决策树ID3算法--python实现
参考:
统计学习方法》第五章决策树】 http://pan.baidu.com/s/1hrTscza


#coding:utf-8
# ID3算法,建立决策树
import numpy as np
import math
import uniout
'''
#创建数据集
def creatDataSet():
dataSet = np.array([[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']])
features = ['no surfaceing', 'fippers']
return dataSet, features
''' #创建数据集
def createDataSet():
dataSet = np.array([['青年', '否', '否', '否'],
['青年', '否', '否', '否'],
['青年', '是', '否', '是'],
['青年', '是', '是', '是'],
['青年', '否', '否', '否'],
['中年', '否', '否', '否'],
['中年', '否', '否', '否'],
['中年', '是', '是', '是'],
['中年', '否', '是', '是'],
['中年', '否', '是', '是'],
['老年', '否', '是', '是'],
['老年', '否', '是', '是'],
['老年', '是', '否', '是'],
['老年', '是', '否', '是'],
['老年', '否', '否', '否']])
features = ['年龄', '有工作', '有自己房子']
return dataSet, features #计算数据集的熵
def calcEntropy(dataSet):
#先算概率
labels = list(dataSet[:,-1])
prob = {}
entropy = 0.0
for label in labels:
prob[label] = (labels.count(label) / float(len(labels)))
for v in prob.values():
entropy = entropy + (-v * math.log(v,2))
return entropy #划分数据集
def splitDataSet(dataSet, i, fc):
subDataSet = []
for j in range(len(dataSet)):
if dataSet[j, i] == str(fc):
sbs = []
sbs.append(dataSet[j, :])
subDataSet.extend(sbs)
subDataSet = np.array(subDataSet)
return np.delete(subDataSet,[i],1) #计算信息增益,选择最好的特征划分数据集,即返回最佳特征下标
def chooseBestFeatureToSplit(dataSet):
labels = list(dataSet[:, -1])
bestInfoGain = 0.0 #最大的信息增益值
bestFeature = -1 #*******
#摘出特征列和label列
for i in range(dataSet.shape[1]-1): #列
#计算列中,各个分类的概率
prob = {}
featureCoulmnL = list(dataSet[:,i])
for fcl in featureCoulmnL:
prob[fcl] = featureCoulmnL.count(fcl) / float(len(featureCoulmnL))
#计算列中,各个分类的熵
new_entrony = {} #各个分类的熵
condi_entropy = 0.0 #特征列的条件熵
featureCoulmn = set(dataSet[:,i]) #特征列
for fc in featureCoulmn:
subDataSet = splitDataSet(dataSet, i, fc)
prob_fc = len(subDataSet) / float(len(dataSet))
new_entrony[fc] = calcEntropy(subDataSet) #各个分类的熵
condi_entropy = condi_entropy + prob[fc] * new_entrony[fc] #特征列的条件熵
infoGain = calcEntropy(dataSet) - condi_entropy #计算信息增益
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature #若特征集features为空,则T为单节点,并将数据集D中实例树最大的类label作为该节点的类标记,返回T
def majorityLabelCount(labels):
labelCount = {}
for label in labels:
if label not in labelCount.keys():
labelCount[label] = 0
labelCount[label] += 1
return max(labelCount) #建立决策树T
def createDecisionTree(dataSet, features):
labels = list(dataSet[:,-1])
#如果数据集中的所有实例都属于同一类label,则T为单节点树,并将类label作为该结点的类标记,返回T
if len(set(labels)) == 1:
return labels[0]
#若特征集features为空,则T为单节点,并将数据集D中实例树最大的类label作为该节点的类标记,返回T
if len(dataSet[0]) == 1:
return majorityLabelCount(labels)
#否则,按ID3算法就计算特征集中各特征对数据集D的信息增益,选择信息增益最大的特征beatFeature
bestFeatureI = chooseBestFeatureToSplit(dataSet) #最佳特征的下标
bestFeature = features[bestFeatureI] #最佳特征
decisionTree = {bestFeature:{}} #构建树,以信息增益最大的特征beatFeature为子节点
del(features[bestFeatureI]) #该特征已最为子节点使用,则删除,以便接下来继续构建子树
bestFeatureColumn = set(dataSet[:,bestFeatureI])
for bfc in bestFeatureColumn:
subFeatures = features[:]
decisionTree[bestFeature][bfc] = createDecisionTree(splitDataSet(dataSet, bestFeatureI, bfc), subFeatures)
return decisionTree #对测试数据进行分类
def classify(testData, features, decisionTree):
for key in decisionTree:
index = features.index(key)
testData_value = testData[index]
subTree = decisionTree[key][testData_value]
if type(subTree) == dict:
result = classify(testData,features,subTree)
return result
else:
return subTree if __name__ == '__main__':
dataSet, features = createDataSet() #创建数据集
decisionTree = createDecisionTree(dataSet, features) #建立决策树
print 'decisonTree:',decisionTree dataSet, features = createDataSet()
testData = ['老年', '是', '否']
result = classify(testData, features, decisionTree) #对测试数据进行分类
print '是否给',testData,'贷款:',result
相关理论:
决策树
概念原理
决策树是一种非参数的监督学习方法,它主要用于分类和回归。决策树的目的是构造一种模型,使之能够从样本数据的特征属性中,通过学习简单的决策规则——IF THEN规则,从而预测目标变量的值。
决策树学习步骤:1 特征选择 2 决策树的生成 3 决策树的修剪
那么如何进行特征选择:
由于特征选择的方法不同,衍生出了三种决策树算法:ID3、C4.5、CART
ID3信息增益

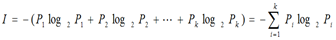 熵越大,随机变量的不确定性越大。
熵越大,随机变量的不确定性越大。
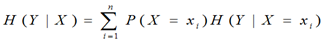 条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。所谓信息量,就是熵。
C4.5信息增益比

CART 基尼指数
 基尼指数越大,样本的不确定性就越大
基尼指数越大,样本的不确定性就越大
三个算法的优缺点
|
ID3算法 |
C4.5算法 |
CART算法(Classification and Regression Tree) |
|
以信息增益为准则选择信息增益最大的属性。 2)ID3只能对离散属性的数据集构造决策树。 |
以信息增益率为准则选择属性;在信息增益的基础上对属性有一个惩罚,抑制可取值较多的属性,增强泛化性能。 1)在树的构造过程中可以进行剪枝,缓解过拟合; 2)能够对连续属性进行离散化处理(二分法); 3)能够对缺失值进行处理; |
顾名思义,可以进行分类和回归,可以处理离散属性,也可以处理连续的。 |
ID3、C4.5、CART区别 参考:https://www.zhihu.com/question/27205203?sort=created

决策树ID3算法--python实现的更多相关文章
- 决策树ID3算法python实现 -- 《机器学习实战》
from math import log import numpy as np import matplotlib.pyplot as plt import operator #计算给定数据集的香农熵 ...
- 决策树---ID3算法(介绍及Python实现)
决策树---ID3算法 决策树: 以天气数据库的训练数据为例. Outlook Temperature Humidity Windy PlayGolf? sunny 85 85 FALSE no ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- 02-21 决策树ID3算法
目录 决策树ID3算法 一.决策树ID3算法学习目标 二.决策树引入 三.决策树ID3算法详解 3.1 if-else和决策树 3.2 信息增益 四.决策树ID3算法流程 4.1 输入 4.2 输出 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树ID3算法[分类算法]
ID3分类算法的编码实现 <?php /* *决策树ID3算法(分类算法的实现) */ /* *求信息增益Grain(S1,S2) */ //-------------------------- ...
- Python四步实现决策树ID3算法,参考机器学习实战
一.编写计算历史数据的经验熵函数 from math import log def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCo ...
- 机器学习决策树ID3算法,手把手教你用Python实现
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第21篇文章,我们一起来看一个新的模型--决策树. 决策树的定义 决策树是我本人非常喜欢的机器学习模型,非常直观容易理解 ...
- 【Machine Learning in Action --3】决策树ID3算法
1.简单概念描述 决策树的类型有很多,有CART.ID3和C4.5等,其中CART是基于基尼不纯度(Gini)的,这里不做详解,而ID3和C4.5都是基于信息熵的,它们两个得到的结果都是一样的,本次定 ...
随机推荐
- Controller、Service、Dao进行Junit单元
原文链接:http://blog.csdn.net/u013041642/article/details/71430293 Spring对Controller.Service.Dao进行Junit单元 ...
- JSON.parseObject(String str)与JSONObject.parseObject(String str)的区别
一.首先来说说fastjson fastjson 是一个性能很好的 Java 语言实现的 JSON 解析器和生成器,来自阿里巴巴的工程师开发.其主要特点是: ① 快速:fastjson采用独创的算法, ...
- 【CSS】clear清除浮动
clear清除浮动1.作用: 规定元素的某一侧不允许存在浮动元素 2.值: 3.应用: 清除其他浮动元素对其产生的影响 <!DOCTYPE html> <html lang=&quo ...
- Java基础-数据类型应用案例展示
Java基础-数据类型应用案例展示 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.把long数据转换成字节数组,把字节数组数据转换成long. /* @author :yinz ...
- python---基础知识回顾(一)(引用计数,深浅拷贝,列表推导式,lambda表达式,命名空间,函数参数逆收集,内置函数,hasattr...)
一:列表和元组(引用计数了解,深浅拷贝了解) 序列:序列是一种数据结构,对其中的元素按顺序进行了编号(从0开始).典型的序列包括了列表,字符串,和元组 列表是可变的(可以进行修改),而元组和字符串是不 ...
- 原始套接字-TCP/IP下三层数据显示
#include <stdio.h> #include <errno.h> #include <unistd.h> #include <sys/socket. ...
- Spring RedisTemplate操作-List操作(4)
@Autowired @Resource(name="redisTemplate") private RedisTemplate<String, String> rt; ...
- koa1.x获取原始body内容
Node版本比较老,koa1.x配合koa-body-parser,默认koa-body-parser会把请求数据转成json对象, 然而有的时候需要获取原始的内容,不要转换,看波koa-body-p ...
- 自己动手开发Socks5代理服务器
一.Socks5协议简介 socks5是基于传输层的协议,客户端和服务器经过两次握手协商之后服务端为客户端建立一条到目标服务器的通道,在传输层转发TCP/UDP流量. 关于socks5协议规范,到处都 ...
- C++ socket 网络编程 简单聊天室
操作系统里的进程通讯方式有6种:(有名/匿名)管道.信号.消息队列.信号量.内存(最快).套接字(最常用),这里我们来介绍用socket来实现进程通讯. 1.简单实现一个单向发送与接收 这是套接字的工 ...