搭建ELK集群

环境准备
基础环境介绍
| 操作系统 | 部署应用 | 应用版本号 | IP地址 | 主机名 |
|---|---|---|---|---|
| CentOS 7.4 | Elasticsearch/Logstash | 6.4.3 | 192.168.1.1 | elk1 |
| CentOS 7.4 | Elasticsearch/Logstash/Redis | 6.4.3 | 192.168.1.2 | elk2 |
| CentOS 7.4 | Elasticsearch/Kibana | 6.4.3 | 192.168.1.3 | elk3 |
基础环境配置
安装基本软件包以及配置hosts
yum -y install vim net-tools epel-release wget
cat /etc/hosts
192.168.1.1 elk1
192.168.1.2 elk2
192.168.1.3 elk3
修改文件描述符以及内核参数
vim /etc/sysctl.conf
vm.max_map_count = 655360
sysctl -p /etc/sysctl.conf
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
不需要重启,退出重连即可显示最新配置。使用ulimit -n查看。
安装及配置Java环境
yum -y install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64
vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
export JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
创建应用所需用户
user add elk
关闭防火墙
systemctl stop firewalld.service
下载所需应用安装包
Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.3.tar.gz
Logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.3.tar.gz
Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.3-linux-x86_64.tar.gz
应用部署
部署elasticsearch服务
tar xf elasticsearch-6.4.3.tar.gz -C /usr/local/
chown -R elk:elk /usr/local/elasticsearch-6.4.3/
mkdir /data ; chown -R elk:elk /data
vim /usr/local/elasticsearch-6.4.3/config/elasticsearch.yml
cluster.name: elk_cluster
node.name: elk1
node.attr.rack: r1
path.data: /data/
path.logs: /usr/local/elasticsearch-6.4.3/logs
node.master: true
node.data: true
network.host: elk1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elk1","elk2","elk3"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.commit_timeout: 100s
discovery.zen.publish_timeout: 100s
discovery.zen.ping_timeout: 100s
discovery.zen.fd.ping_timeout: 100s
discovery.zen.fd.ping_interval: 10s
discovery.zen.fd.ping_retries: 10
action.destructive_requires_name: true
http.cors.allow-origin: "*"
http.cors.enabled: true
以下是Elasticsearch配置项内容详解。
cluster.name: elasticsearch
配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name: "Franz Kafka"
节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。
node.master: true
指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
node.data: true
指定该节点是否存储索引数据,默认为true。
index.number_of_shards: 5
设置默认索引分片个数,默认为5片。
index.number_of_replicas: 1
设置默认索引副本个数,默认为1个副本。
path.conf: /path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
path.data: /path/to/data
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:
path.data: /path/to/data1,/path/to/data2
path.work: /path/to/work
设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.logs: /path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: /path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.mlockall: true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令。
network.bind_host: 192.168.0.1
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host: 192.168.0.1
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.host: 192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
transport.tcp.port: 9300
设置节点间交互的tcp端口,默认是9300。
transport.tcp.compress: true
设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.port: 9200
设置对外服务的http端口,默认为9200。
http.max_content_length: 100mb
设置内容的最大容量,默认100mb
http.enabled: false
是否使用http协议对外提供服务,默认为true,开启。
gateway.type: local
gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。
gateway.recover_after_nodes: 1
设置集群中N个节点启动时进行数据恢复,默认为1。
gateway.recover_after_time: 5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.expected_nodes: 2
设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化数据恢复时,并发恢复线程的个数,默认为4。
cluster.routing.allocation.node_concurrent_recoveries: 2
添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
indices.recovery.max_size_per_sec: 0
设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
indices.recovery.concurrent_streams: 5
设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.ping.timeout: 3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.multicast.enabled: false
设置是否打开多播发现节点,默认是true。
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
su elk
/usr/local/elasticsearch-6.4.3/bin/elasticsearch
以上方式启动不会将进程运行在后台,适用于进程调试使用。
nohup /usr/local/elasticsearch-6.4.3/bin/elasticsearch &
将进程放置后台运行。
ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 100 164.52.7.154:25 *:*
LISTEN 0 128 *:2525 *:*
LISTEN 0 128 *:52580 *:*
LISTEN 0 128 ::ffff:192.168.1.1:9300 :::*
LISTEN 0 128 :::52580 :::*
curl -X GET "192.168.1.1:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1542005103 01:45:03 elk_cluster green 3 3 0 0 0 0 0 0 - 100.0%

查看状态正常。
配置Redis服务
yum -y install redis
vim /etc/redis.conf
bind elk2
maxmemory 1gb
protected-mode yes
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes
supervised no
pidfile /var/run/redis_6379.pid
loglevel notice
logfile /var/log/redis/redis.log
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /var/lib/redis
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 192.168.1.2:6379 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 *:52580 *:*
LISTEN 0 128 ::ffff:192.168.1.2:9200 :::*
LISTEN 0 128 ::ffff:192.168.1.2:9300 :::*
LISTEN 0 100 ::1:25 :::*
LISTEN 0 128 :::52580 :::*
查看Redis服务已经启动,后续我们可以配置Logstash使用Redis。
配置Logstash服务
tar xf logstash-6.4.3.tar.gz -C /usr/local/
chown -R elk:elk /usr/local/logstash-6.4.3/
vim /usr/local/logstash-6.4.3/config/logstash.yml
log --> Redis
input {
file {
path => "/var/log/messages"
type => "syslog"
start_position => "beginning"
}
}
output {
redis {
data_type => "channel"
key => "logstash-*"
host => "192.168.1.2"
port => 6379
}
}
Redis --> Elasticsearch
input {
redis {
data_type => "channel"
key => "logstash-*"
host => "192.168.1.2"
port => 6379
}
}
output {
elasticsearch {
hosts => "elk1:9200"
index => "logstash-%{type}-%{+YYYY.MM.dd}"
}
}
vim /usr/local/logstash-6.4.3/config/logstash.yml
node.name: elk1
path.data: /usr/local/logstash-6.4.3/data
http.host: "elk1"
path.logs: /usr/local/logstash-6.4.3/logs
配置Kibana服务
tar xf kibana-6.4.3-linux-x86_64.tar.gz -C /usr/local/
chown -R elk:elk /usr/local/kibana-6.4.3-linux-x86_64/
touch /var/run/kibana.pid
chown -R /var/run/kibana.pid
su elk
nohup /usr/local/kibana-6.4.3-linux-x86_64/bin/kibana &
ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 192.168.1.3:5601 *:*
LISTEN 0 128 *:52580 *:*
LISTEN 0 128 ::ffff:192.168.1.3:9200 :::*
LISTEN 0 128 ::ffff:192.168.1.3:9300 :::*
LISTEN 0 100 ::1:25 :::*
LISTEN 0 128 :::52580 :::*
Kibana已经部署并启动成功。
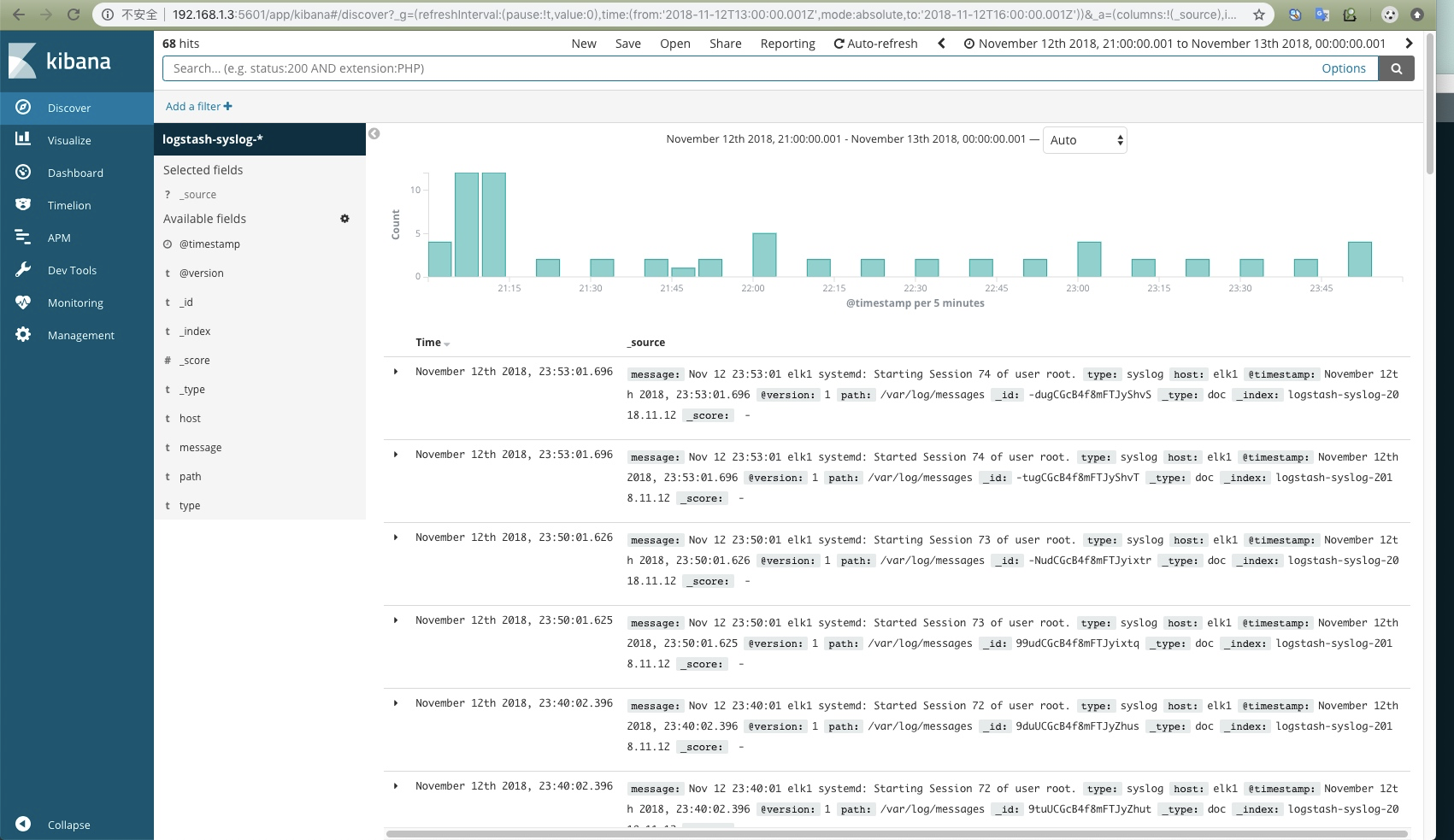
可以展示Elasticsearch中的数据。
搭建ELK集群的更多相关文章
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- 搭建ELK 集群 rpm安装
上次是使用docker搭建的ELK,三个软件都跑在一台机器的一个docker中,这个就当是测试环境吧. 下面开始搭建正式环境下的ELK集群. 三台服务器 A:logstash B:Elasticsea ...
- Docker 搭建 ELK 集群步骤
前言 本篇文章主要介绍在两台机器上使用 Docker 搭建 ELK. 正文 环境 CentOS 7.7 系统 Docker version 19.03.8 docker-compose version ...
- 搭建elk集群 disabled in libcurl elasticsearch-6.2.2 更新license 版本
0.logstash的部分配置 output { stdout {codec => rubydebug} elasticsearch { hosts => ["172.31.25 ...
- 【杂记】docker搭建ELK 集群6.4.0版本 + elasticsearch-head IK分词器与拼音分词器整合
大佬博客地址:https://blog.csdn.net/supermao1013/article/category/8269552 docker elasticsearch 集群启动命令 docke ...
- 搭建Elk集群搭建 ES-filebeat-logstrash-kibana
一 .基础环境 软件 版本 作用 Linux/Win Server2012 CentOs/Win Server2012 服务器环境 JDK 1.8.0_151 运行环境依赖 Elasticsearch ...
- ELK集群搭建
基于5台虚拟机,搭建ELK集群. 方案: 1. ELK是日志分析平台,而不是一款软件,是一整套解决方案,是三个软件产品的首字母缩写,ELK分别代表: Elasticsearch:负责日志检索和储存 L ...
- elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理)
一.集群规划 搭建一个集群我们需要考虑如下几个问题: 1. 我们需要多大规模的集群? 2. 集群中的节点角色如何分配? 3. 如何避免脑裂问题? 4. 索引应该设置多少个分片? 5. 分片应该设置几个 ...
- Kibana安装(图文详解)(多节点的ELK集群安装在一个节点就好)
对于Kibana ,我们知道,是Elasticsearch/Logstash/Kibana的必不可少成员. 前提: Elasticsearch-2.4.3的下载(图文详解) Elasticsearch ...
随机推荐
- JDK 规范目录
JDK 规范目录 1.1 Java 异常处理 2.1 JDK 之 NIO 2 WatchService.WatchKey(监控文件变化) https://mp.weixin.qq.com/s/NIn2 ...
- python中装饰器使用
装饰器是对已有的模块进行装饰(添加新功能)的函数. 现有一段代码: import time def func1(): time.sleep(3) print("in the func1&qu ...
- DNSlog实现Mysql注入
step1: 通过DNSlog盲注需要用到load_file()函数.show variables like '%secure%' 查看load_file()可以读取的磁盘. 1.当secure_fi ...
- android Run模式也会出现"Waiting for debugger"的解决方法
android Run模式也会出现"Waiting for debugger"的解决方法 出现“waiting for debugger”窗口是在debug模式下运行出现的.但是, ...
- windows + php7.1 + redis3.1.4
首先确定PHP版本(MSVC14 x64 NTS) 下载redis扩展 拷贝php ext目录,修改php.ini配置,添加 extension=php_redis.dll 重启apache,确认re ...
- Nodejs学习笔记:基础
本文章主要记录Nodejs基础知识点 安装 首先从Node.js官网下载安装包,并添加到环境变量.然后打开命令行,输入 node --version ,可查看版本信息 npm是Node.js的包管理工 ...
- js网页上画图
保存 1.d3.js (http://www.d3.org/)使用svg技术,展示大数据量,动态效果很好,但是API暴露的不好,得靠自己摸索. 2.http://raphaeljs.com/refe ...
- 团队-Python 爬取豆瓣电影top250-成员简介及分工
姓名:周鑫 班级:软件6班 团队名称:咣咣踹电脑 擅长:Python,java 分工:编写数据库
- 2018.11.01 NOIP训练 梭哈(模拟)
传送门 这题貌似不考智商啊. 直接按题意写就可以了. 事实上把牌从小到大排序之后写起来很舒服的. 然后就是有些地方可以人脑减代码量和判断次数. (提示:满堂红和某几种同类型的牌的大小判断) 然后注意A ...
- express框架搭建服务端
1.管理员权限全局安装express npm i -g express-generator@4 2.创建express项目 express -e projectName 3.进入项目并安装 cd pr ...