehot后的向量乘以第一个权重矩阵W(所有的权重矩阵相同,即共享权重矩阵),然后相加求平均作为隐藏层向量,该向量的大小与输入层的每一个样本大小相同;
3、输出层:将隐藏层向量乘以第二权重矩阵W‘,得到一个V维的向量,然后再通过激活函数(softmax)得到每一维词的概率分布,概率最大的位置所指示的单词为预测出的中间词;
4、一般使用使用的损失函数为交叉熵损失函数,采用梯度下降的方式来更新W和W’;这实际上是一个假任务,即我们需要的只是第一个权重矩阵W。得到第一个矩阵W之后,我们就能得到每个单词的词向量了。
更具体的结构以及流程如下:
来源:究竟什么是Word2vec ? Skip-Gram模型和Continuous Bag of Words(CBOW)模型 ?
I drink coffee everyday
我们使用的window size设为2。
三、word2vec的python使用
可以使用python中的gensim库。
具体可以见谈谈Word2Vec的CBOW模型最后一个部分,以及官网https://radimrehurek.com/gensim/models/word2vec.html
Word2vec之CBOW的更多相关文章
- DL4NLP——词表示模型(二)基于神经网络的模型:NPLM;word2vec(CBOW/Skip-gram)
本文简述了以下内容: 神经概率语言模型NPLM,训练语言模型并同时得到词表示 word2vec:CBOW / Skip-gram,直接以得到词表示为目标的模型 (一)原始CBOW(Continuous ...
- word2vec原理CBOW与Skip-Gram模型基础
转自http://www.cnblogs.com/pinard/p/7160330.html刘建平Pinard word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量 ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- word2vec模型cbow与skip-gram的比较
cbow和skip-gram都是在word2vec中用于将文本进行向量表示的实现方法,具体的算法实现细节可以去看word2vec的原理介绍文章.我们这里大体讲下两者的区别,尤其注意在使用当中的不同特点 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- word2vec (CBOW、分层softmax、负采样)
本文介绍 wordvec的概念 语言模型训练的两种模型CBOW+skip gram word2vec 优化的两种方法:层次softmax+负采样 gensim word2vec默认用的模型和方法 未经 ...
- NLP中word2vec的CBOW模型和Skip-Gram模型
参考:tensorflow_manual_cn.pdf Page83 例子(数据集): the quick brown fox jumped over the lazy dog. (1)CBO ...
- word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec原理(一) CBOW与Skip-Gram模型基础——转载自刘建平Pinard
转载来源:http://www.cnblogs.com/pinard/p/7160330.html word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与 ...
随机推荐
- 消息中间件JMS(二)
之前介绍了ActiveMQ下载与安装,并且启动了.下面进行ActiveMQ的Demo 1. JMS入门Demo 1.1 点对点模式 点对点模式主要建立在一个队列上面,当连接一个队列的时候,发送端不需要 ...
- oracle序列中cache和nocache
首先我这篇博客的内容是我不知道oracle里的 cache 是什么,结果越查越多... "序列的cache通常为 20,但在需要依据序列值判断创建的先后顺序时必须是 NOCACHE" ...
- 微信小程序腾讯云配置Tomcat https端口
在个人开发微信小程序时,发布之前要配置微信小程序的域名https及域名的SSL证书的申请及安装 我用的是腾讯云,SSL证书申请好之后,点击下载,解压文件夹,会有如图,根据你要配置的服务器是哪种,我是t ...
- 获取APP地图权限
获取APP地图权限 NSLocationWhenUseUsageDescription,在info里面设置为空
- JSONP 通用函数封装
function jsonp({url, params, callback}) { return new Promise((resolve, reject) => { let script = ...
- 【Nowcoder 上海五校赛】1 + 2 = 3?(斐波那契规律)
题目描述 小Y在研究数字的时候,发现了一个神奇的等式方程,他屈指算了一下有很多正整数x满足这个等式,比如1和2,现在问题来了,他想知道从小到大第N个满足这个等式的正整数,请你用程序帮他计算一下. (表 ...
- 【解决】docker 容器中 consul集群问题处理
现象描述: node1 和node2 日志反复出现 add remove node3节点. node3 节点 一直 驳回 node1 和node2 认为node3已经dead的消息 不断重启se ...
- 分别使用原生js和jQuery添加/删除元素的class属性
一.原生js添加/删除元素的class属性: <!-- span元素原有class = "test" --> <span class="test&quo ...
- 新知识 HtMl 5
快要毕业了,即将走向实习岗位,但是这日子过的太无聊了,昨天逃课回宿舍打开电脑想看电影但是没什么好看的,于是上床睡觉了,越躺越无聊,然后爬了起来到学习图书馆找了本HTML5的课本,学习了起来(我感觉ht ...
- 在Vue项目里面使用d3.js
之前写一个 Demo里面 有些东西要使用d3实现一些效果 但是在很多论坛找资源都找不到可以在Vue里面使用D3.js的方法,npm 上面的D3相对来说 可以说是很不人性化了 完全没有说 在webpac ...