【MySQL】覆盖索引和回表
- 先来了解一下两大类索引
- 聚簇索引(也称聚集索引,主键索引等)
- 普通索引(也成非聚簇索引,二级索引等)
- 聚簇索引
- 如果表设置了主键,则主键就是聚簇索引
- 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。
由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
- 普通索引
普通索引也叫二级索引,除聚簇索引外的索引,即非聚簇索引。
InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
请看如下示例:
- 建表
CREATE TABLE IF NOT EXISTS `user`(
-> `id` INT UNSIGNED AUTO_INCREMENT,
-> `name` VARCHAR(),
-> `age` TINYINT(),
-> PRIMARY KEY (id),
-> INDEX idx_age (age)
-> )ENGINE=innodb charset=utf8mb4;
# id 字段是聚簇索引,age 字段是普通索引(二级索引)
- 随便加几个数据
insert into user(name,age) values('张三',);
insert into user(name,age) values('李四',);
insert into user(name,age) values('王五',);
insert into user(name,age) values('刘八',);
mysql> select * from user;
+----+------+-----+
| id | name | age |
+----+------+-----+
| | 张三 | |
| | 李四 | |
| | 王五 | |
| | 刘八 | |
+----+------+-----+
rows in set (0.06 sec)
- 索引存储结构
id 是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据

age 是普通索引(二级索引),非聚簇索引,其叶子节点存储的是聚簇索引的的值
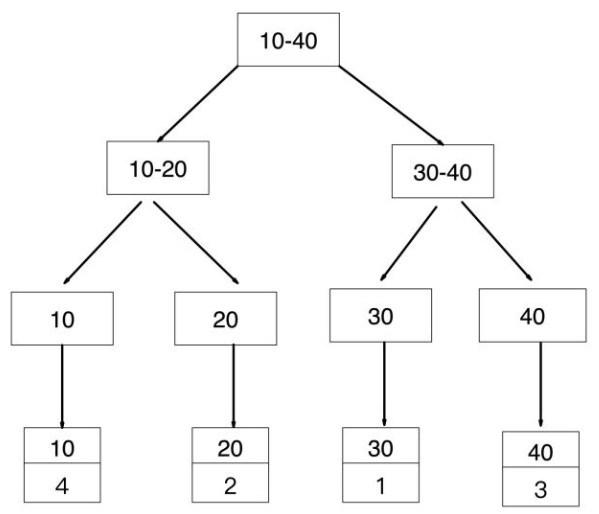
如果查询条件为主键(聚簇索引),则只需扫描一次B+树即可通过聚簇索引定位到要查找的行记录数据。
如:select * from user where id = ;
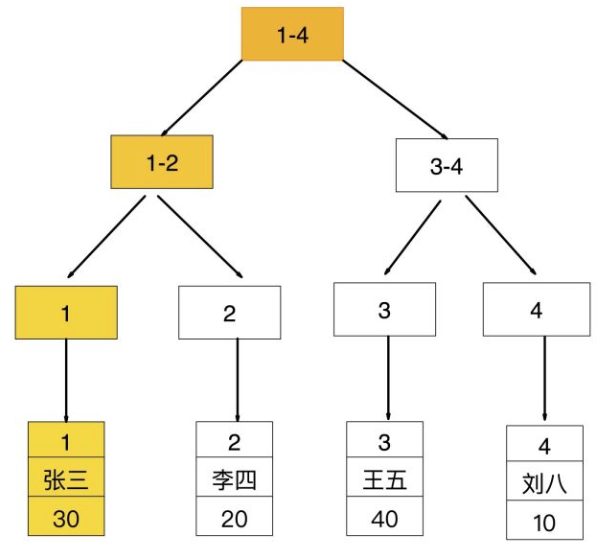
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。
如:select * from user where age = ;
1》先通过普通索引【age=30】定位到主键值 【id=1】
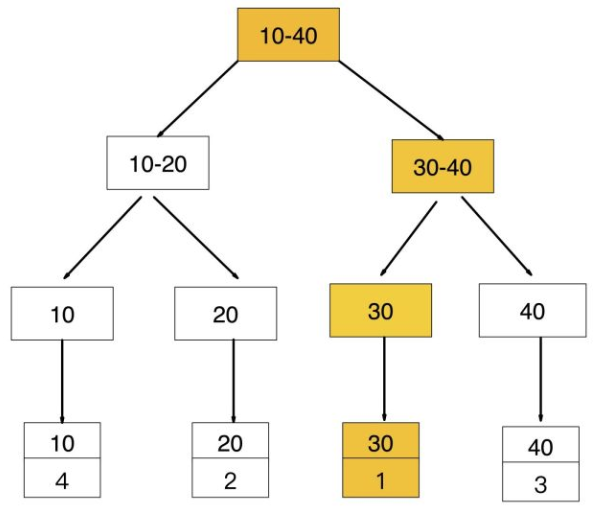
2》在通过聚集索引【id=1】定位到行记录数据
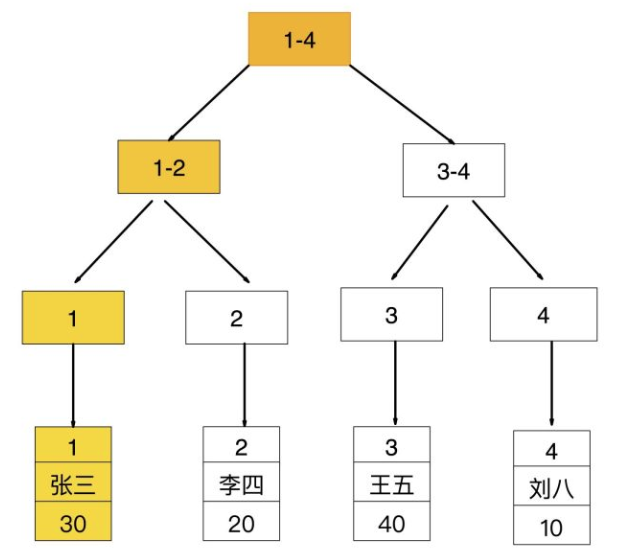
- 回表查询
先通过普通索引的值定位到聚簇索引值,在通过聚簇索引的值定位到行记录数据,要通过扫描两次索引B+树,它的性能较扫描一次较低
- 索引覆盖
只需在一颗索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
例如:select id,age from user where age = ;
- 如何实现覆盖索引
常见的方法是:将被查询的字段,建立到联合索引里去(若查询有where条件,同时where条件字段也必须为索引字段)。
1》如实现:select id,age from user where age = 10;
explain分析:因为age是普通索引,使用到了age索引,通过一次扫描B+树即可查询到相应的结果,这样就实现了覆盖索引
此时的Extra列的【Using Index】表示进行了聚簇索引
mysql> explain select id,age from user where age = ;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
| | SIMPLE | user | NULL | ref | idx_age | idx_age | | const | | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
row in set (0.07 sec)
2》如实现:select id,age,name from user where age = 10;
explain分析:age是普通索引,但name列不在索引树上,所以通过age索引在查询到id和age的值后,需要进行回表再查询name的值。
此时的Extra列的NULL表示进行了回表查询
mysql> explain select id,age,name from user where age = ;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| | SIMPLE | user | NULL | ref | idx_age | idx_age | | const | | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
row in set (0.05 sec)
explain 使用方式如下:
EXPLAIN +SQL语句
如:EXPLAIN SELECT * FROM t1
- 为了实现索引覆盖,需要建组合索引idx_age_name(age,name)
mysql> drop index idx_age on user;
mysql> create index idx_age_name on user(`age`,`name`);
我们再次EXPLAIN分析一次:
mysql> explain select id,age,name from user where age = ;
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------------+
| | SIMPLE | user | NULL | ref | idx_age_name | idx_age_name | | const | | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------------+
row in set (0.05 sec) #可见Extra的值为【Using Index】,表示使用的覆盖索引
哪些场景适合使用索引覆盖来优化SQL:
- 全表count查询优化
mysql> explain select count(age) from user;
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| | SIMPLE | user | NULL | index | NULL | idx_age_name | | NULL | | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
row in set (0.06 sec)
- 分页查询
mysql> explain select id,age,name from user order by age limit ,;
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| | SIMPLE | user | NULL | index | NULL | idx_age_name | | NULL | | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
row in set (0.06 sec)
【MySQL】覆盖索引和回表的更多相关文章
- mysql覆盖索引与回表
mysql覆盖索引与回表 Harri2012关注 62019.07.28 11:14:15字数 1,292阅读 77,322 select id,name where name='shenjian' ...
- mysql:如何利用覆盖索引避免回表优化查询
说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 ...
- 一篇文章讲清楚MySQL的聚簇/联合/覆盖索引、回表、索引下推
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子. 手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:"加班使我快乐". 面试官: ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- MySQL 覆盖索引
通常大家都会根据查询的WHERE 条件来穿件合适的索引,不过这只是索引优化的一个方面.设计优秀的索引应该考虑到整个查询,而不单单是WHERE 条件部分.索引确实是一种查找数据的高效方式,但是MySQL ...
- mysql覆盖索引详解
覆盖索引的定义: 如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’.即只需扫描索引而无须回表. 只扫描索引而无需回表的优点: 1.索引条目通常远小于数据行大小,只需要读取索引, ...
- Mysql覆盖索引与延迟关联
延迟关联:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据. 为什innodb的索引叶子节点存的是主键,而不是像myisam一样存数据的物理地址指针? 如果存的是物理地址指针不 ...
- MySQL 优化之 MRR (Multi-Range Read:二级索引合并回表)
MySQL5.6中引入了MRR,专门来优化:二级索引的范围扫描并且需要回表的情况.它的原理是,将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机IO,转变成顺序IO.文档 ...
- mysql覆盖索引(屌的狠,提高速度)
话说有这么一个表: CREATE TABLE `user_group` ( `id` int(11) NOT NULL auto_increment, `uid` int(11) NOT NULL, ...
随机推荐
- iOS Block 页面传值
为什么80%的码农都做不了架构师?>>> 直接上代码 1.定义block @interface TopTypeCollectionView : UIView @property ...
- BlackNurse攻击:4Mbps搞瘫路由器和防火墙
研究人员宣称,最新的知名漏洞BlackNurse,是一种拒绝服务攻击,能够凭借仅仅15到18Mbps的恶意ICMP数据包就将防火墙和路由器干掉. 该攻击会滥用Internet控制报文协议(ICMP)第 ...
- nat和静态映射
拓扑图: 实验要求: 1.R2.R3能访问外网的4.4.4.4(4.4.4.4为R4上的环回接口,用来模拟inter网). 2.R4访问222.222.222.100其实访问到的是内网的192.168 ...
- 使用ScriptX控件进行Web横向打印
一个需求需要采用横向打印,目前采用IE自身的打印功能(WebBrowser.ExecWB控件)很难进行横向设置,默认需要调用document.all.WebBrowser.ExecWB(8,1);打开 ...
- File Operations
在刷题测试程序时,为了避免每次都手工输入,我们可以把输入数据保存在文件中:为了避免输出太长,我们将输出也写入文件中,方便与标准答案文件进行比较. 文件使用一般有两种方法:输入输出重定向.fopen. ...
- 数学--数论--直角三角形--勾股数---奇偶数列法则 a^2+b^2=c^2
先说勾股数: 勾股数,又名毕氏三元数 .勾股数就是可以构成一个直角三角形三边的一组正整数.勾股定理:直角三角形两条直角边a.b的平方和等于斜边c的平方(a²+b²=c²) 勾股数规律: 首先是奇数组口 ...
- python模块之time and datetime
time # python3 # coding = utf-8 import time timestamp = time.time() print('timestamp:%s, type: %s' % ...
- Redis服务器和客户端的通信
Redis客户端使用RESP(Redis序列化协议)与Redis服务器进行通信,RESP在位于TCP之上,而网络模型上客户端和服务器是保持的双工的连接.如图1 而一个简单的请求/响应的串行通信模型如下 ...
- HTTP GET | POST | DELETE请求
依赖: <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp& ...
- hue搭建
1.安装依赖: sudo yum -y install gcc-c++ asciidoc cyrus-sasl-devel cyrus-sasl-gssapi krb5-devel libxml2-d ...