最长回文子窜O(N)
字符窜同构的性质:同构字符窜拥有最小和最大的表示方法;
最长回文子窜:
1.首先暴力法:(n三方)
枚举每个起点和终点,然后单向扫描判断是不是回文子窜;
2.中心扩散法,(N方)
枚举每个中点,向外扩散,看以他为中心的回文子窜的长度是多少;
易证:复杂度N方
3.O(N)的做法;
我的理解:和扩展KMP有点相似,扩展KMP,我们为了不重复所以设定了破,po和ex[po],然后我们讨论i可能的答案是否已经包含在扫描的里面了,如果包含了直接赋值,没包含继续扫描;
我们对中心扩散的方法进行改进,
1.思想: 1)将原字符串S的每个字符间都插入一个永远不会在S中出现的字符(本例中用“#”表示),在S的首尾也插入该字符,使得到的新字符串S_new长度为2*S.length()+1,保证Len的长度为奇数(下例中空格不表示字符,仅美观作用);
例:S: a a b a b b a
S_new: # a # a # b # a # b # b # a #
2)根据S_new求出以每个字符为中心的最长回文子串的最右端字符距离该字符的距离,存入Len数组中,即S_new[i]—S_new[r]为S_new[i]的最长回文子串的右段(S_new[2i-r]—S_new[r]为以S_new[i]为中心的最长回文子串),Len[i] = r - i + 1;
S_new: # a # a # b # a # b # b # a #
Len: 1 2 3 2 1 4 1 4 1 2 5 2 1 2 1
Len数组性质:Len[i] - 1即为以Len[i]为中心的最长回文子串在S中的长度。在S_new中,以S_new[i]为中心的最长回文子串长度为2Len[i] - 1,由于在S_new中是在每个字符两侧都有新字符“#”,观察可知“#”的数量一定是比原字符多1的,即有Len[i]个,因此真实的回文子串长度为Len[i] - 1,最长回文子串长度为Math.max(Len) - 1。
3)Len数组求解(线性复杂度(O(n))):
a.遍历S_new数组,i为当前遍历到的位置,即求解以S_new[i]为中心的最长回文子串的Len[i];
b.设置两个参数:sub_midd = Len.indexOf(Math.max(Len)表示在i之前所得到的Len数组中的最大值所在位置、sub_side = sub_midd + Len[sub_midd] - 1表示以sub_midd为中心的最长回文子串的最右端在S_new中的位置。起始sub_midd和sub_side设为0,从S_new中的第一个字母开始计算,每次计算后都需要更新sub_midd和sub_side;

c.当i < sub_side时,取i关于sub_midd的对称点j(j = 2sub_midd - i,由于i <= sub_side,因此2sub_midd - sub_side <= j <= sub_midd);当Len[j] < sub_side - i时,即以S_new[j]为中心的最长回文子串是在以S_new[sub_midd]为中心的最长回文子串的内部,再由于i、j关于sub_midd对称,可知Len[i] = Len[j]; 当Len[j] >= sub.side - i时说明以S_new[i]为中心的回文串可能延伸到sub_side之外,而大于sub_side的部分还没有进行匹配,所以要从sub_side+1位置开始进行匹配,直到匹配失败以后,从而更新sub_side和对应的sub_midd以及Len[i];
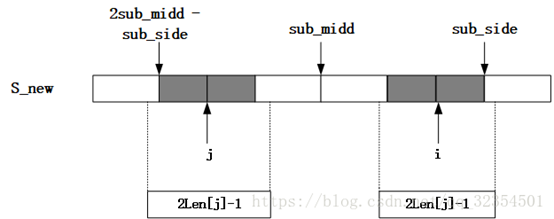
d.当i > sub_side时,则说明以S_new[i]为中心的最长回文子串还没开始匹配寻找,因此需要一个一个进行匹配寻找,结束后更新sub_side和对应的sub_midd以及Len[i]。
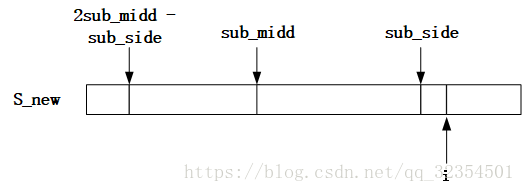
我的理解:
实际上我们每次扫描得到了sub_mid和sub_side,利用回文串的对称性,我们来判断是否已经在答案里面了,不在的我们就继续扫描比较下去;
就是对中心扩散法的一种dp;
与那个啥z函数有点类似的想法,利用性质推到到已经求过的内容然后及进行求解,避免重复扫描;
void getlen(char *str)
{
int ans=1,arm=0;
memset(len,0,sizeof(len));
int mid=0,side=1,i,j,r;
len[0]=1;
for(i=1;i<R;i++)
{
j=2*mid-i;
if(j<0||j-len[j]<=mid-len[mid])
{
r=side-i;
if(r==0) side++,r=1;
while(i-r>=0&&str[i-r]==str[side])
{
r++;
side++;
}
mid=i;
len[i]=r;
}
else
len[i]=len[j];
if(ans<len[i])
{
ans=len[i];
arm=i;
}
}
if(ans-1<2)
cout<<"No solution!\n";
else
{
int r=arm+len[arm]-1,l=arm-(len[arm]-1);
r--;
l=l/2;r=r/2;
cout<<l<<" "<<r<<"\n";
for(int i=l;i<=r;i++)
slove(s1[i]);
cout<<"\n";
}
}
最长回文子窜O(N)的更多相关文章
- LeetCode-5:Longest Palindromic Substring(最长回文子字符串)
描述:给一个字符串s,查找它的最长的回文子串.s的长度不超过1000. Input: "babad" Output: "bab" Note: "aba ...
- 1. Longest Palindromic Substring ( 最长回文子串 )
要求: Given a string S, find the longest palindromic substring in S. (从字符串 S 中最长回文子字符串.) 何为回文字符串? A pa ...
- 最长回文子序列(LPS)
问题描述: 回文是正序与逆序相同的非空字符串,例如"civic"."racecar"都是回文串.任意单个字符的回文是其本身. 求最长回文子序列要求在给定的字符串 ...
- 最长回文子串(动规,中心扩散法,Manacher算法)
题目 leetcode:5. Longest Palindromic Substring 解法 动态规划 时间复杂度\(O(n^2)\),空间复杂度\(O(n^2)\) 基本解法直接看代码 class ...
- [LeetCode] Longest Palindromic Substring 最长回文串
Given a string S, find the longest palindromic substring in S. You may assume that the maximum lengt ...
- 求最长回文子串:Manacher算法
主要学习自:http://articles.leetcode.com/2011/11/longest-palindromic-substring-part-ii.html 问题描述:回文字符串就是左右 ...
- Manacher's algorithm: 最长回文子串算法
Manacher 算法是时间.空间复杂度都为 O(n) 的解决 Longest palindromic substring(最长回文子串)的算法.回文串是中心对称的串,比如 'abcba'.'abcc ...
- leetcode-5 最长回文子串(动态规划)
题目要求: * 给定字符串,求解最长回文子串 * 字符串最长为1000 * 存在独一无二的最长回文字符串 求解思路: * 回文字符串的子串也是回文,比如P[i,j](表示以i开始以j结束的子串)是回文 ...
- 最长回文子串(Longest Palindromic Substring)-DP问题
问题描述: 给定一个字符串S,找出它的最大的回文子串,你可以假设字符串的最大长度是1000,而且存在唯一的最长回文子串 . 思路分析: 动态规划的思路:dp[i][j] 表示的是 从i 到 j 的字串 ...
随机推荐
- 最详细的SSM(Spring+Spring MVC+MyBatis)项目搭建
速览 使用Spring+Spring MVC+MyBatis搭建项目 开发工具IDEA(Ecplise步骤类似,代码完全一样) 项目类型Maven工程 数据库MySQL8.0 数据库连接池:Druid ...
- Unity 游戏框架:UI 管理神器 UI Kit
UI Kit 快速入门 首先我们来进行 UI Kit 的快速入门 制作一个界面的,步骤如下: 准备 生成代码 逻辑编写 运行 1. 准备 先创建一个场景 TestUIHomePanel. 删除 Hie ...
- 关于Web2.0
前言:本来是想写HTML的,发现没什么好写的,就简单写一下Web2.0好了 什么是Web 2.0: "Web 2.0 is the business revolution in the co ...
- POJ3352 Road Construction Tarjan+边双连通
题目链接:http://poj.org/problem?id=3352 题目要求求出无向图中最少需要多少边能够使得该图边双连通. 在图G中,如果任意两个点之间有两条边不重复的路径,称为“边双连通”,去 ...
- PTA 创建计算机类
6-5创建计算机 (10分) 定义一个简单的Computer类,有数据成员芯片(cpu).内存(ram).光驱(cdrom)等等,有两个公有成员函数run.stop.cpu为CPU类的一个对象,ram ...
- 使用Keras进行深度学习:(二)CNN讲解及实践
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 现今最主流的处理图像数据的技术当属深度神经网络了,尤其是卷积神经网 ...
- PyTorch专栏(六): 混合前端的seq2seq模型部署
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/ 欢迎关注PyTorch官方中文教程站: http://pytorch.panchuang.net/ 专栏目录: 第一 ...
- CVPR 2019细粒度图像分类竞赛中国团队DeepBlueAI获冠军 | 技术干货分享
[导读]CVPR 2019细粒度图像分类workshop的挑战赛公布了最终结果:中国团队DeepBlueAI获得冠军.本文带来冠军团队解决方案的技术分享. 近日,在Kaggle上举办的CVPR 201 ...
- 新手必备 | 史上最全的PyTorch学习资源汇总
目录: PyTorch学习教程.手册 PyTorch视频教程 PyTorch项目资源 - NLP&PyTorch实战 - CV&PyTorch实战 PyTorch论 ...
- Sublimeの虚拟环境(Venv)设置
这里主要介绍,在使用 Python 虚拟环境(Venv)时,SublimeText 该怎么设置 为什么使用虚拟环境(Venv) 因为,我有洁癖! 我就是喜欢看到,pip list 命令下什么 Pack ...