什么情况下ArrayList增删 比LinkedList 更快
public static void main(String[] args){
final int MAX_VAL = 10000;
List<Integer> linkedList = new LinkedList<Integer>();
List<Integer> arrayList = new ArrayList<Integer>();
for(int i = 0; i < MAX_VAL; i++) {
linkedList.add(i);
arrayList.add(i);
}
long time = System.nanoTime();
for(int i = 0; i < MAX_VAL; i++) {
linkedList.add(MAX_VAL/2, i);
}
System.out.println("LL time: " + (System.nanoTime() - time));
time = System.nanoTime();
for(int i = 0; i < MAX_VAL; i++) {
arrayList.add(MAX_VAL/2, i);
}
System.out.println("AL time: " + (System.nanoTime() - time));
}
从中间插入结果:

怎么会这样, 不应该是LinkedList更快吗? ArrayList底层是数组, 添加数据需要移动后面的数据, 而LinkedList使用的是链表, 直接移动指针就行, 按理说应该是LinkedList更快.
再来看
从尾插入
public static void main(String[] args){
final int MAX_VAL = 10000;
List<Integer> linkedList = new LinkedList<Integer>();
List<Integer> arrayList = new ArrayList<Integer>();
for(int i = 0; i < MAX_VAL; i++) {
linkedList.add(i);
arrayList.add(i);
}
long time = System.nanoTime();
for(int i = 0; i < MAX_VAL; i++) {
linkedList.add(i);
}
System.out.println("LL time: " + (System.nanoTime() - time));
time = System.nanoTime();
for(int i = 0; i < MAX_VAL; i++) {
arrayList.add(i);
}
System.out.println("AL time: " + (System.nanoTime() - time));
}

从头开始插入
public static void main(String[] args){
final int MAX_VAL = 10000;
List<Integer> linkedList = new LinkedList<Integer>();
List<Integer> arrayList = new ArrayList<Integer>();
for(int i = 0; i < MAX_VAL; i++) {
linkedList.add(i);
arrayList.add(i);
}
long time = System.nanoTime();
for(int i = 0; i < MAX_VAL; i++) {
linkedList.add(0,i);
}
System.out.println("LL time: " + (System.nanoTime() - time));
time = System.nanoTime();
for(int i = 0; i < MAX_VAL; i++) {
arrayList.add(0,i);
}
System.out.println("AL time: " + (System.nanoTime() - time));
}
结果

然后从三分之一的位置开始插入
结果
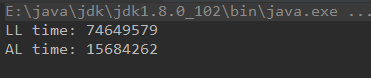
从三分之二的位置插入
结果

源码部分
LinkedList源码
// 在index前添加节点,且节点的值为element
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
} // 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前向后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
} // 将节点(节点数据是e)添加到entry节点之前。
private Entry<E> addBefore(E e, Entry<E> entry) {
// 新建节点newEntry,将newEntry插入到节点e之前;并且设置newEntry的数据是e
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
// 插入newEntry到链表中
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
从中,我们可以看出:通过add(int index, E element)向LinkedList插入元素时。先是在双向链表中找到要插入节点的位置index;找到之后,再插入一个新节点。
双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
接着,我们看看ArrayList.java中向指定位置插入元素的代码。如下:
// 将e添加到ArrayList的指定位置
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size); ensureCapacity(size+1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
ensureCapacity(size+1) 的作用是“确认ArrayList的容量,若容量不够,则增加容量。”
真正耗时的操作是 System.arraycopy(elementData, index, elementData, index + 1, size - index);
实际上,我们只需要了解: System.arraycopy(elementData, index, elementData, index + 1, size - index); 会移动index之后所有元素即可。这就意味着,ArrayList的add(int index, E element)函数,会引起index之后所有元素的改变!
结论:
现在大概知道了,插入位置的选取对LinkedList有很大的影响,一直往数据中间部分插入删除的时候,ArrayList比LinkedList更快
原因大概就是当数据量大的时候,system.arraycopy的效率要比每次插入LinkedList都需要从端查找index和分配节点node来的更快。
总之,对于99%或更多的现实情况,ArrayList是更好的选择,并且利用LinkedList的狭隘优势需要非常小心。
什么情况下ArrayList增删 比LinkedList 更快的更多相关文章
- java.util.ArrayList,java.util.LinkedList,java.util.Vector的区别,使用场合.
下图是Collection的类继承图 从图中可以看出:Vector.ArrayList.LinkedList这三者都实现了List 接口.所有使用方式也很相似,主要区别在于实现方式的不同,所以对不同的 ...
- java里的数组和list分别在什么情况下使用?
数组长度固定,List未限定长度,且支持的功能更多,最常用的ArrayList底层实际上也是使用数组实现. 不需要复杂功能和确定长度的情况下,使用数组效率更高,通常情况建议使用List.
- 什么情况用ArrayList or LinkedList呢?
ArrayList 和 LinkedList 是 Java 集合框架中用来存储对象引用列表的两个类.ArrayList 和 LinkedList 都实现 List 接口.先对List做一个简单的了解: ...
- 使用QFileInfo类获取文件信息(在NTFS文件系统上,出于性能考虑,文件的所有权和权限检查在默认情况下是被禁用的,通过qt_ntfs_permission_lookup开启和操作。absolutePath()必须查询文件系统。而path()函数,可以直接作用于文件名本身,所以,path() 函数的运行会更快)
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Amnes1a/article/details/65444966QFileInfo类为我们提供了系统无 ...
- OC JS交互(通常情况下,如果网页写得正规的话,是可以正常交互的,之前就遇到后台写h5始终拿不到事件,元素也拿不到,更别说交互了,真是奇了怪了)
自动填充表单 @"document.getElementById('loginid').value = '这里填入你的用户名';document.getElementById('userpa ...
- Java高并发情况下的锁机制优化
本文主要讲并行优化的几种方式, 其结构如下: 锁优化 减少锁的持有时间 例如避免给整个方法加锁 1 public synchronized void syncMethod(){ 2 othercode ...
- 如何彻底理解Java抽象类 为什么要用抽象类 什么情况下用抽象类
如何彻底理解Java抽象类 为什么要用抽象类 什么情况下用抽象类 呐,到底什么是抽象类,有时明明一个普通类就可以解决了,为啥非得整个抽象类,装逼吗 我曾带着这样的疑惑,查了很多资料,看了很多源码,写了 ...
- Redis面试题记录--缓存双写情况下导致数据不一致问题
转载自:https://blog.csdn.net/lzhcoder/article/details/79469123 https://blog.csdn.net/u013374645/article ...
- 用SignalR 2.0开发客服系统[系列4:负载均衡的情况下使用SignalR]
前言 交流群:195866844 目录: 用SignalR 2.0开发客服系统[系列1:实现群发通讯] 用SignalR 2.0开发客服系统[系列2:实现聊天室] 用SignalR 2.0开发客服系统 ...
随机推荐
- 虚拟机CentOs的安装及大数据的环境搭建
大数据问题汇总 1.安装问题 1.安装步骤,详见文档<centos虚拟机安装指南> 2.vi编辑器使用问题,详见文档<linux常用命令.pd ...
- i2c设备驱动注册
Linux I2C设备驱动编写(二) 原创 2014年03月16日 23:26:50 在(一)中简述了Linux I2C子系统的三个主要成员i2c_adapter.i2c_driver.i2c ...
- AngularJS监听数组变化
我们在使用angualr的监听时候,业务的需要我们会去监听一个数组的某一个值得变化,再写逻辑代码.然而我们在使用$scope.$watch("",function(){ })时候会 ...
- Java学习第1天:序言,基础及配置tomcat
所谓是福不是祸,是祸躲不过,到底还是回到java的阵地上来.既然它这么热,那就学学它,现在这件事已经提上议事日程,也已经开始. 今天做的事: 泛泛的翻了几本书,敲了一些练习代码,比如字符串操作,接口等 ...
- 通过pip安装套件
pip3 install requests pip3 install BeautifulSoup4 还需要使用jupyter: pip3 install jupyter 打开jupyterbook ...
- 3D打印切片软件介绍
熟悉3D打印的流程的人都知道,在建立了3D模型以后要就进行切片,但是什么是切片呢?切片实际上就是讲3D模型转化为3D打印机本身可以执行的代码,G代码,M代码. 3D打印流程 今天我们简要的介绍3款切片 ...
- 三.int , bool , str
03.万恶之源-基本数据类型(int, bool, str) 本节主要内容: 1. python基本数据类型回顾 2. int----数字类型3. bool---布尔类型4. str--- 字符串类 ...
- JSON 全解
和js对象的区别 json只是一种数据格式,不支持undefined,字符串必须使用双引号,需要对/进行转义/. js属性名可不加"" json属性名必须加"" ...
- 7.与python交互
与python交互 在熟练使用sql语句的基础上,开始使用python语言提供的模块与mysql进行交互 这是我们在工作中大事要做的事 先学会sql是基础,一定要熟练编写sql语句 安装引入模块 安装 ...
- Scott-Knott test 配置与使用
安装最新版本的 R R安装镜像 Download R 3.3.0 for Windows (62 megabytes, 32/64 bit) 理由 Scott-Knott 包由 R 3.2.5 编译的 ...