python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
觉得有用的话,欢迎一起讨论相互学习~Follow Me
参考文献
python操作txt文件中数据教程[1]-使用python读写txt文件
python操作txt文件中数据教程[2]-python提取txt文件
- 原始txt文件

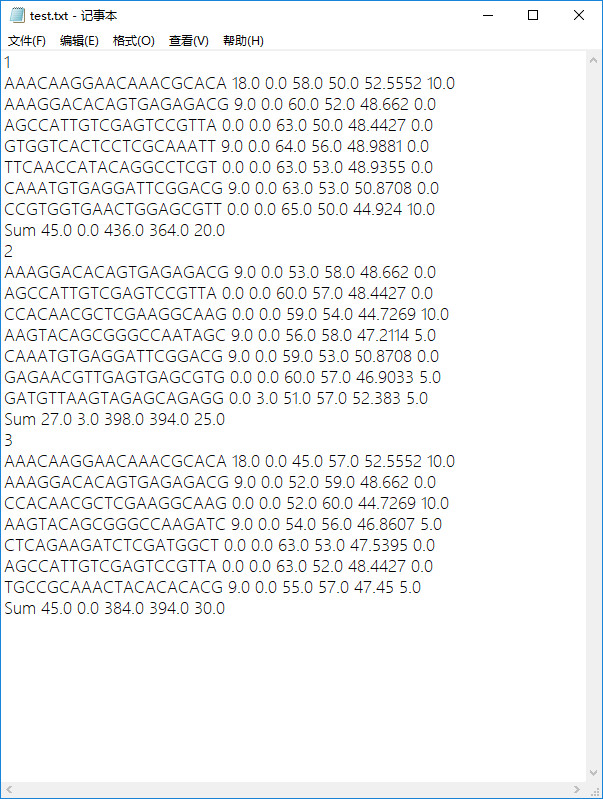
- 程序实现后结果

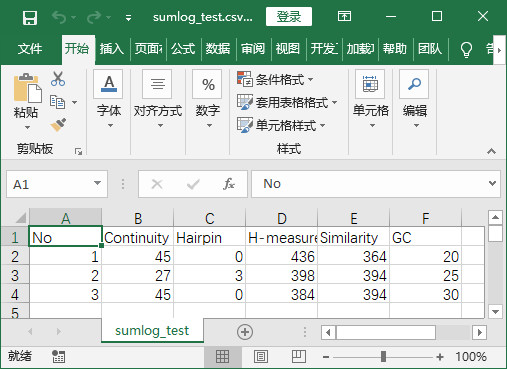
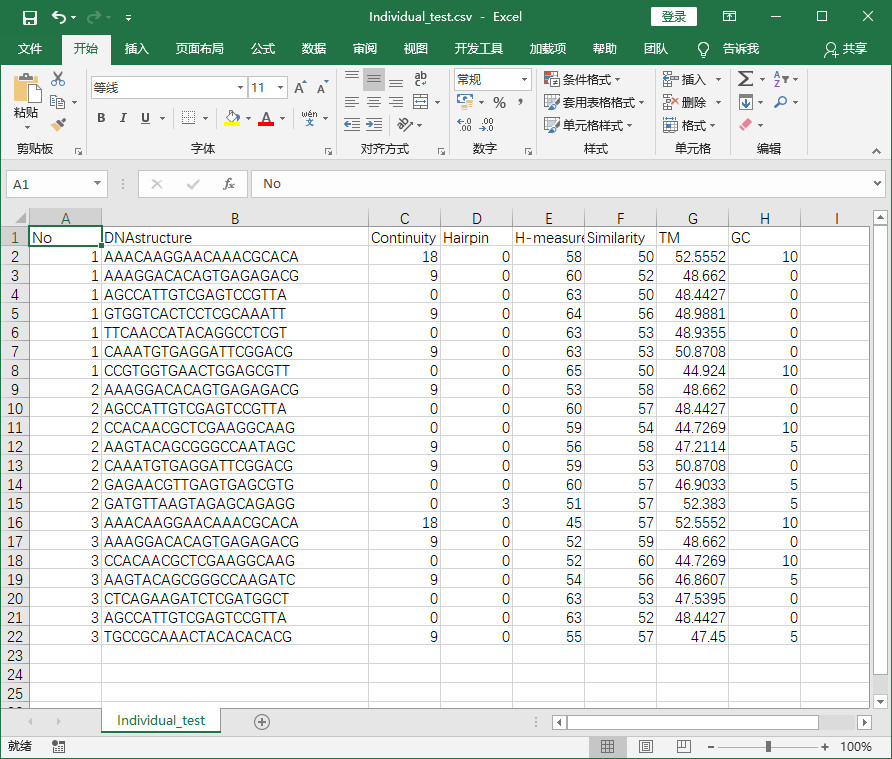
程序实现
import csv
import os
SUM_LOG_FILE = [] # sum_csv文件名
INDIVIDUAL_LOG_FILE = [] # individual_csv文件名
File_Name = [] # txt_文件名
DNA_Group = 7 # 表示每7条DNA组成一个组
Sum_log_file_header = ["No", "Continuity", "Hairpin", "H-measure", "Similarity", "GC"]
Individual_log_file_header = ["No", "DNAstructure", "Continuity", "Hairpin", "H-measure", "Similarity", "TM", "GC"]
def Read_Files(filename):
DNA_log = [] # 精英种群个体日志mod9=1-8
Sum_log = [] # 精英种群总体日志mod9=0
sum_evaindex = [[] for i in range(6)]
Individual_evaindex = [[] for i in range(8)]
with open(filename, 'r') as f:
i = 1
for line in f.readlines():
if i%9 == 0:
Sum_log.append(line)
else:
DNA_log.append(line)
i = i + 1
f.close()
Sum_no = 1
dna_log_no = 0
for Sum in Sum_log:
sum_eva_index = Sum.split("\n")[0].split(" ")[1:]
sum_evaindex[0].append(int(Sum_no))
sum_evaindex[1].append(float(sum_eva_index[0])) # Con
sum_evaindex[2].append(float(sum_eva_index[1])) # HP
sum_evaindex[3].append(float(sum_eva_index[2])) # Hm
sum_evaindex[4].append(float(sum_eva_index[3])) # Si
sum_evaindex[5].append(float(sum_eva_index[4])) # GC
Sum_no = Sum_no + 1
for dna_log in DNA_log:
# 获取序号值
if (dna_log_no + 1)%8 == 1:
for i in range(DNA_Group):
Individual_evaindex[0].append(int(dna_log.split("\n")[0]))
else:
# 获取各项指标
Individual_evaindex[1].append(dna_log.split("\n")[0].split(" ")[0]) # 所有DNA序列全部记载,使用原有的str字符串类型记载
Individual_evaindex[2].append(float(dna_log.split("\n")[0].split(" ")[1])) # DNA序列的连续值Con,注意要转换为浮点数类型
Individual_evaindex[3].append(float(dna_log.split("\n")[0].split(" ")[2])) # Hp茎区匹配
Individual_evaindex[4].append(float(dna_log.split("\n")[0].split(" ")[3])) # H-measure
Individual_evaindex[5].append(float(dna_log.split("\n")[0].split(" ")[4])) # Similarity
Individual_evaindex[6].append(float(dna_log.split("\n")[0].split(" ")[5])) # TM
Individual_evaindex[7].append(float(dna_log.split("\n")[0].split(" ")[6])) # GC
dna_log_no = dna_log_no + 1
return sum_evaindex, Individual_evaindex
# 将数据写入csv日志文件中
def Write_SumFiles(filename, sum_evaindex):
with open(filename, "w", newline='') as f:
writer = csv.writer(f)
writer.writerow(Sum_log_file_header) # 注意,此处使用writerow而不是使用writerows
for i in range(sum_evaindex[0][-1]):
writer.writerow(
[sum_evaindex[0][i], sum_evaindex[1][i], sum_evaindex[2][i], sum_evaindex[3][i], sum_evaindex[4][i],
sum_evaindex[5][i]])
f.close()
def Write_IndividualFiles(filename, sum_evaindex, Individual_evaindex):
with open(filename, "w", newline='') as f:
writer = csv.writer(f)
writer.writerow(Individual_log_file_header) # 注意,此处使用writerow而不是使用writerows
for i in range(sum_evaindex[0][-1]*DNA_Group):
writer.writerow(
[Individual_evaindex[0][i], Individual_evaindex[1][i], Individual_evaindex[2][i],
Individual_evaindex[3][i],
Individual_evaindex[4][i], Individual_evaindex[5][i], Individual_evaindex[6][i],
Individual_evaindex[7][i]])
f.close()
def file_name(file_dir):
for files in os.listdir(file_dir):
if os.path.splitext(files)[1] == '.txt':
File_Name.append(files)
SUM_LOG_FILE.append("./test/sumlog_" + os.path.splitext(files)[0] + ".csv")
INDIVIDUAL_LOG_FILE.append("./test/Individual_" + os.path.splitext(files)[0] + ".csv")
# 获取当前目录下所有txt文件名
file_name(".")
for i, j, k in zip(File_Name, SUM_LOG_FILE, INDIVIDUAL_LOG_FILE):
print(i)
print(j)
print(k)
Sum_Evaindex, Individual_Evaindex = Read_Files(i)
Write_SumFiles(filename=j, sum_evaindex=Sum_Evaindex)
Write_IndividualFiles(filename=k, sum_evaindex=Sum_Evaindex, Individual_evaindex=Individual_Evaindex)
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件的更多相关文章
- python操作txt文件中数据教程[4]-python去掉txt文件行尾换行
python操作txt文件中数据教程[4]-python去掉txt文件行尾换行 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文章 python操作txt文件中数据教程[1]-使用pyt ...
- python操作txt文件中数据教程[2]-python提取txt文件
python操作txt文件中数据教程[2]-python提取txt文件中的行列元素 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果-将txt中元素提取并保存在c ...
- Jar中的Java程序如何读取Jar包中的资源文件
Jar中的Java程序如何读取Jar包中的资源文件 比如项目的组织结构如下(以idea中的项目为例): |-ProjectName |-.idea/ //这个目录是idea中项目的属性文件夹 |-s ...
- Python操作MySQL数据库(步骤教程)
我们经常需要将大量数据保存起来以备后续使用,数据库是一个很好的解决方案.在众多数据库中,MySQL数据库算是入门比较简单.语法比较简单,同时也比较实用的一个.在这篇博客中,将以MySQL数据库为例,介 ...
- 将Excel文件转为csv文件的python脚本
#!/usr/bin/env python __author__ = "lrtao2010" ''' Excel文件转csv文件脚本 需要将该脚本直接放到要转换的Excel文件同级 ...
- javaSE中的输入输出流---一个读取流,相应多个输出流。并且生成的碎片文件都有有序的编号
<span style="font-size:18px;">package com.io.other.split; import java.io.File; impor ...
- Java 在PPT中创建SmartArt图形、读取SmartArt图形中的文本
一.概述及环境准备 SmartArt 图形通过将文字.图形从多种不同布局.组合来表现内容和观点的逻辑关系,能够快速.有效地传达设计者的意图和信息.这种图文表达的视觉表示形式常用于PPT,Word,Ex ...
- [Asp.net]通过uploadify将文件上传到B服务器的共享文件夹中
写在前面 客户有这样的一个需求,针对项目中文档共享的模块,客户提出如果用户上传特别的大,或者时间久了硬盘空间就会吃满,能不能将这些文件上传到其他的服务器?然后就稍微研究了下这方面的东西,上传到网络中的 ...
- 安卓中級教程(9):pathbutton中的animation.java研究(2)
src/geniuz/myPathbutton/composerLayout.java package geniuz.myPathbutton; import com.nineoldandroids. ...
随机推荐
- Arcgis安装要素
1. ArcGIS安装过程中需将用户名改为计算机名,该计算机名称时需要新建对话框. 2. ArcGIS Server安装过程中要设置ArcGISWebServices用户的读写权限,即设置ASP.NE ...
- 【原创】梵高油画用深度卷积神经网络迭代10万次是什么效果? A neural style of convolutional neural networks
作为一个脱离了低级趣味的码农,春节假期闲来无事,决定做一些有意思的事情打发时间,碰巧看到这篇论文: A neural style of convolutional neural networks,译作 ...
- symfon2 配置文件使用 + HttpRequest使用 + Global多语言解决方案
1. 在 app/conig中建立一个自命名的文件: abc.yml 2. 在 app/config/config.yml中导入abc.yml 文件头部: imports:- { resource: ...
- SDN竞赛思考总结
SDN竞赛思考总结 2016年下半年张老师开始着手组建SDN小组,从未接触过任何网络知识的我也有幸成为小组一员.从最开始刷Openflow交换机,Get了刷交换机的新技能;到P4FPGA的无疾而终,表 ...
- VS社区版 使用 OpenCover 获取测试代码覆盖率
注:暂不支持VS2017 Visual Studio 2015 社区版没有集成代码覆盖率的功能,所以想在VS社区版中获取单元测试的代码覆盖率等数据,需要使用到插件 OpenCover. 下载 Open ...
- 团队作业5——英语学习/词典App行业Top5
来自权威研究机构易观智库的最新数据表明,国内几家主流词典类App市场的份额占比差异化分布进一步加剧. 对于156万安卓移动端活跃数字消费者的移动互联网行为监测结果显示,截至2014年8月底,有道词典A ...
- 使用不同的namespace让不同的kafka/Storm连接同一个zookeeper
背景介绍: 需要部署2个kafka独立环境,但是只有一个zookeeper集群. 需要部署2个独立的storm环境,但是只有一个zookeeper集群. ----------------------- ...
- C#简述(三)
详细请参考:http://www.runoob.com/csharp/csharp-string.html 1.C# 字符串(String) 在 C# 中,可以使用字符数组来表示字符串,但是,更常见的 ...
- JS基础(四)运算符
一.比较运算符 1.== : 判断两边值是否相等 2.>= : 判断左边的值是否大于或等于右边的值 3.<= : 判断左边边的值是否小于或等于右边的值 4.> : 判断左边的值是 ...
- Android DatePickerDialog和TimePickerDialog显示样式
可以用DatePickerDialog显示选取日期的对话框.可以设置显示的样式 1.通过构造方法设置显示样式. 可以通过DatePickerDialog(Context context, int th ...