《Hadoop权威指南》读书笔记1
《Hadoop权威指南》读书笔记
Day1
第一章
1、MapReduce适合一次写入、多次读取数据的应用,关系型数据库则更适合持续更新的数据集。
2、MapReduce是一种线性的可伸缩编程模型。
3、高性能计算HPC和网格计算比较适合用于计算密集型的作业,但如果几点需要访问的数据量更庞大,很多节点就会因为网络带宽的瓶颈问题不得不闲下等数据。(HPC和网格计算的数据存储与SAN中,数据存储比较集中,数据访问一般通过网络)
4、MapReduce尽量在计算节点上存储数据,以实现数据的本地化快速访问。数据本地化特性是MapReduce的核心特征,并因此而获得良好的性能。
5、MapReduce三大设计目标:(1)为只需要短短几分钟或几小时就可以完成的作业提供服务。(2)运行与同一个内部有高速网络连接的数据中心内(有良好的数据获取速度)(3)数据中心的计算机都是可靠的、定制的硬件。(尽量减少由于硬件异构或者硬件的故障导致的系统运行的效率降低)
第二章
1、MapReduce任务过程分为两个处理阶段:map阶段和reduce阶段。每个阶段都以键值对作为输入和输出。
2、新旧Java MapReduce API区别:新API倾向于使用虚类,而不是接口,因为更有利于扩展。(为什么?)
3、map任务将其输出写入本地硬盘,而非HDFS,因为输出的中间结果,一旦作业完成中间结果就可以删除了,如果存入HDFS中并实现备份,没有太大意义。,即使中间结果意外丢失,也可以通过令另一个节点重新执行该任务即可。Reduce任务并不具备数据本地化优势,因为单个reduce任务的输入通常来自于所有mapper的输出,并且reduce的输出即为本次MapReduce任务的最终结果,所以通常将其存储在HDFS上实现可靠存储。
第三章
1、HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。其特点是:
l 能够存储超大文件
l 流式数据访问(一次写入,多次读取)
l 商用硬件
l 要求低时间延迟的数据访问的应用不适合运行在HDFS上。HDFS是为高数据吞吐量应用优化的,这可能以提高时间延迟为代价。
l 大量的小文件。(由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限与namenode的内存容量)
l HDFS中文件可能只有一个writer,而且写操作总是将数据添加在文件的末尾。不支持多个写入者的操作,也不支持文件任意位置进行修改。
2、HDFS中有块的概念,默认为64MB,每个文件被划分为块大小多个分块,作为独立存储单元(有利于并行读取,以及负载均衡)。小于默认块大小的文件不会占据整个块的空间。
3、HDFS中引入块的概念的好处:
l 文件的大小可以大于网络中任意一次磁盘的容量。
l 使用抽象块存储而非整个文件作为存储单元,大大简化了存储子系统的设计。
l 块还非常适合用于数据备份进而提供数据的容错能力和提高可用性。
4、HDFS采用类似GFS的主从结果(master/slave),即系统中由一个管理者namenode和多个从节点datanode结构构成。Namenode负责管理文件系统的命名空间,维护文件系统的树以及整颗树内所有的文件和目录。主要提供的就是名字服务功能。Datanode是文件系统的工作节点。Datanode根据需要存储并检索数据块(受客户端或namenode调度),并且定期想namenode发送他们所存储的块的列表。主从结构的最大问题是master节点存在单点故障的风险(SPOF)。目前openstack等对等结构的存储系统就可以有效避免此问题。
5、seek()方法是一个先对高开销的操作,需要谨慎使用。建议用流数据来构建应用的访问模式,而非执行大量的seek方法。
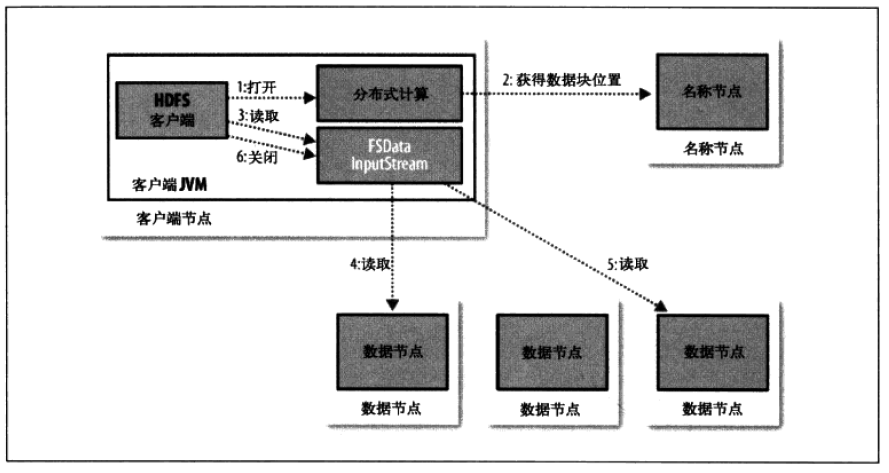
6、HDFS数据读取数据流
7、HDFS数据写入数据流
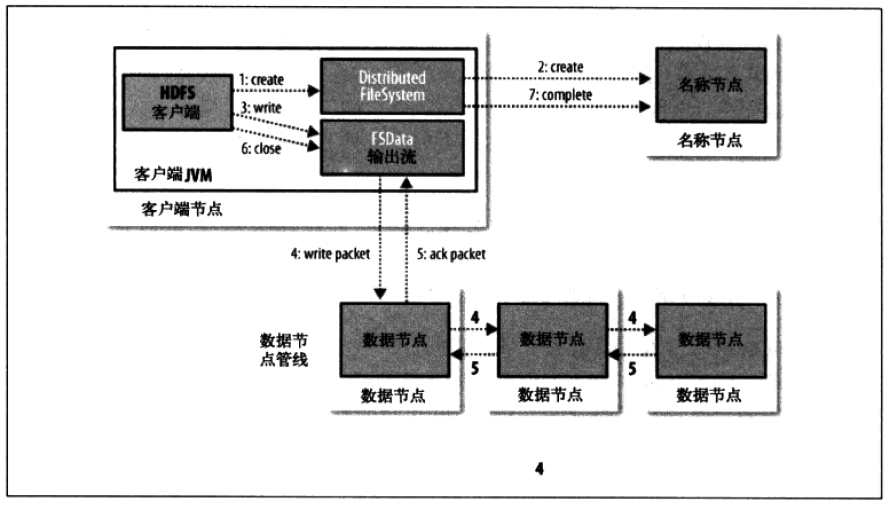
在客户端写入数据时,DFSOutputStream将它分成一个个的数据包,并写入内部队列,数据队列。DataStreamer处理数据队列,它的责任是根据datanode列表来要求namenode分配合适的新块来存储时间的副本。
8、由于每个文件的元数据都要存储在namenode的内存中,如果有大量的小文件存储在HDFS中,那么将会占用namenode中大量的内存。因此HDFS支持将多个小文件进行存档。Hadoop存档文件或HAR文件,是一个更高效的文件存档工具,能够减少namenode内存的使用的同时,允许对文件进行透明的访问。
第四章
1、HDFS会对写入的所有数据计算校验和,并在读取数据时验证校验和。其中datanode负责在收到数据后存储该数据及其验证校验和,管线中最后一个datanode负责验证校验和。客户端在读取数据时,也会验证校验和。最后,每个datanode中会有一个后台线程运行一个DataBlockScanner,定期验证存储在这这个datanode上的所有数据块。
2、HDFS中对文件进行压缩,以达到减少文件存储所需的空间,以及加速数据在网络和磁盘上的传输。对于压缩文件后是否可切分是评价一个压缩算法在MapReduce中是否合适的重要指标。
3、对于map任务的输出也可以进行压缩。同时对于MapReduce最终的结果也可以使用压缩输出。
4、由于MapReduce中数据一般都是需要在网络或者磁盘上存储或者传输,所以需要把许多数据进行序列化。
5、RPC序列化格式需要:
l 紧凑
l 快速
l 可扩展
l 支持互操作
6、Writabale接口定义了序列化和反序列化两个方法。
《Hadoop权威指南》读书笔记1的更多相关文章
- 《Linux/Unix系统编程手册》读书笔记 目录
<Linux/Unix系统编程手册>读书笔记1 (创建于4月3日,最后更新4月7日) <Linux/Unix系统编程手册>读书笔记2 (创建于4月9日,最后更新4月10日) ...
- 《Linux/Unix系统编程手册》读书笔记9(文件属性)
<Linux/Unix系统编程手册>读书笔记 目录 在Linux里,万物皆文件.所以文件系统在Linux系统占有重要的地位.本文主要介绍的是文件的属性,只是稍微提及一下文件系统,日后如果有 ...
- 《Linux/Unix系统编程手册》读书笔记8 (文件I/O缓冲)
<Linux/Unix系统编程手册>读书笔记 目录 第13章 这章主要将了关于文件I/O的缓冲. 系统I/O调用(即内核)和C语言标准库I/O函数(即stdio函数)在对磁盘进行操作的时候 ...
- 《Linux/Unix系统编程手册》读书笔记7 (/proc文件的简介和运用)
<Linux/Unix系统编程手册>读书笔记 目录 第11章 这章主要讲了关于Linux和UNIX的系统资源的限制. 关于限制都存在一个最小值,这些最小值为<limits.h> ...
- 《Linux/Unix系统编程手册》读书笔记6
<Linux/Unix系统编程手册>读书笔记 目录 第9章 这章主要讲了一堆关于进程的ID.实际用户(组)ID.有效用户(组)ID.保存设置用户(组)ID.文件系统用户(组)ID.和辅助组 ...
- 《Linux/Unix系统编程手册》读书笔记5
<Linux/Unix系统编程手册>读书笔记 目录 第8章 本章讲了用户和组,还有记录用户的密码文件/etc/passwd,shadow密码文件/etc/shadow还有组文件/etc/g ...
- 《Linux/Unix系统编程手册》读书笔记4
<Linux/Unix系统编程手册>读书笔记 目录 第7章: 内存分配 通过增加堆的大小分配内存,通过提升program break位置的高度来分配内存. 基本学过C语言的都用过mallo ...
- 《Linux/Unix系统编程手册》读书笔记3
<Linux/Unix系统编程手册>读书笔记 目录 第6章 这章讲进程.虚拟内存和环境变量等. 进程是一个可执行程序的实例.一个程序可以创建很多进程. 进程是由内核定义的抽象实体,内核为此 ...
- 《Linux/Unix系统编程手册》读书笔记1
<Linux/Unix系统编程手册>读书笔记 目录 最近这一个月在看<Linux/Unix系统编程手册>,在学习关于Linux的系统编程.之前学习Linux的时候就打算写关于L ...
- 《Linux/Unix系统编程手册》读书笔记2
<Linux/Unix系统编程手册>读书笔记 目录 第5章: 主要介绍了文件I/O更深入的一些内容. 原子操作,将一个系统调用所要完成的所有动作作为一个不可中断的操作,一次性执行:这样可以 ...
随机推荐
- Python爬虫:带参url的拼接
如果连接直接这样写,看上去很直观,不过参数替换不是很方便,而且看着不舒服 https://www.mysite.com/?sortField=%E4%BA%BA%E5%B7%A5%E6%99%BA%E ...
- Nginx 进行性能配置
总所周知,网络上我们购买的服务器的性能各不相同,如果采用 Nginx 的默认配置的话,无法将服务器的全部性能优势发挥出来,我们应该选择适合自己需求的配置. 当我们默认安装后 Nginx 后,我们便得到 ...
- 题解 CF948A 【Protect Sheep】
题目链接 额..这道题亮点在: $you$ $do$ $not$ $need$ $to$ $minimize$ $their$ $number.$ 所以说嘛... 直接判断狼的四周有没有紧挨着的羊,没 ...
- bzoj2564: 集合的面积(闵可夫斯基和 凸包)
题面 传送门 题解 花了一个下午的时间调出了一个稍微能看的板子--没办法网上的板子和咱的不太兼容-- 首先有一个叫做闵可夫斯基和的东西,就是给你两个点集\(A,B\),要你求一个点集\(C=\{x+y ...
- HDU6300-2018ACM暑假多校联合训练1003-Triangle Partition
题意是给3n个点,其中不可能存在任意三点共线的情况,让你在其中建n个三角形,点不能重复使用,三角形不能相互覆盖 做法是给每个点排序,按照先y轴排,再x轴排的顺序,三个三个一组从下往上输出,有人说是凸包 ...
- 洛谷 P1579 哥德巴赫猜想(升级版)
嗯... 这或许也算一道数论题吧... 题目链接:https://www.luogu.org/problemnew/show/P1579 这道题的说明好像只会扰乱人的思路....然后就是这道题的细节比 ...
- OEL6.8安装虚拟带库模拟器
最近在虚拟机下搭建了一个OSB备份环境,其中使用到了虚拟带库,以下是虚拟带库的配置过程,简要记录之. 1.下载虚拟带库的源码(mhvtl-2016-03-10.tgz). 2.解压缩源码. # cd ...
- Qt 学习之路 2(45):模型
Home / Qt 学习之路 2 / Qt 学习之路 2(45):模型 Qt 学习之路 2(45):模型 豆子 2013年2月26日 Qt 学习之路 2 23条评论 在前面两章的基础之上,我们 ...
- windows cmd下创建虚拟环境virtualenv
一:虚拟环境virtualenv 如果在一台电脑上, 想开发多个不同的项目, 需要用到同一个包的不同版本, 如果使用上面的命令, 在同一个目录下安装或者更新, 新版本会覆盖以前的版本, 其它的项目就无 ...
- VBS常用脚本及其解说一览
取得本机IP strComputer = "." Set objWMIService = GetObject("winmgmts:\\" & strCo ...