分库分表实践-Sharding-JDBC
最近一段时间在研究分库分表的一些问题,正好周末有点时间就简单做下总结,也方便自己以后查看。
本文只讲述使用Sharding-JDBC做分库分表的一些实践经验,如果有错误欢迎大家指出。
什么是Sharding-JDBC

Sharding-jdbc是当当网开源的一款客户端代理中间件。Sharding-jdbc包含分库分片和读写分离功能。对应用的代码没有侵入型,几乎没有任何改动,兼容主流orm框架,主流数据库连接池。目前属于Apache的孵化项目ShardingSphere。
Sharding-jdbc定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
官方文档地址
ShardingSphere:https://shardingsphere.apache.org/
GitHub的地址:https://github.com/apache/incubator-shardingsphere
一些建议和说明
不过我这里建议大家可以简单过下官方文档,因为文档并不全面或者说感觉并不是最新的。
建议大家重点可以放在git上官方的examples
目前官方最新的版本是4.0,如果使用springboot创建,可以使用下面的依赖即可。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0</version>
</dependency>
Sharding-jdbc功能强大,但是本文重点在于下面几点,未涉及的地方可以翻阅文档查看。
1、单库分表
2、分库分表(含分库单表)
3、分表后的查询
4、分表事务处理
无论上述哪种分库亦或是分表类型,核心无非是下面几个配置:
1、配置数据源,明确你有多少个数据源
2、定义表名,分表的逻辑表名(t_order)和所有物理表名(t_order_0,t_order_1)
3、定义分库列以及分库算法
4、定义分表列以及分表算法
代码实现
单库分表
sharding-jdbc优势就是对代码没有侵入性,基本上不用动我们原来的代码,只是将相关数据库连接的配置更换为sharding的配置即可。
以我的个人实践项目为例:
原来不分表时的配置:
#项目配置
spring:
#数据连接配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx.xx.xx.xx:3306/yyms?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xxx
password: xxx
使用sharding后的配置
# 分表配置
spring:
shardingsphere:
datasource:
names: yyms
yyms:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxx.xx.xx.xx:3306/yyms?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xx
password: xxx
sharding:
tables:
# 表名
sys_log:
actual-data-nodes: yyms.sys_log_$->{0..1}
# 分表配置,根据id分表
table-strategy:
inline:
sharding-column: id
algorithm-expression: sys_log_$->{id % 2}
# 配置字段的生成策略,column为字段名,type为生成策略,sharding默认提供SNOWFLAKE和UUID两种,可以自己实现其他策略
key-generator:
column: id
type: SNOWFLAKE
props:
sql:
show: true
上面的配置基本上就实现了单库对sys_log表的拆分,根据id取模算法,拆分为sys_log_0和sys_log_1两张表。代码层面没有任何改动就实现了拆分,拆分后效果图如下。

注意哦,sys_log表拆分后是实际不存在的。
当然了,使用官方的默认配置很多时候并不能满足我们的需求。
假如拿到一条数据的id后再去计算数据在哪个库,无疑对我们日常的运维维护工作造成极大的不便。这里我们可以通过一些简单的自定义开发配置实现。
比如我想要id最后一位展示数据所处表所在序号。
多库分表
先展示个多库单表的案例
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds_1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxxx:3306/ds1?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xxxx
password: xxx
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxx:3306/ds0?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xxxx
password: xxxx
sharding:
default-data-source-name: ds0
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: ds$->{id % 2}
tables:
sys_log:
actual-data-nodes: ds$->{0..1}.sys_log
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 123
把单张表拆分到多个库,同样使用sys_log。效果图如下:
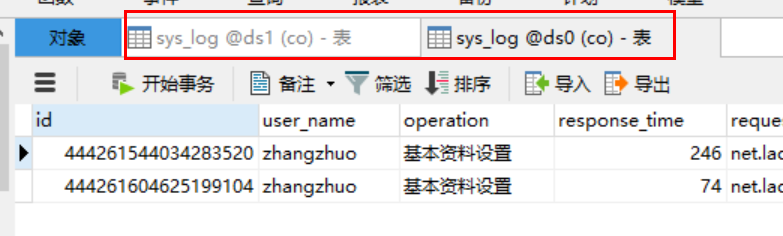
其实分库分表无非就是上面两种模式的集合,具体配置的选项,可以参考官方案例配置》》》我是链接
分库分表后的查询
select * from sys_log where id='444271380247588864'
接着上面的案例,以上面的语句为例,id为分库列,sharding经过解析后定位到对应的数据源,直接执行下面的查询。
select * from sys_log where id='444271380247588864'
假如我们的查询调节不包含分库列,以下面的语句为例:
select * from sys_log where user_name='zhangsan
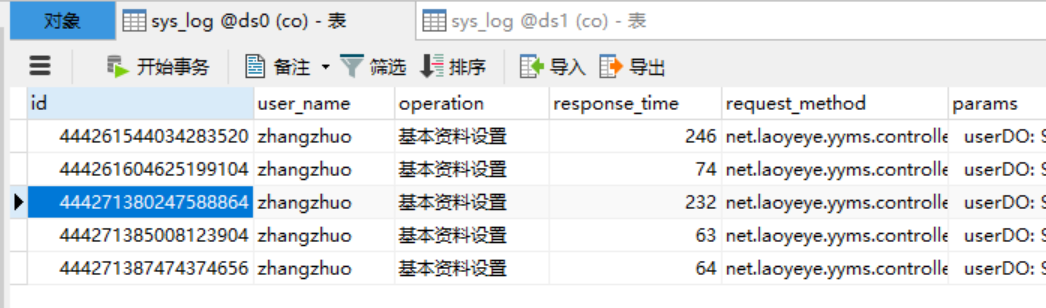
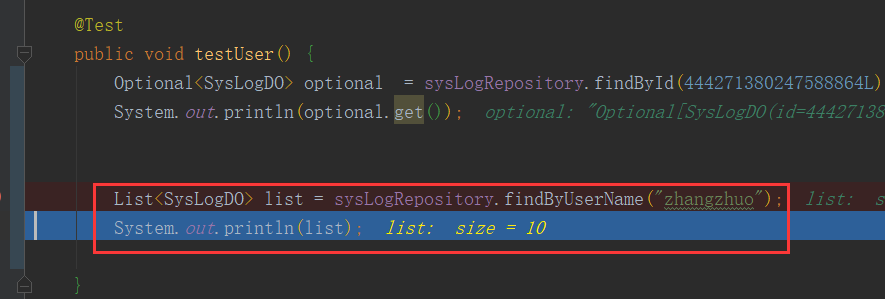
执行后出现两条sql语句。我们在两个库均为5条数据,查询后的结果集为10条数据,符合我们的预期。
数据库:
结果集:
结论:当搜索条件含有分库列(分表列),这时候sharing会首先调用分库分表策略类,直接找到对应的数据库和对应子表。而当搜索条件不含有分库列时,这时候引擎就不会再调用策略类了,而是会直接认定目标库为全部库或表,上述案例中目标库就是,[ds0,ds1]两个数据源,既然目标库有两个,后面生成的DataNode,TableUnits,PreparedStatementUnit 将是以前数量的两倍,所以这回,引擎最终将会发起多个sql语句的并发执行,并合并最终的结果再返回。
分库分表后的事务
Sharding-Sphere同时支持XA和柔性事务,它允许每次对数据库的访问,可以自由选择事务类型。分布式事务对业务操作完全透明,极大地降低了引入分布式事务的成本。
分布式事务我感觉在官方的文档和案例中写的已经是比较完善的了,这里大家可以参考:我是链接 官方案例实现,这里就不在赘述了。
最后是项目的参考代码:https://github.com/allanzhuo/yyms
分库分表实践-Sharding-JDBC的更多相关文章
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- MariaDB Spider 数据库分库分表实践
分库分表 一般来说,数据库分库分表,有以下做法: 按哈希分片:根据一条数据的标识计算哈希值,将其分配到特定的数据库引擎中: 按范围分片:根据一条数据的标识(一般是值),将其分配到特定的数据库引擎中: ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表实践
一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于Spri ...
- oracle 分库分表(sharding)
以下文章转载博客:http://blog.csdn.net/bluishglc 讲的很深入透彻,转来分享下: 数据库Sharding的基本思想和切分策 http://blog.csdn.net/blu ...
- 一致性hash 大众点评订单分库分表实践
井底之蛙 https://mp.weixin.qq.com/s?src=3×tamp=1543228894&ver=1&signature=uF6nV0yYseJ55 ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- 分库分表技术演进&最佳实践
每个优秀的程序员和架构师都应该掌握分库分表,这是我的观点. 移动互联网时代,海量的用户每天产生海量的数量,比如: 用户表 订单表 交易流水表 以支付宝用户为例,8亿:微信用户更是10亿.订单表更夸张, ...
- 数据库分库分表(sharding)系列(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
作为一种数据存储层面上的水平伸缩解决方案,数据库Sharding技术由来已久,很多海量数据系统在其发展演进的历程中都曾经历过分库分表的Sharding改造阶段.简单地说,Sharding就是将原来单一 ...
随机推荐
- Spring Cloud Feign 组成和配置
Feign的组成 接口 作用 默认值 Feign.Builder Feign的入口 Feign.Builder Client Feign底层用什么去请求 和Ribbon配合时:LoadBalancer ...
- java基础知识点补充---二维数组
#java基础知识点补充---二维数组 首先定义一个二维数组 int[][] ns={ {1,2,3,4}, {5,6,7,8}, {9,10,11,12}, {13,14,15,16} }; 实现遍 ...
- CentOS7 安装python 3.5 及 pip安装
1.CentOS7 安装Python 的依赖包 # yum install -y zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-d ...
- 攻防世界Mobile6 app1 XCTF详解
XCTF_app1 先安装看看 点击芝麻开门之后会弹出“年轻人不要耍小聪明噢” 这大概就能看懂是点击之后进行判断,那就直接去看JEB,看看判断条件是什么 V1是输入的字符串,V2获取包信息(百度的), ...
- echart 之实现温度计
百度这个图表支持不是很好,有的需要自己写,看大神们实现温度计都是用 水球特效实现的我这里雕虫小计啊但是满足我了我的项目需求特此分享出来,可惜自己不是专业的前端 这是我的实现结果 好了上代码html: ...
- H5多列布局
多列布局 基本概念 1.多列布局类似报纸或杂志中的排版方式,上要用以控制大篇幅文本. 2.跨列属性可以控制横跨列的数量 /*列数*/ -webkit-column-count: 3; /*分割线*/ ...
- LeetCode 81.Search in Rotated Sorted Array II(M)
题目: Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand. ( ...
- 复习笔记——1. C语言基础知识回顾
1. 数据类型 1.1 基本数据类型 整型:int, long,unsigned int,unsigned long,long long-- 字符型:char 浮点型:float, double-- ...
- 【Java面试题】关于String,最近被问到了这2道面试题
1. 前言 最近面试了几家公司,体验了一下电话面试和今年刚火起来的视频面试, 虽然之前就有一些公司会先通过电话面试的形式先评估下候选人的能力水平,但好像不多,至少我以前的面试形式100%都是现场面试. ...
- 第十章、Vue项目的联调上线
抓包 Fiddler 一.解决跨域 proxyTable(查看博客总结) 二.解决用本机ip地址不能访问 在dev中加上 --host 0.0.0.0就可以用本机ip访问,这样的话可以用手机在内网(局 ...