Scrapy持久化存储
基于终端指令的持久化存储
保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作;
执行输出指定格式进行存储:将爬取到的数据写入不同格式的文件中进行存储
scrapy crawl 爬虫名称 -o xxx.json
scrapy crawl 爬虫名称 -o xxx.xml
scrapy crawl 爬虫名称 -o xxx.csv
基于管道的持久化存储
scrapy框架中已经为我们专门集成好了高效、便捷的持久化操作功能,我们直接使用即可:
items.py : 数据结构模板文件,定义数据属性;
pipelines.py : 管道文件,接受item类型的数据,进行持久化操作;
持久化流程:
- 在爬虫文件中获取到数据后,将数据封装到 items对象中;
- 通过 yield 关键字将items对象提交给pipelines管道进行持久化操作;
- 在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码将item对象存储的数据进行持久化存储;
settings.py文件中开启管道:
ITEM_PIPELINES = {
'qiubaiPro.pipelines.QiubaiproPipelineByRedis': 300,
}
终端持久化存储示例:
将糗事百科首页中的段子和作者数据爬取下来,然后进行持久化存储
爬虫程序
# -*- coding: utf-8 -*-
import scrapy class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
all_data = []
# xpath返回的列表元素类型为Selector类型
for div in div_list:
# title = div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span[2]/h2/text()')[0].extract()
author = div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span[2]/h2/text()').extract_first()
content = div.xpath('./a[1]/div/span/text()').extract_first() dic = {
'author': author,
'content': content
} all_data.append(dic)
# 基于终端指令的持久化存储:可以通过终端指令的形式将parse方法的返回值中存储的数据进行本地磁盘的持久化存储
return all_data
settings
BOT_NAME = 'qiubaiPro'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
SPIDER_MODULES = ['qiubaiPro.spiders']
NEWSPIDER_MODULE = 'qiubaiPro.spiders'
ROBOTSTXT_OBEY = False
执行:
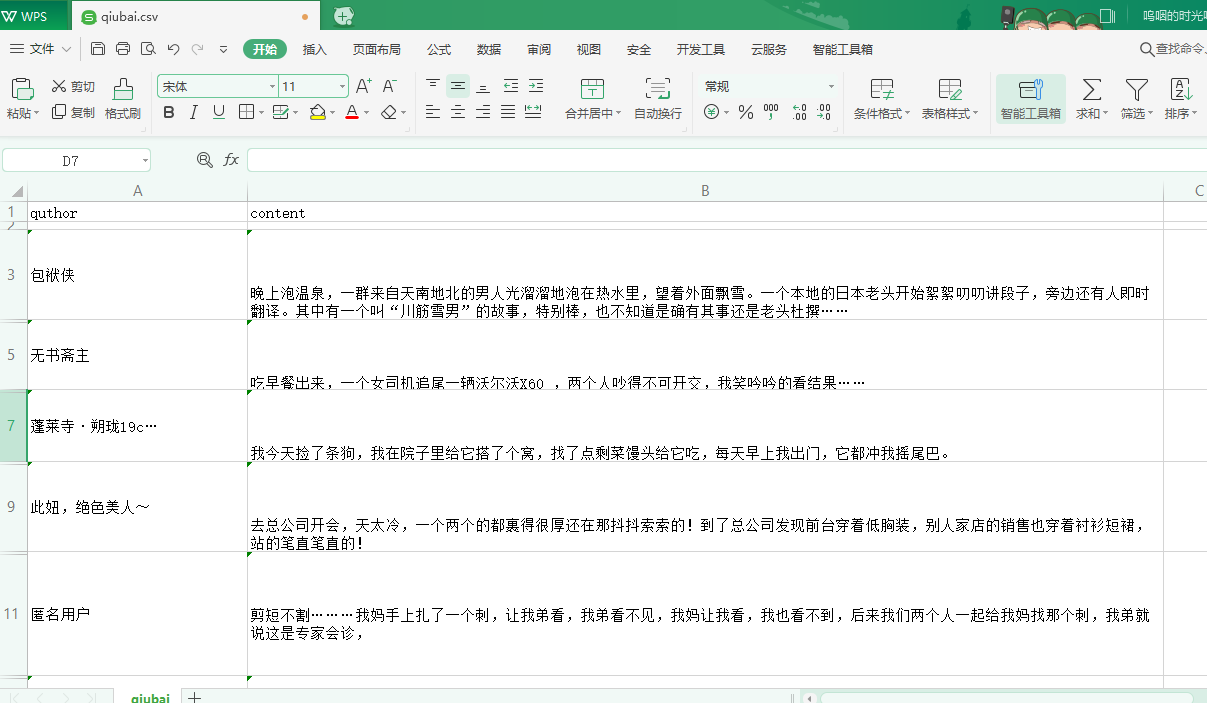
scrapy crawl qiubai -o qiubai.csv

执行完之后的结果:
管道持久化存储示例:
爬取Boss直聘网中Python爬虫岗位的职位名称,薪资,公司名称
爬虫程序
# -*- coding: utf-8 -*-
import scrapy
from bossPro.items import BossproItem class BossSpider(scrapy.Spider):
name = 'boss'
allowed_domains = ['www.xxx.com']
start_urls = ['https://www.zhipin.com/job_detail/?query=Python爬虫&scity=101010100&industry=&position='] def parse(self, response):
li_list = response.xpath('//div[@class="job-list"]/ul/li')
for li in li_list:
title = li.xpath('.//div[@class="info-primary"]/h3[@class="name"]/a/div/text()').extract_first()
salary = li.xpath('.//div[@class="info-primary"]/h3[@class="name"]/a/span/text()').extract_first()
company = li.xpath('.//div[@class="company-text"]/h3/a/text()').extract_first() # 实例化一个item类型的对象
item = BossproItem()
# 将解析到的数据存储到item对象中
item["title"] = title
item["salary"] = salary
item["company"] = company # 将item对象提交给管道进行持久化存储
yield item
items
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class BossproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
salary = scrapy.Field()
company = scrapy.Field()
pipelines
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # 管道文件:需要接收爬虫文件提交过来的数据,并对数据进行持久化存储.(IO操作)
class BossproPipeline(object):
fp = None
# 只会被执行一次(开始爬虫的时候执行一次)
def open_spider(self,spider):
print("开始爬虫")
self.fp = open('./job.txt','w',encoding='utf-8')
# 爬虫文件每提交一次,该方法就会被调用一次
def process_item(self, item, spider): #300表示为优先级,值越小优先级越高
self.fp.write(item['title'] + "\t" + item['salary'] + '\t' + item['company'] + '\n')
return item
# 结束爬虫时执行
def close_spider(self,spider):
self.fp.close()
print("爬虫结束") # 注意:默认情况下,管道机制并没有开启,需要手动在配置文件中进行开启 # 使用管道进行持久化的流程:
# 1.获取解析到的数据
# 2.将解析的数据存储到item对象(item类中进行相关属性的声明)
# 3.通过yield关键字将item提交到管道
# 4.管道文件中进行持久化存储代码的编写(process_item)
# 5.在配置文件中开启管道
settings
#开启管道
ITEM_PIPELINES = {
'secondblood.pipelines.SecondbloodPipeline': 300, #300表示为优先级,值越小优先级越高
}
执行:
scrapy crawl boss --nolog


基于MySQL的持久化存储
pipelines
import pymysql
class mysqlPipeline(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='', db='spider')
print(self.conn)
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
sql = 'insert into boss values("%s","%s","%s")'%(item['title'],item['salary'],item['company'])
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print (e)
self.conn.rollback() def close_spider(self,spider):
self.cursor.close()
self.conn.close()
settings
# 开启管道,自定义管道向不用的数据库存储数据
# 300是优先级,数字越小,优先级越高 ITEM_PIPELINES = {
'boss.pipelines.BossPipeline': 300,
'boss.pipelines.mysqlPipeLine': 301,
}
执行爬虫程序,并去数据库中查看数据

基于redis管道存储
pipelines
from redis import Redis
class RedisPipeline(object):
conn = None
def process_item(self,item,spider):
dic = {
"title":item["title"],
"salary":item["salary"],
"company":item["company"]
}
self.conn.lpush("jobInfo",json.dumps(dic))
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
print (self.conn)
settings
ITEM_PIPELINES = {
#'bossPro.pipelines.BossproPipeline': 300,
#'bossPro.pipelines.mysqlPipeline': 301,
'bossPro.pipelines.RedisPipeline': 302,
}
执行代码并且查看redis中的数据

redis已经存在数据了,因为编码问题所以不显示中文.
Scrapy持久化存储的更多相关文章
- Scrapy持久化存储-爬取数据转义
Scrapy持久化存储 爬虫爬取数据转义问题 使用这种格式,会自动帮我们转义 'insert into wen values(%s,%s)',(item['title'],item['content' ...
- scrapy之持久化存储
scrapy之持久化存储 scrapy持久化存储一般有三种,分别是基于终端指令保存到磁盘本地,存储到MySQL,以及存储到Redis. 基于终端指令的持久化存储 scrapy crawl xxoo - ...
- scrapy 爬虫框架之持久化存储
scrapy 持久化存储 一.主要过程: 以爬取校花网为例 : http://www.xiaohuar.com/hua/ 1. spider 回调函数 返回item 时 要用y ...
- 11.scrapy框架持久化存储
今日概要 基于终端指令的持久化存储 基于管道的持久化存储 今日详情 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的 ...
- scrapy框架持久化存储
基于终端指令的持久化存储 基于管道的持久化存储 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文 ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- 爬虫--使用scrapy爬取糗事百科并在txt文件中持久化存储
工程目录结构 spiders下的first源码 # -*- coding: utf- -*- import scrapy from firstBlood.items import Firstblood ...
- 11,scrapy框架持久化存储
今日总结 基于终端指令的持久化存储 基于管道的持久化存储 今日详情 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的 ...
- scrapy 框架持久化存储
1.基于终端的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表或字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. # 执行输出指定格式进行存储:将 ...
随机推荐
- 从外部导入django模块
import os import sys sys.path.append("D:\\pyweb\\sf"); # 项目位置(不是app) os.environ.setdefault ...
- HTTP的cookie
HTTP cookies,通常又称作"cookies",已经存在了很长时间,但是仍旧没有被予以充分的理解.首要的问题是存在了诸多误区,认为cookies是后门程序或病毒,或压根不知 ...
- orcl 中upper()和lower()和initcap()的用法
upper(字符串 | 列):输入的字符串变为大写返回: 将 bqh4表里的zym字段信息中含有字母的全部转成大写的方法: select * from bqh4 select upper(zym) f ...
- Spring Cloud 子项目介绍
Spring Cloud由以下子项目组成. Spring Cloud Config 配置中心——利用git来集中管理程序的配置. 项目地址:https://spring.io/projects/spr ...
- [IDEA_4] IDEA 从 GitHub 上 pull 项目到本地
0. 说明 通过参考的链接我们已经知道了怎么安装配置 Git .GitHub ,如何使用 IDEA 将本地项目上传到 GitHub. 现在是学习怎么通过 IDEA 将项目从 GitHub pull ...
- fedora安装视频播放器
添加RPMFusion仓库后才能安装VLC.Mplayer,其他库中没有 直接 sudo dnf install vlc sudo dnf install mplayer
- DevExpress06、Popup Menus、RadialMenu、XtraTabControl、SplitContainerControl、GroupControl
Popup Menus 弹出菜单 使用弹出菜单(popup menus),我们可以在 控件上 显示 上下文选项 或 命令. 弹出菜单是一个显示了特定项的窗体,用户可以选择这些项以执行 ...
- 网络唤醒(WOL)全解指南:原理篇
什么是网络唤醒 网络唤醒(Wake-on-LAN,WOL)是一种计算机局域网唤醒技术,使局域网内处于关机或休眠状态的计算机,将状态转换成引导(Boot Loader)或运行状态.无线唤醒(Wake-o ...
- p,np,npc,np难问题,确定图灵机与非确定图灵机
本文转自豆瓣_燃烧的影子 图灵机与可计算性 图灵(1912~1954)出生于英国伦敦,19岁进入剑桥皇家学院研究量子力学和数理逻辑.1935年,图灵写出了"论高斯误差函数"的论文, ...
- linux 删除指定日期之前的文件
两种方法: 1. 在一个目录中保留最近三个月的文件,三个月前的文件自动删除. find /email/v2_bak -mtime +92 -type f -name *.mail[12] -exec ...