字符编码py2,py3操作,SecureCRT的会话编码的设置
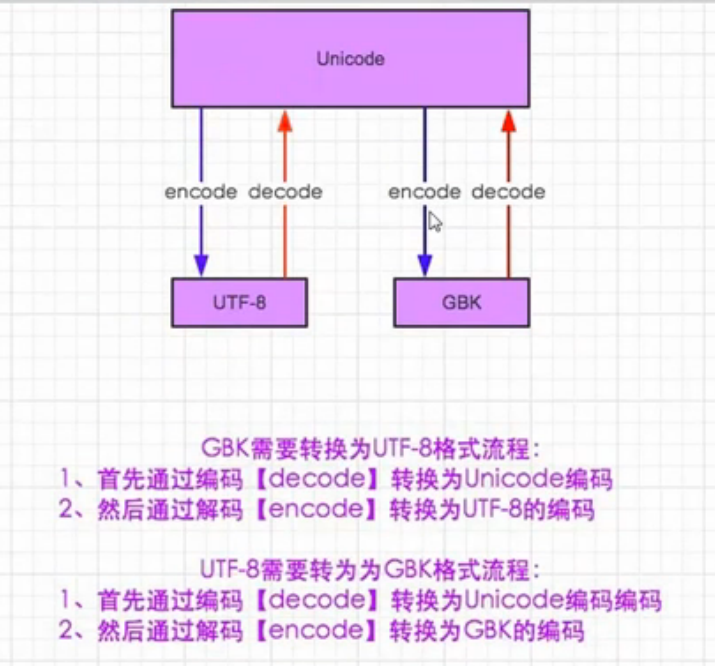
对之前的字符串类型和二进制类型(bytes类型),可以这样关联记忆,把字符串类型当作是Unicode,把bytes类型当作是GBK或者UTF-8或者是日文编码。这样字符串要转成二进制,那么就需要编码encode,二进制要转成字符串就需要解码decode。
在python3里,所有的字符默认编码是Unicode,在python2里,所有字符默认是Ascii。
只有加了如下代码,才表示默认编码是啥:
#-*- coding:utf-8 -*-
下面所有的代码都在python2.7下运行的结果:
在SecureCRT里的,如果操作linux,打中文是乱码的话,说明会话的字符集不是UTF-8,需要设置下:
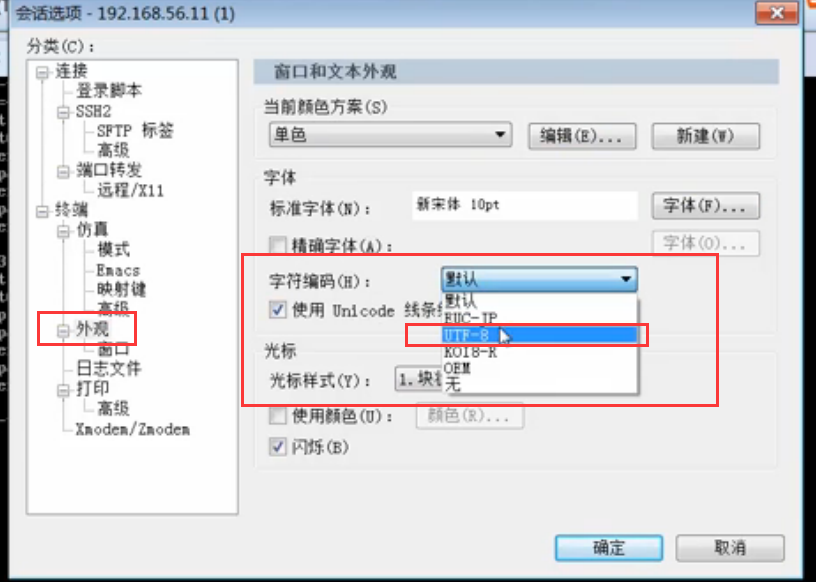
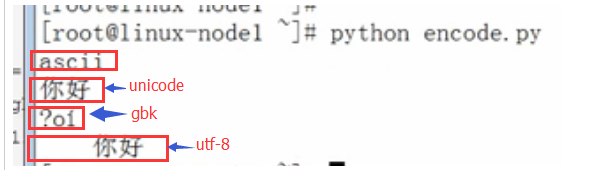
打印当前python的默认编码:python2是Ascii,python3是utf-8
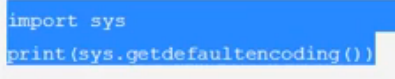
import sys
print(sys.getdefaultencoding())
如果你对utf-8的字符串不进行解码(或者decode()里面啥都不写)就进行编码,系统会自动用Ascii码对你的字符串进行先解码。如下图的报错情况:

或者decode()为空,里面啥都不写,如下图:
报错如下:ascii不能解码为GBK

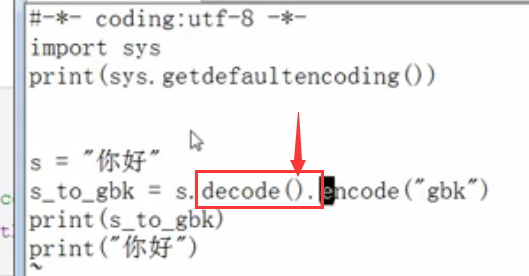
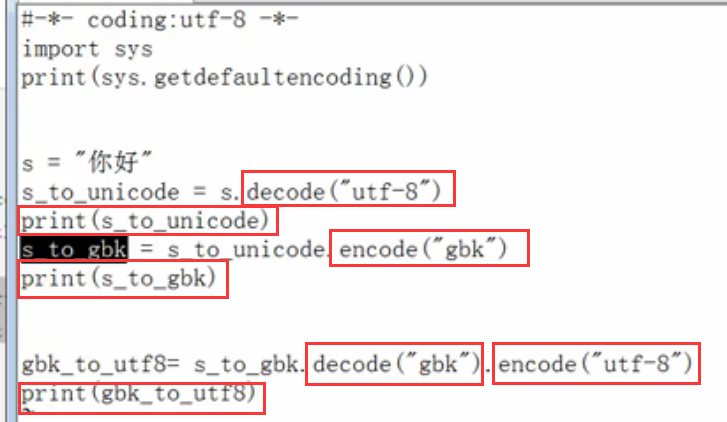
现在下面我们演示,把utf-8转换为GBK的代码:

所以,在py3里s="hi all" #这里的s,依旧是unicode,这个是字符串编码,而在py2里,s已经是utf-8的数据编码了
这里的代码过程是这样,代码的当前编码为utf-8,所以s="你好",就是utf-8的字符串编码,
utf-8要想转换为GBK,那么需要首先decode解码为Unicode,请注意这里一定要写decode("utf-8"),这个utf-8不可以省略!!!表示字符串的编码是utf-8
然后Unicode再编码为GBK,即为encode("gbk"),这里的GBK不可以省略!!!表示要转换为GBK编码!!!
但是实际操作中,上面的代码使用SecureCRT进行代码编程的时候,有其他问题:
我们首先将utf-8的代码转成unicode,并打印出来:我们默认SecureCRT的会话编码目前为UTF-8:
如下图,虽然SecureCRT的 会话编码为UTF-8,但是你打印unicode,一样会显示中文。因为unicode包括utf-8,utf-8只是unicode的扩展集。
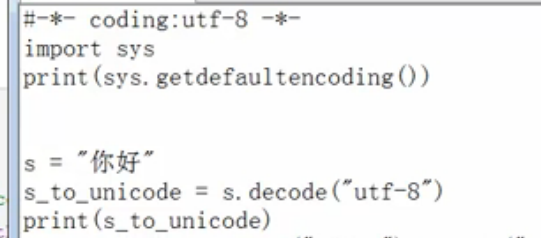

这边有一个小插曲,如果你再打印unicode的类型,会出现如下的结果:


结果会,原来显示中文的,变成乱码了(其实不是乱码,而是unicode编码,前面有一个u字母,这个是对的),
这个是因为,你加了一个打印字符类型,那么这里就变成打印一个元祖字符类型出来,而元祖的字符类型是不会显示中文的!!!
如果你想打印中文,就单独打印,不要加一个字符类型,变成元祖了。
我们继续测试代码:我们将字符串转换为gbk:


上图发现在默认SecureCRT的会话编码Terminal目前为UTF-8的情况下,如果你打印GBK格式的话,会显示乱码,这个是对的。
这个时候,我们把会话编码改成默认,因为你选择默认的话,那么编码就随系统windows走,会GBK编码:
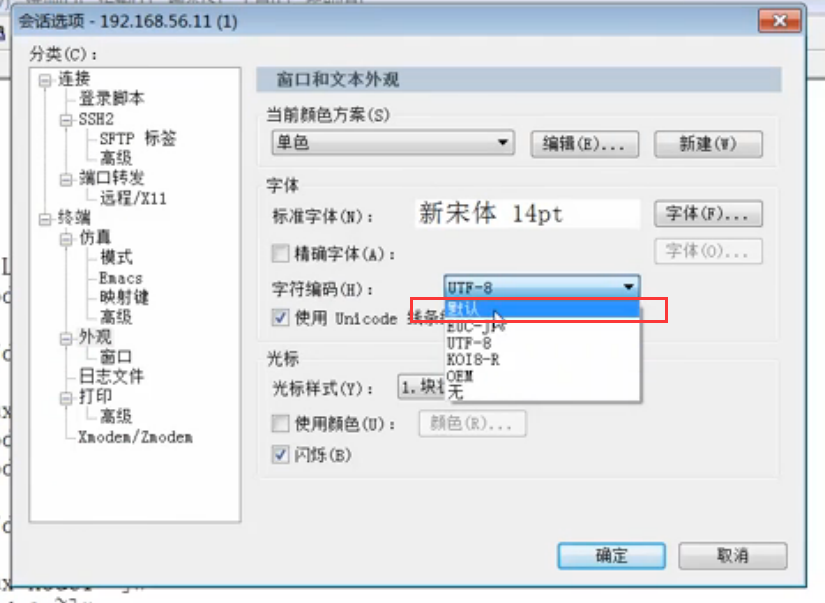
这个时候,我们再运行一次程序:发现gbk的中文正确显示了:说明默认为随系统的默认编码走了!

我们这个时候恢复unicode的打印,如下:同时把默认SecureCRT的会话编码Terminal改为默认的GBK:

结果如下:

结论:这里有个特殊情况:
1、如果默认SecureCRT的会话编码Terminal为默认的gbk,那么打印字符串为unicode无法显示;因为两个字符集不同。
2、如果默认SecureCRT的会话编码Terminal为utf-8,那么打印字符串为unicode可以正确显示。因为utf-8是unicode的扩展集。
最终,我们把转过去的gbk,再转回为utf-8,最终代码如下:当前CRT的会话编码为utf-8
字符串可以直接在前面加一个字母u,来代表是unicode字符串:注意这里的u必须在封号""之外写,不可以写到里面

这里的s就是unicode编码。
上面都是python2,那么下面的代码,是运行在python3里的。
py3里,只有 unicode编码格式 的字节串才能叫作str。
其他编码格式的统统都叫bytes,如:gbk,utf-8,gb2312…………
这些bytes要转换为 unicode编码 才能当作str来用,就需要知道 bytes 的编码格式。
如果你事先知道,比如gbk,就可以用 bytes.decode('gbk')将bytes解码为unicode字符。
如果很不幸,你有一堆bytes,不知道它们的编码(例如 网站服务器返回的响应体),
这时候,你就需要chardet 来测试它们的编码。
首先,我们测试,python3的默认字符串编码是unicode:
我们定义一个字符串,因为默认是unicode,所以我们一开始根本就没有decode()的方法
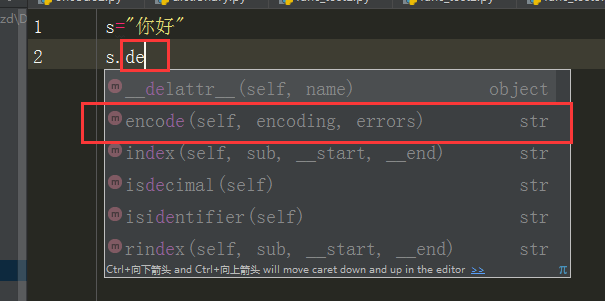
那么我们编码为gbk,运行居然乱码,这个是为什么呢?其实不是乱码,而是转为了二进制的bytes类型,在py3里,所有的非unicode的字符串,都会转换为二进制编码,bytes类型

导师给了一个结论,所有的编码分为两种情况,一个是内存(字符串)编码,一个是硬盘(文件存储)编码:
注意使用的场景不一样,字符串编码是在内存里用的,硬盘是文件保存的时候使用的编码,而文件存储一般使用utf-8,因为存储的时候使用utf-8更节省空间,英文1个字符,欧洲2个字符,东亚中文等3个字符。
字符在计算机的内存中统一是以Unicode编码的。只有在字符要被写进文件、存进硬盘或者从服务器发送至客户端(例如网页前端的代码)时会变成utf-8
所以,在py3里s="hi all" #这里的s,依旧是unicode,这个是字符串编码,而在py2里,s已经是utf-8的数据编码了
包括在pycharm的右下角,显示的utf-8,也是文件的存储编码,跟字符串编码无关。
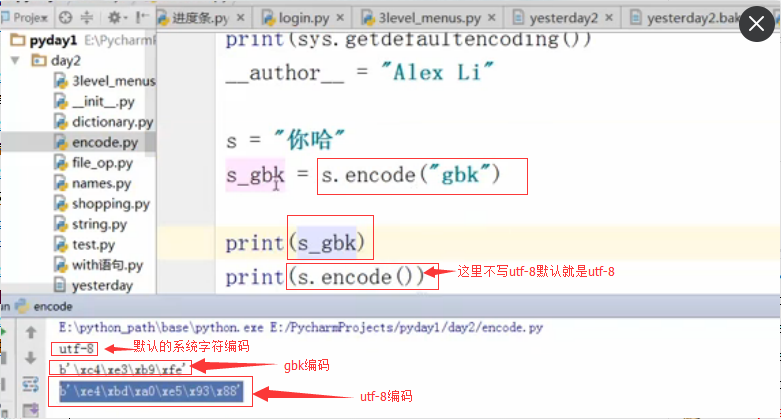
中文gbk编码是2个字符,而utf-8是3个字符,所以上图utf-8要比GBK更长1个字节
如果只是更改了pycharm右下角的文件存储编码,那么会报错的:因为当前文件存储编码是GBK了,你默认还是utf-8,就报错了。
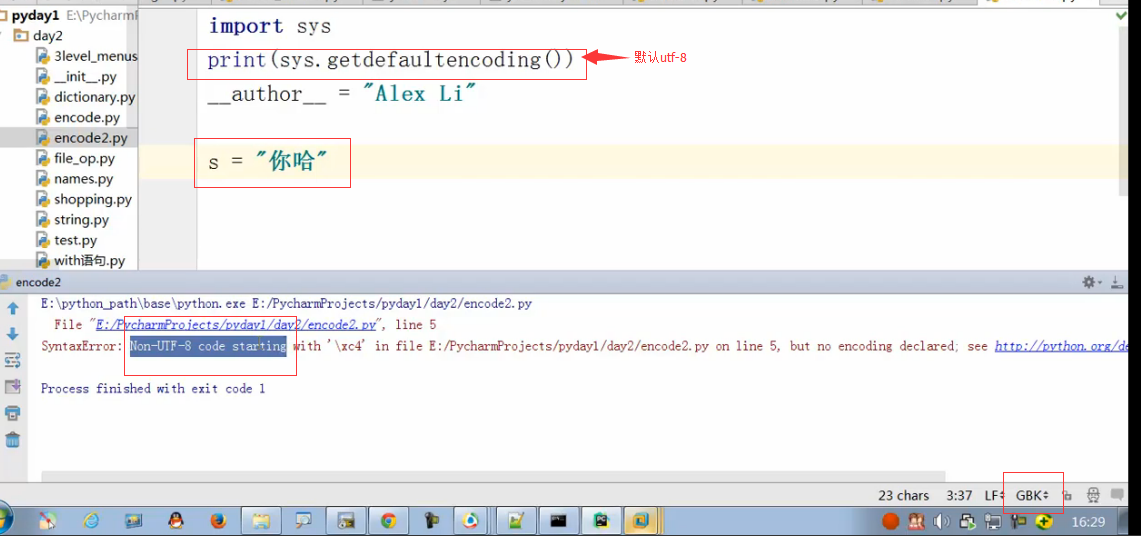
所以在文件头也申明,程序的编码为gbk跟文件编码保持一致:看下面的截图,两个蓝色的框必须保持编码一致:这样就不会报错了。

特别要注意,不管你文件编码,编程代码编码怎么变,字符串赋值的一定是unicode,如上图的变量s就是unicode编码。这个是py3的特有特性!!!
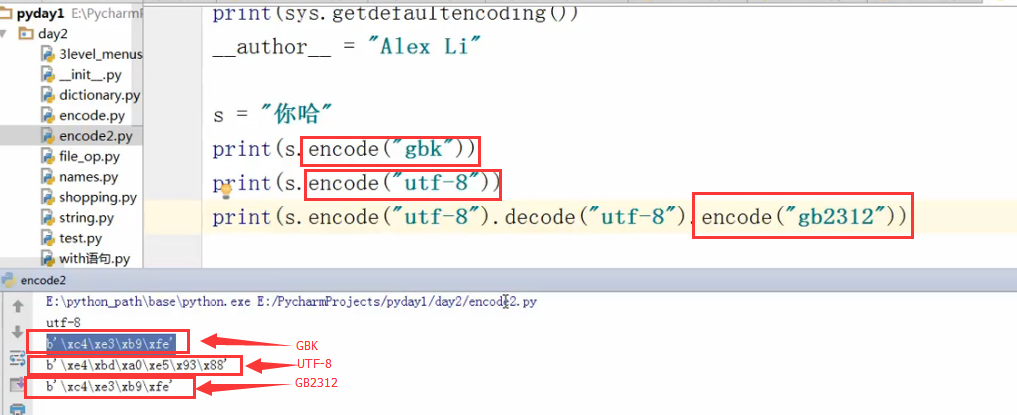
发现GBK或者GB2312的bytes数据类型是一样的。因为“你哈”在这两个类型都有。
gb2312是gbk的子集。
字符编码py2,py3操作,SecureCRT的会话编码的设置的更多相关文章
- Python 字符编码及其文件操作
本章节内容导航: 1.字符编码:人识别的语言与机器机器识别的语言转化的媒介. 2.字符与字节:字符占多少个字节,字符串转化 3.文件操作:操作硬盘中的一块区域:读写操作 注:浅拷贝与深拷贝 用法: d ...
- DAY7 字符编码和文件操作
一.软件与python解释器打开文件的方法 1.软件打开文件读取数据的流程: 1. 打开软件 2. 往计算机发生一个打开文件的指令,来打开文件 3. 读取数据渲染给用户(存取编码不一致:乱码) 2.p ...
- Day 07 字符编码,文件操作
今日内容 1.字符编码:人识别的语言与机器识别的语言转换的媒介 2.字符与字节:字符占多少字节,字符串转换 3.文件操作:操作硬盘的一块区域 字符编码 重点:什么是字符编码 人类能识别的字符等高级标识 ...
- python基础——6(字符编码,文件操作)
今日内容: 1.字符编码: 人识别的语言与机器识别的语言转化的媒介 ***** 2.字符与字节: 字符占多少字节,字符串转化 *** 3.文件操作: 操作硬盘中的一块区域:读写操作 ...
- python基础--字符编码以及文件操作
字符编码: 1.运行程序的三个核心硬件:cpu.内存.硬盘 任何一个程序要是想要运算,肯定是先从硬盘加载到当前的内存中,然后cpu根据指定的指令去执行操作 2.python解释器运行一个py文件的步骤 ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- python字符编码与文件操作
目录 字符编码 字符编码是什么 字符编码的发展史 字符编码实际应用 编码与解码 乱码问题 python解释器层面 文件操作 文件操作简介 文件的内置方法 文件的读写模式 文件的操作模式 作业 答案 第 ...
- python自动化开发-[第三天]-编码,函数,文件操作
今日概要 - 编码详解 - 文件操作 - 初识函数 一.字符编码 1.代码执行过程 代码-->解释器翻译-->机器码-->执行 2.ASCII ASCII:一个Bytes代表一个字符 ...
- C语言:宽字符集操作函数(unicode编码)
C语言:宽字符集操作函数(unicode编码) 字符分类: 宽字符函数 普通C函数描述 iswalnum() isalnum() 测试字符是否为数字或字母 iswalpha() isalpha() 测 ...
随机推荐
- EntityFramework之领域驱动设计实践
EntityFramework之领域驱动设计实践 - 前言 EntityFramework之领域驱动设计实践 (一):从DataTable到EntityObject EntityFramework之领 ...
- python学习笔记(pip下载安装)
python有很多扩展模块需要安装 这个时候万能的pip就可以提供帮助 首页进入官网下载压缩包: https://pypi.python.org/pypi/pip#downloads 解压文件 cmd ...
- MFC--自定义CMFCTabCtrl的实现
在MFC实现桌面程序时,可能会用到TabView效果,我实现的是最基本的效果,如下图: 下面介绍详细的实现过程,如果需要效果更好看些,自行美化. 1. 创建自定义MFCTabCtrl类MyMFCTa ...
- 在js中,ajax放在for中,ajax获取得到的变量有误
先看代码 for(var i=0;i<tds.length;i++){ mui.ajax(url+'api/client/gifts/isSigned', {data :{ sqId:" ...
- python面向对象编程 继承 组合 接口和抽象类
1.类是用来描述某一类的事物,类的对象就是这一类事物中的一个个体.是事物就要有属性,属性分为 1:数据属性:就是变量 2:函数属性:就是函数,在面向对象里通常称为方法 注意:类和对象均用点来访问自己的 ...
- python迭代器与生成器(二)
一.什么是迭代? 迭代通俗的讲就是一个遍历重复的过程. 维基百科中 迭代(Iteration) 的一个通用概念是:重复某个过程的行为,这个过程中的每次重复称为一次迭代.具体对应到Python编程中 ...
- [转载]java调用PageOffice生成word
一.在开发OA办公或与文档相关的Web系统中,难免会遇到动态生成word文档的需求,为了解决工作中遇到导出word文档的需求,前一段时间上网找了一些资料,在word导出这方面有很多工具可以使用,jac ...
- PCB寻找器件
1.如果你知道元件的序号(designator),可以按下J,C,然后输入序号跳到元件所在位置,元件会出现在屏幕中心.2.如果是sch跟pcb在同一个project下,你从原理图选定元件,然后右键元件 ...
- .zip.001 -- .zip.003解压缩
一.源文件移到固定短路径 二.cmd执行合并 copy /B 201702.zip.001 + 201702.zip.002 + 201702.zip.003 1.zip 三.WinRAR解压缩
- poj1469
题解: 二分图匹配 然后判断最大匹配是否是m 代码: #include<cstdio> #include<cmath> #include<algorithm> #i ...