celery异步消息队列的使用
1、准备工作
1.1 流程图
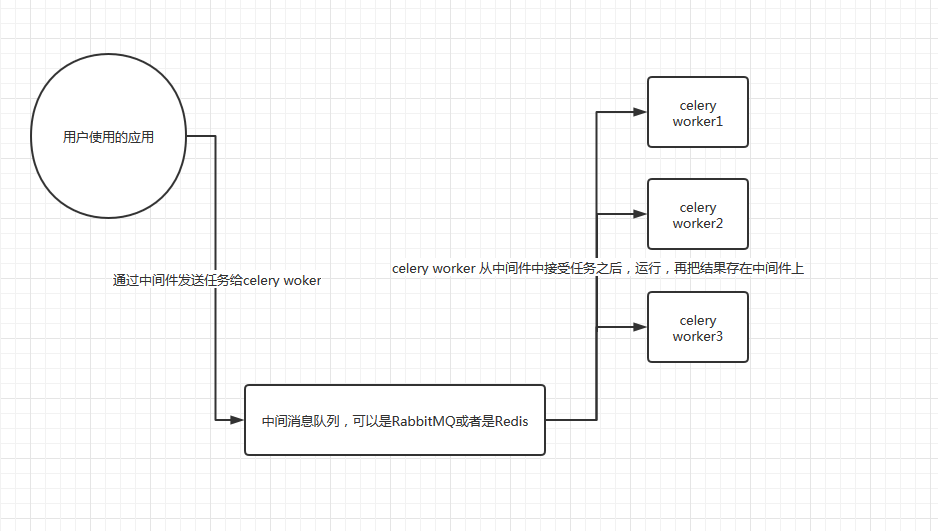
2、环境安装
2.1、在Ubuntu中需要安装redis
安装redis
$sudo apt-get update
$sudo apt-get install redis-server
启动redis
$redis-server
连接redis
$redis-cli
$redis-cli -h ip -a
安装Python操作redis的包
pip install redis
重启redis
sudo service reids restart
安装redis
redis默认绑定的ip为127.0.0.1其他电脑无法访问Ubuntu的redis

重启redis服务 service redis restart
查看绑定端口
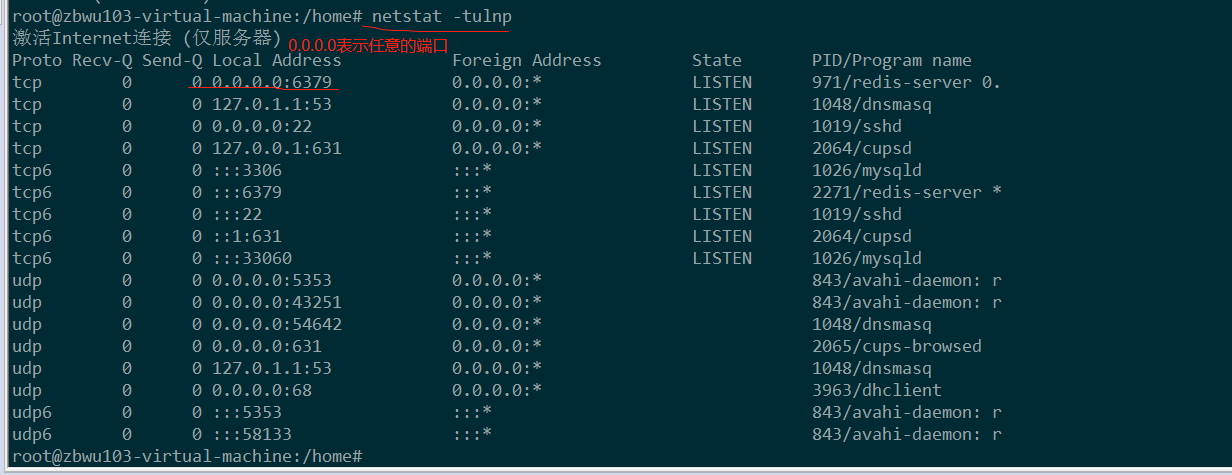
在wind上telnet ip 6379 成功说明成功
2.2、安装celery
pip install celery
2、开始使用celery
2、1基本应用
在/home/zbwu103/celery 文件中创建一个tasks.py的任务文件
#task.py
from celery import Celery
app = Celery('tasks',
broker='redis://192.168.1.111',
backend='redis://192.168.1.111'
#redis://密码@ip
)
@app.task
def add(x,y):
print("running...",x,y)
return x+y
在home/zbwu103/celery的目录启动监听任务
#打印日志的模式运行
celery -A tasks worker --loglevel=info
在开一个终端,到/home/zbwu103/celery用Python进入命令行运行
from tasks import add
t = add.delay(4,5) #t.result.ready() 查看任务是否完成,完成返回True,未完成返回False
#t.get() 返回完成之后的结果
#t.task_id 返回任务的唯一ID号,可以通过ID查询到任务
上面任务都是在终端上运行,如果终端关闭tasks也会终止。
所以需要任务在后台运行

celery multi stop w1 停止 w1
2.2 、在项目中如何使用celery


from __future__ import absolute_import, unicode_literals
from celery import Celery app = Celery('my_proj',
broker='redis://192.168.1.111',
backend='redis://192.168.1.111',
include=['myp_roj.tasks']) app.conf.update(
result_expires=3600,
)
if __name__ == '__main__':
app.start()
celery
from __future__ import absolute_import, unicode_literals
import subprocess
from .celery import app @app.task
def add(x,y):
return x+y @app.task
def run_cmd(cmd):
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
return obj.stdout.read().decode('utf-8')
tasks.py
在my_proj同级目录启动

查看任务启动情况
ps -ef |grep celery
2.3 、celery 定时任务
celery使用beat来执行celert beat 来实现定时任务
worker定时任务
from celery import Celery
from celery.schedules import crontab app = Celery('task',
broker='redis://192.168.1.111',
backend='redis://192.168.1.111') @app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# Calls test('hello') every 10 seconds.
sender.add_periodic_task(10.0, test.s('hello'), name='add every 10') # Calls test('world') every 30 seconds
sender.add_periodic_task(30.0, test.s('world'), expires=10) # Executes every Monday morning at 7:30 a.m.
sender.add_periodic_task(
crontab(hour=21, minute=26, day_of_week='Sum'),
test.s('Happy Mondays!'),
) @app.task
def test(arg):
print('runing test.....')
print(arg)
periodic_task.py
启动定时任务
celery -A periodic_task worker
另外开一个任务调度区不断的检测你的任务计划
celery -A periodic_task beat
2.4、celery和django配置一起使用
在setting同级的目录中新建一个celery.py的文件配置celery基本的配置

from __future__ import absolute_import, unicode_literals
import os
from celery import Celery # set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'CeleryTest.settings') app = Celery('CeleryTest') # Using a string here means the worker don't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY') # Load task modules from all registered Django app configs.
app.autodiscover_tasks() @app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))
celery.py
在setting.py同级的目录配置__init__.py
from __future__ import absolute_import, unicode_literals # This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app __all__ = ['celery_app']
__init__.py
在APP的目录里面新建一个tasks.py的任务来填写任务
#app01/tasks.py
# Create your tasks here
from __future__ import absolute_import, unicode_literals
from celery import shared_task
import time @shared_task
def add(x, y):
print("running task add,我是windows ")
time.sleep(1)
return x + y @shared_task
def mul(x, y):
return x * y @shared_task
def xsum(numbers):
return sum(numbers)
tasks.py
从views中调用任务
/app01/view.py
from django.shortcuts import render,HttpResponse
from app01 import tasks
from celery.result import AsyncResult def index(request): res = tasks.add.delay(5,999) print("res:",res)
print(res.status)
# import pdb
# pdb.set_trace()
return HttpResponse(res.task_id) def task_res(request):
#通过ID获取结果
result = AsyncResult(id="be4933c0-ed9b-4a04-ade8-79f4c57cfc74") #return HttpResponse(result.get())
return HttpResponse(result.status)
views.py
2.5、在django中使用定时的任务
在Ubuntu中安装django-celery-beat插件
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple django-celery-beat
在setting中增加APP
’‘django_celery_beat",
使用Python manage.py migrate 生成表结构
直接可以在django的admin配置任务
之后在Ubuntu中启动celery worker
celery -A CeleryTest worker -l info
启动调度器来监控定时任务
celery -A CeleryTest beat -l info -S django
注意,经测试,每添加或修改一个任务,celery beat都需要重启一次,要不然新的配置不会被celery beat进程读到
celery异步消息队列的使用的更多相关文章
- 异步消息队列Celery
Celery是异步消息队列, 可以在很多场景下进行灵活的应用.消息中包含了执行任务所需的的参数,用于启动任务执行, suoy所以消息队列也可以称作 在web应用开发中, 用户触发的某些事件需要较长事件 ...
- C#实现异步消息队列
原文:C#实现异步消息队列 拿到新书<.net框架设计>,到手之后迅速读了好多,虽然这本书不像很多教程一样从头到尾系统的讲明一些知识,但是从项目实战角度告诉我们如何使用我们的知识,从这本书 ...
- 八.利用springAMQP实现异步消息队列的日志管理
经过前段时间的学习和铺垫,已经对spring amqp有了大概的了解.俗话说学以致用,今天就利用springAMQP来完成一个日志管理模块.大概的需求是这样的:系统中有很多地方需要记录操作日志,比如登 ...
- C#后台异步消息队列实现
简介 基于生产者消费者模式,我们可以开发出线程安全的异步消息队列. 知识储备 什么是生产者消费者模式? 为了方便理解,我们暂时将它理解为垃圾的产生到结束的过程. 简单来说,多住户产生垃圾(生产者)将垃 ...
- 【Redis】redis异步消息队列+Spring自定义注解+AOP方式实现系统日志持久化
说明: SSM项目中的每一个请求都需要进行日志记录操作.一般操作做的思路是:使用springAOP思想,对指定的方法进行拦截.拼装日志信息实体,然后持久化到数据库中.可是仔细想一下会发现:每次的客户端 ...
- 三.RabbitMQ之异步消息队列(Work Queue)
上一篇文章简要介绍了RabbitMQ的基本知识点,并且写了一个简单的发送和接收消息的demo.这一篇文章继续介绍关于Work Queue(工作队列)方面的知识点,用于实现多个工作进程的分发式任务. 一 ...
- [源码解析] 消息队列 Kombu 之 基本架构
[源码解析] 消息队列 Kombu 之 基本架构 目录 [源码解析] 消息队列 Kombu 之 基本架构 0x00 摘要 0x01 AMQP 1.1 基本概念 1.2 工作过程 0x02 Poll系列 ...
- 开源消息队列:NetMQ
NetMQ 是 ZeroMQ的C#移植版本. ZeroMQ是一个轻量级的消息内核,它是对标准socket接口的扩展.它提供了一种异步消息队列,多消息模式,消息过滤(订阅),对多种传输协议的无缝访问. ...
- 消息队列NetMQ 原理分析1-Context和ZObject
前言 介绍 NetMQ是ZeroMQ的C#移植版本,它是对标准socket接口的扩展.它提供了一种异步消息队列,多消息模式,消息过滤(订阅),对多种传输协议的无缝访问. 当前有2个版本正在维护,版本3 ...
随机推荐
- swift 3.0字符串的简单使用
let str:String = "12314124" 获取某个指定位置的元素 print(str.characters[str.index(str.startIndex, off ...
- 命令替换、权限、chmod、特殊权限
命令替换 把字符串里面的命令先执行再把该字符串输出,与PHP的""里面的变量被执行一样. $(COMMAND) `COMMAND` [root@jiakang ~]# echo & ...
- 狄慧201771010104《面向对象程序设计(java)》第十六周学习总结
实验十六 线程技术 实验时间 2017-12-8 一.知识点总结: 1.程序与进程的概念 ‐程序是一段静态的代码,它是应用程序执行的蓝本. ‐进程是程序的一次动态执行,它对应了从代码加载.执行至执行 ...
- 算法竞赛进阶指南--hamilton路径
// hamilton路径 int f[1 << 20][20]; int hamilton(int n, int weight[20][20]) { memset(f, 0x3f, si ...
- requests抓取数据示例
1:获取豆瓣电影名称及评分 # 抓取豆瓣电影名称及评分 url="https://movie.douban.com/j/search_subjects" start=input(& ...
- DataHub——实时数据治理平台
DataHub 首先,阿里云也有一款名为DataHub的产品,是一个流式处理平台,本文所述DataHub与其无关. 数据治理是大佬们最近谈的一个火热的话题.不管国家层面,还是企业层面现在对这个问题是越 ...
- 微软原文翻译:适用于.Net Core的WPF数据绑定概述
原文链接,大部分是机器翻译,仅做了小部分修改.英.中文对照,看不懂的看英文. Data binding overview in WPF 2019/09/19 Data binding in Windo ...
- QtCreator MSVC 搭建 Debugger
QtCreatorForWindows搭建Debugger QtCreator for windows选择mingw或者msvc: qt-opensource-windows-x86-msvc2015 ...
- Linux设备模型之kobject
阿辉原创,转载请注明出处 参考文档:LDD3-ch14.内核文档Documentation/kobject.txt,本文中使用到的代码均摘自Linux-3.4.75 ----------------- ...
- Airtable base
PC端习惯了SQL Server Express.Access数据库的强大,安卓端再去用Microsoft Office.WPS,能让你怀疑人生.使用Airtable是个不错的方案,workspace ...