ELK 搭建实战
一, 软件介绍
01,为什么用到ELK?
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大
如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的
日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建
一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据
分析-可以支持 UI 分析
警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统
elk简介:
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),
Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。 Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,
多数据源,自动搜索负载等。 Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到
的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。 Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。 Filebeat隶属于Beats。目前Beats包含四种工具: Packetbeat(搜集网络流量数据)
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat(搜集文件数据)
Winlogbeat(搜集 Windows 事件日志数据)
>>>>连接参考文档<<<<
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html elasticsearch中文社区:
https://elasticsearch.cn/
二, 基础部署
环境准备:
配置管理的 用户(默认需要使用普通用户启动)
groupadd elk
useradd -g elk elk
chown -R elk:elk /elk
对防火墙规则不熟悉的建议关闭
环境分配:
Java 环境1.8
elasticsearch 6.6.0 https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz
logstash 6.6.0 https://artifacts.elastic.co/downloads/logstash/logstash-6.6.0.tar.gz
kibana 6.6.0 https://artifacts.elastic.co/downloads/kibana/kibana-6.6.0-linux-x86_64.tar.gz
java 安装:
下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
解压安装包
tar -xzvf jdk-8u111-linux-x64.tar.gz
配置环境
vim /etc/profile
JAVA_HOME=/application/evn/jdk
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
JRE_HOME=$JAVA_HOME/jre
PATH=$JAVA_HOME/bin:$HOME/bin:$HOME/.local/bin:$PATH source /etc/profile
tar zxvf elasticsearch-6.6.0.tar-1.gz
cd elasticsearch-6.6.0/
ln -s elasticsearch-6.6.0 elasticsearch
vim config/elasticsearch.yml 修改默认配置cluster.name: elk_cluster
node.name: node-0
path.data: /elk/elasticsearch/data
path.logs: /elk/elasticsearch/logs
network.host: elk-master 填写主机名或者ip都可以,注意主机名解析
http.port: 9200
/elk/elasticsearch/bin/elasticsearch &

登入elk用户然后启动软件
su elk
/elk/elasticsearch/bin/elasticsearch &
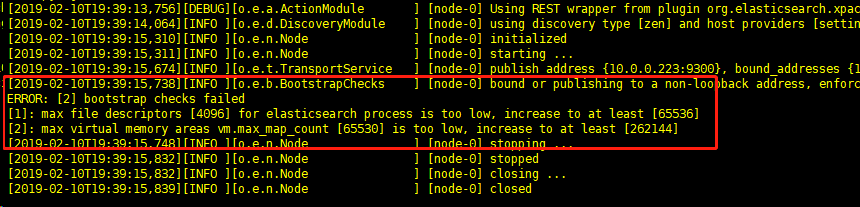
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
vi /etc/security/limits.conf
elk soft nofile 819200
elk hard nofile 819200
max number of threads [1024] for user [work] likely too low, increase to at least [2048]
vi /etc/security/limits.d/90-nproc.conf
* soft nproc 1024
#修改为:
* soft nproc 2048
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vi /etc/sysctl.conf
#增加改行配置:
vm.max_map_count=655360 sysctl -p
另外再配置ES的时候,threadpool.bulk.queue_size 已经变成了thread_pool.bulk.queue_size ,ES_HEAP_SIZE,ES_MAX_MEM等配置都变为ES_JAVA_OPTS这一配置项,如限制内存最大最小为1G:
export ES_JAVA_OPTS="-Xms1g -Xmx1g" 
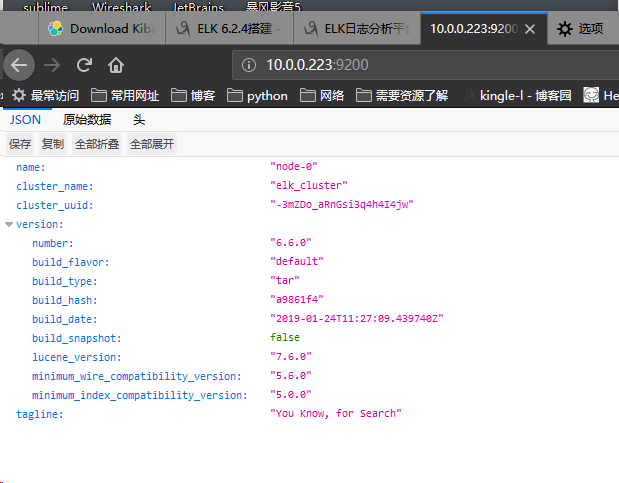
即配置成功
Logstash安装:
tar -zxvf logstash-6.6.0.tar.gz
` ln -s logstash-6.6.0 logstash
cd logstash
vim config/logstash.config
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline. input {
beats {
port => 5044
codec => "json"
}
}
filter {
#Only matched data are send to output.
#
}
output {
elasticsearch {
action => "index"
hosts => ["http://10.0.0.223:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elk"
password => "123456"
}
}
启动logstash
/elk/logstash/bin/logstash -f /elk/logstash/config/logstash.config &
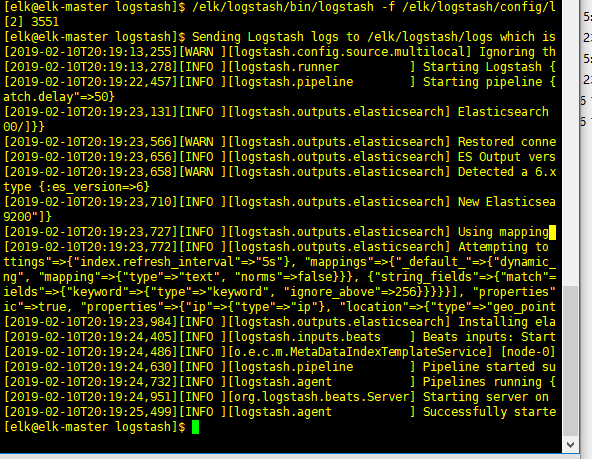
kibana 安装:
tar -zxvf kibana-6.6.-linux-x86_64.tar.gz
ln -s kibana-6.6.-linux-x86_64 kibana
cd kibana
vim config/kibana.yml
server.port:
server.host: “10.0.0.223”
elasticsearch.url: http://10.0.0.223:
kibana.index: “.kibana”

三, 使用详解

第二步

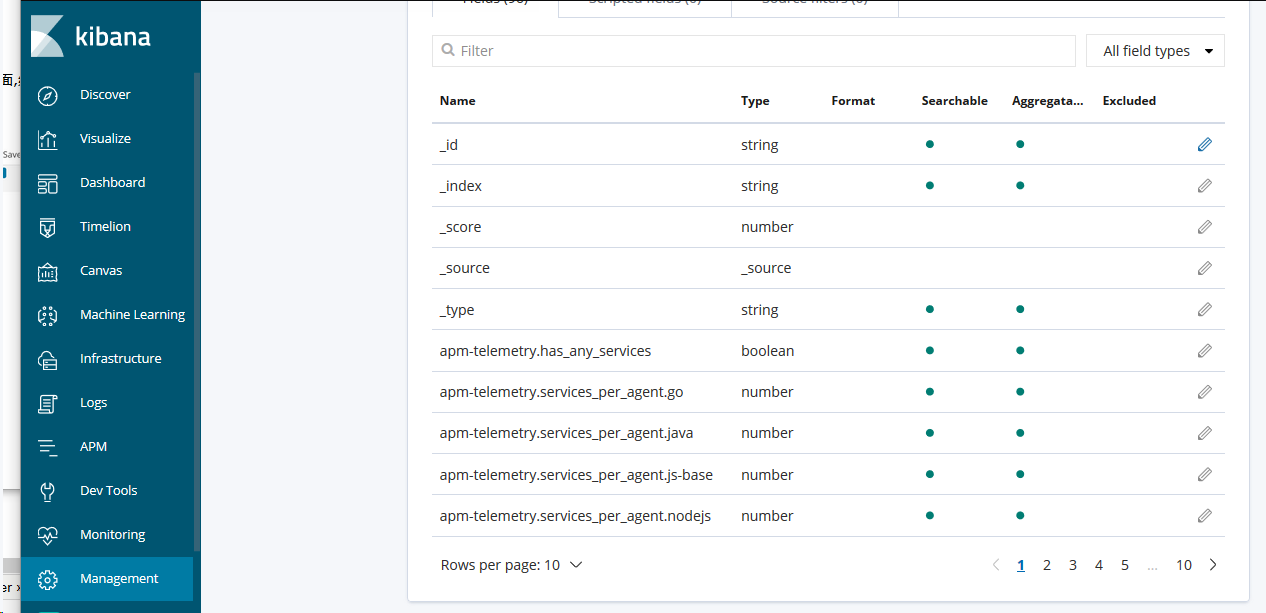
这些是自动生成的域 也可以理解为 跟数据库中的字段类似,其中有一个message字段,就是我们想要的日志信息。
再次点击discover

显示时间范围生成的日志
添加过滤
ELK 搭建实战的更多相关文章
- elk搭建实战
1 安装elasticsearch 1.1安装elasticsearch 相关中文文档:https://es.xiaoleilu.com 下载:从https://www.elastic.co/down ...
- ELK技术实战-安装Elk 5.x平台
ELK技术实战–了解Elk各组件 转载 http://www.ywnds.com/?p=9776 ELK技术实战-部署Elk 2.x平台 ELK Stack是软件集合Elasticsearch. ...
- 2018年ElasticSearch6.2.2教程ELK搭建日志采集分析系统(教程详情)
章节一 2018年 ELK课程计划和效果演示1.课程安排和效果演示 简介:课程介绍和主要知识点说明,ES搜索接口演示,部署的ELK项目演示 es: localhost:9200 k ...
- 利用 ELK 搭建 Docker 容器化应用日志中心
利用 ELK 搭建 Docker 容器化应用日志中心 概述 应用一旦容器化以后,需要考虑的就是如何采集位于 Docker 容器中的应用程序的打印日志供运维分析.典型的比如SpringBoot应用的日志 ...
- ELK搭建实时日志分析平台之二Logstash和Kibana搭建
本文书接前回<ELK搭建实时日志分析平台之一ElasticSearch> 文:铁乐与猫 四.安装Logstash logstash是一个数据分析软件,主要目的是分析log日志. 1)下载和 ...
- ELK搭建实时日志分析平台之一ElasticSearch搭建
文:铁乐与猫 系统:CentOS Linux release 7.3.1611 (Core) 注:我这里为测试和实验方便,ELK整套都装在同一台服务器环境中了,生产环境的话,可以分开搭建在不同的服务器 ...
- 用ELK搭建简单的日志收集分析系统【转】
缘起 在微服务开发过程中,一般都会利用多台服务器做分布式部署,如何能够把分散在各个服务器中的日志归集起来做分析处理,是一个微服务服务需要考虑的一个因素. 搭建一个日志系统 搭建一个日志系统需要考虑一下 ...
- ELK搭建实时日志分析平台
ELK搭建实时日志分析平台 导言 ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成,ELK平台可以同时实现日志收集.日志搜索和日志分析的功能.对于生产环境中海量日志 ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_3-05 服务注册和发现Eureka Server搭建实战
笔记 5.服务注册和发现Eureka Server搭建实战 简介:使用IDEA搭建Eureka服务中心Server端并启动,项目基本骨架介绍 官方文档:http://clou ...
随机推荐
- 从程序员角度看ELF
原文:http://xcd.blog.techweb.com.cn/archives/222.html 特殊说明(by jfo) 对于static-linked或shared-linked的ELF可执 ...
- 设计模式04: Factory Methord 工厂方法模式(创建型模式)
Factory Methord 工厂方法模式(创建型模式) 从耦合关系谈起耦合关系直接决定着软件面对变化时的行为 -模块与模块之间的紧耦合使得软件面对变化时,相关的模块都要随之变更 -模块与模块之间的 ...
- MongoDB整理笔记の安装及配置
1.官网下载 地址:http://www.mongodb.org/downloads mongodb-linux-x86_64-2.4.9.tgz (目前为止,64位最新版本) 2.解压 切换到下载目 ...
- 【转】Android系统概览
这篇文章其实原文叫 <老罗的Android之旅>导读PPT 是罗升阳的博客,我觉得用“Android系统概览”作为标题更贴切些,对于在应用层已经开发了一段时间的人来说,读完之后会有很多体会 ...
- C#向服务器上传文件问题
最近在写服务器端web上传的接口.但一直报错,上传不上去,后来发现是在分隔符中出现的问题. 错误的写法: var boundary = "---------------" + Da ...
- [database] postgresql 外网访问
配置 环境 ubuntu 14.04 LTS 版本 postgresql version 9.3 修改监听地址 编辑 /etc/postgresql/9.3/main/postgresql.conf ...
- Lucene的基本概念----转载yufenfei的文章
Lucene的基本概念 Lucene是什么? Lucene是一款高性能.可扩展的信息检索工具库.信息检索是指文档搜索.文档内信息搜索或者文档相关的元数据搜索等操作. 信息检索流程如下: 1. 将即将检 ...
- [.net 多线程]SpinWait
<CLR via C#>读书笔记-线程同步(四) 混合线程同步构造简介 之前有用户模式构造和内核模式构造,前者快速,但耗费CPU:后者可以阻塞线程,但耗时.耗资源.因此.NET会有一些混合 ...
- Asp.net负载均衡之Session
在WEB场中,动态网页往往会因为几台主机做了负载而产生SESSION丢失的问题,网上也有很多的介绍,我这里只将我经历的过程给大家分享一下: 系统要运行在负载平衡的 Web 场环境中,而系统配置文件we ...
- 快速下载android源码
众所周知的原因,android源码被墙了,还好国内有不少镜像,这里使用清华提供的镜像. 以下内容转自: https://wiki.tuna.tsinghua.edu.cn/MirrorUsage/an ...