python奇淫技巧之 抽屉 自动点赞
前言
嘿,各位小伙伴晚上好呀,今天又给大家带来干货内容啦,今天带来的是,如何自动登录抽屉,并且点赞
原计划打算,是不打算使用selenium的,但是因为要涉及点赞,所以免不了登录,但是我又被啪啪打脸了,抽屉的登录是真tm难,各种参数把我干懵逼了,最终,还是捡起了selenium,难逃真香定律呐
好了,废话补多少,撸起袖子就是干
准本工作
万年不变的套装...
Chromedriver:浏览器驱动,可以理解为一个没有界面的chrome浏览器
Selenium:用于模拟人对浏览器进行点击、输出、拖拽等操作,就相当于是个人在使用浏览器,也常常用来应付反爬虫措施
抽屉的点赞机制
假装我们都知道,要想点赞,需要要知道是谁点的,登录以后需要等保存状态,一般有cookie,seeeion,token三种形式,抽屉的怎么玩的呢,我们来图解一下

So,我们能看出来,只要登录之后,拿到了cookie,以后就不用 selenium 啦,所以,我这里将登录拿cooki和点赞分开写
开始干活
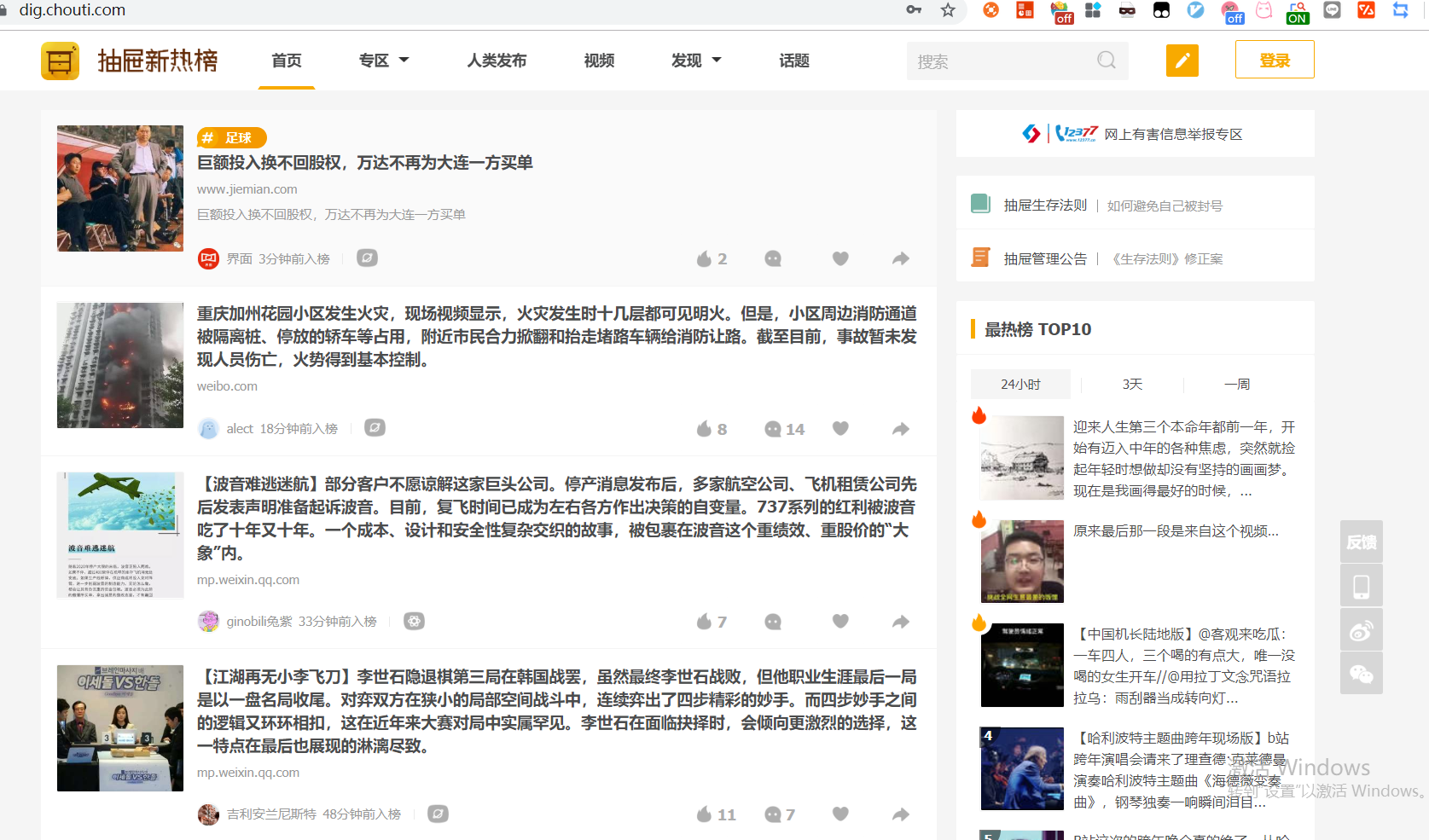
抽屉url:https://dig.chouti.com/
一个不正经的资讯社区,大概长这个样子,内容还挺不错
开始登录
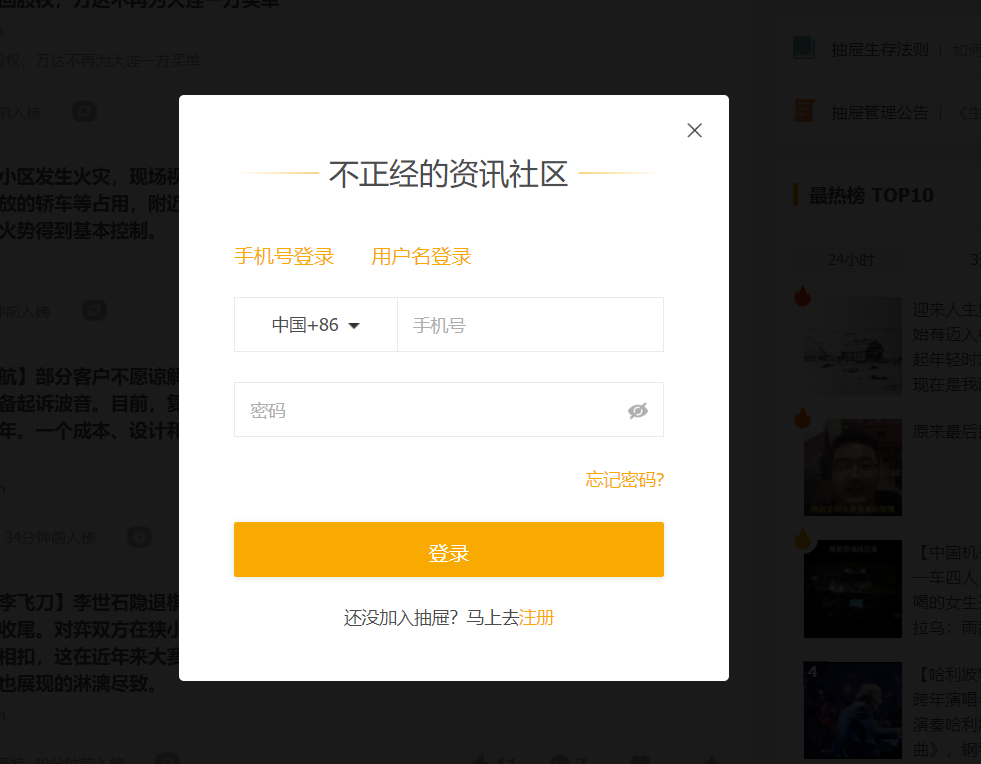
点击右上角登录,弹出登录模态对话框,下一步,用selenium盘它了,直接上代码
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait # 抽屉账号密码
PHONE = ""
PWD = "tian1936"
# 抽屉url
url = 'https://dig.chouti.com/' # 初始化
def init():
# 定义为全局变量,方便其他模块使用
global browser, wait
# 实例化一个chrome浏览器
browser = webdriver.Chrome(r"G:\installPage\chromedriver_win32 _78.0.3904.70\chromedriver.exe")
# 最大化窗口
browser.maximize_window()
time.sleep(2)
# 设置等待超时
wait = WebDriverWait(browser, 20) # 登录
def login():
# 打开登录页面
browser.get(url)
# # 获取用户名输入框
browser.find_element_by_id("login_btn").click()
# browser.find_element_by_class_name("input login-phone").send_keys(PHONE)
# browser.find_element_by_class_name("input pwd-input pwd-input-active pwd-password-input").send_keys(PHONE) # 输入账号密码
browser.find_element_by_name("phone").send_keys(PHONE)
browser.find_element_by_name("password").send_keys(PWD) # 点击登录
time.sleep(2)
click_login_btn_js = 'document.getElementsByClassName("btn-large")[0].click()'
browser.execute_script(click_login_btn_js)
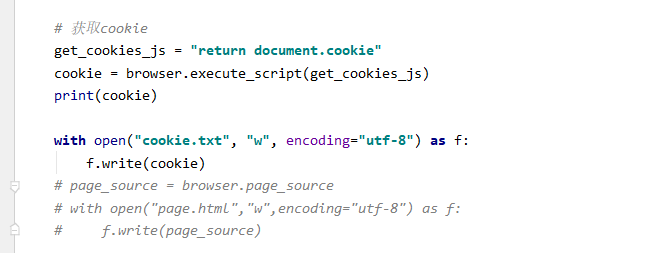
time.sleep(15) # 获取cookie
get_cookies_js = "return document.cookie"
cookie = browser.execute_script(get_cookies_js)
print(cookie) with open("cookie.txt", "w", encoding="utf-8") as f:
f.write(cookie)
# page_source = browser.page_source
# with open("page.html","w",encoding="utf-8") as f:
# f.write(page_source) if __name__ == '__main__':
init()
login()
自动登录抽屉
注意事项:因为此登录是模态对话框,所以用selenium是不能点击登录按钮的,需要执行js代码
如图所示

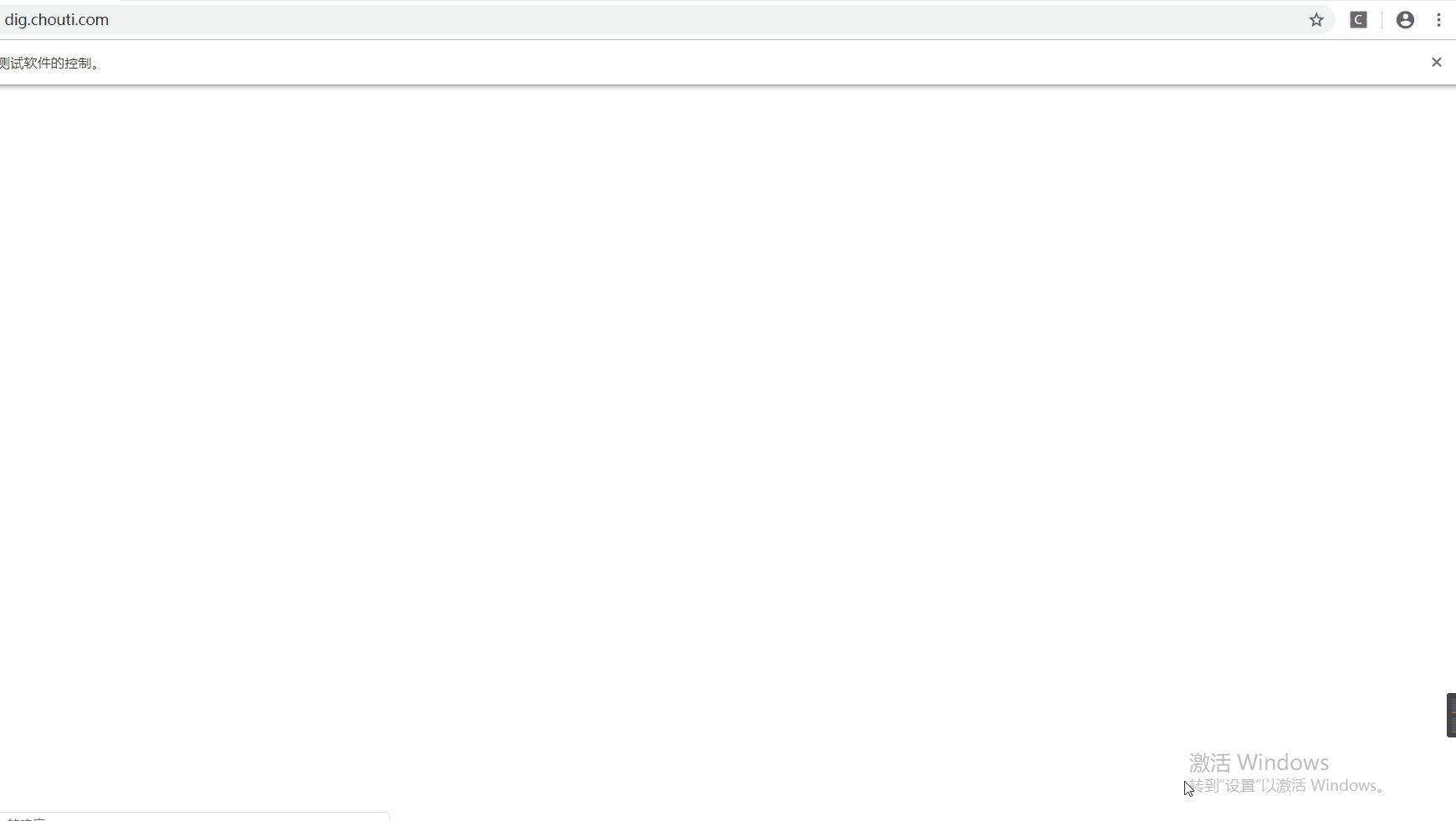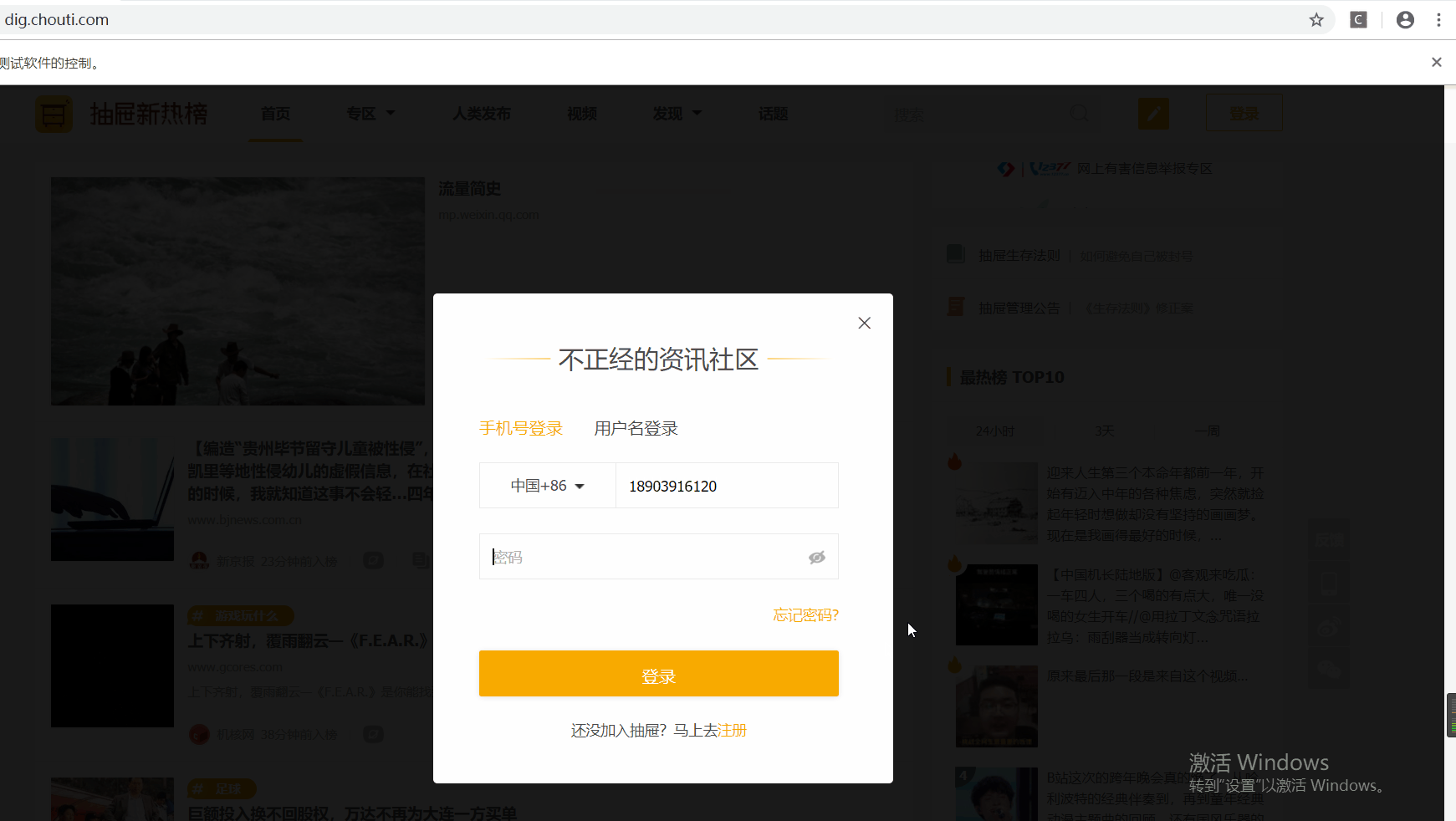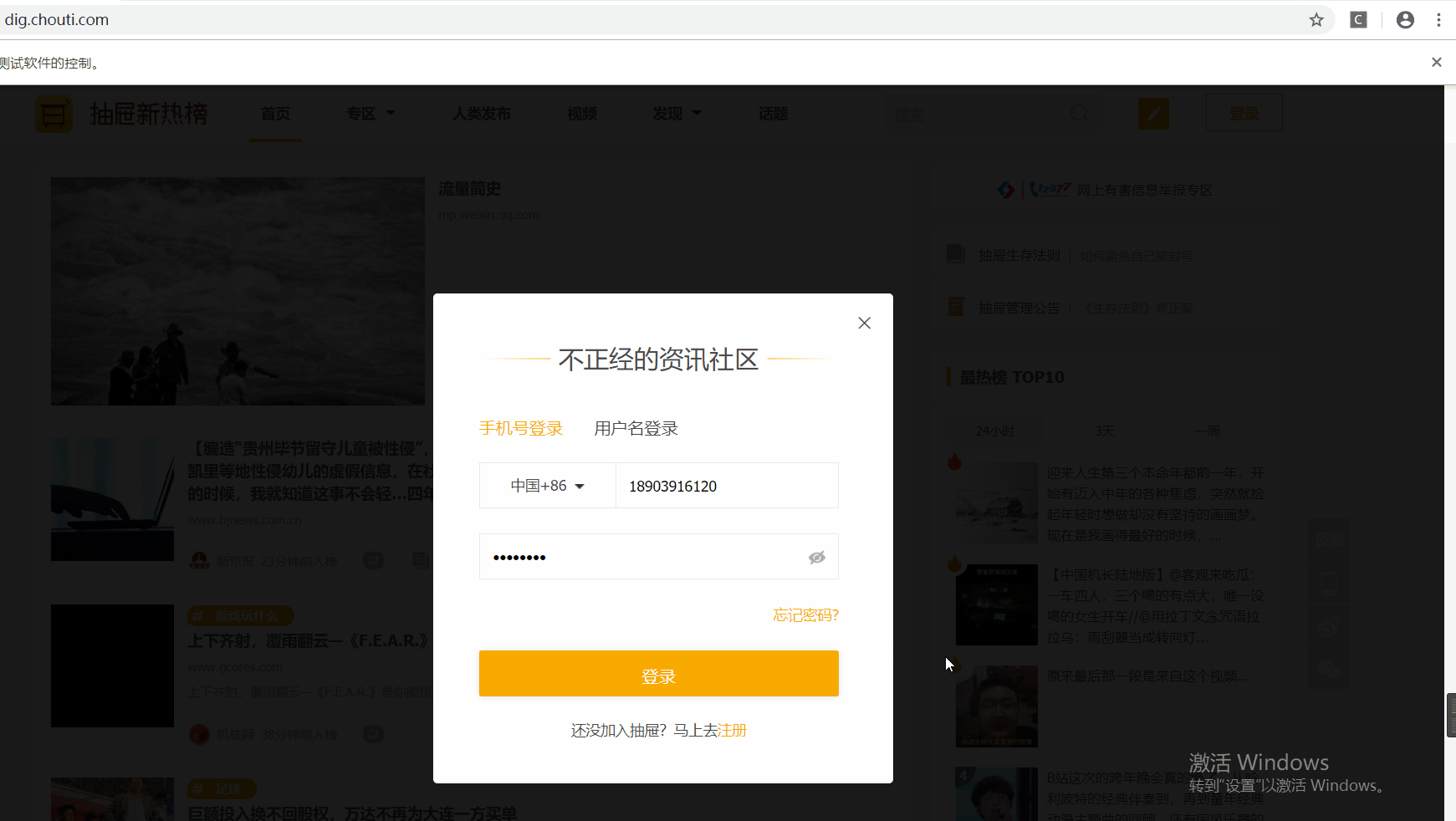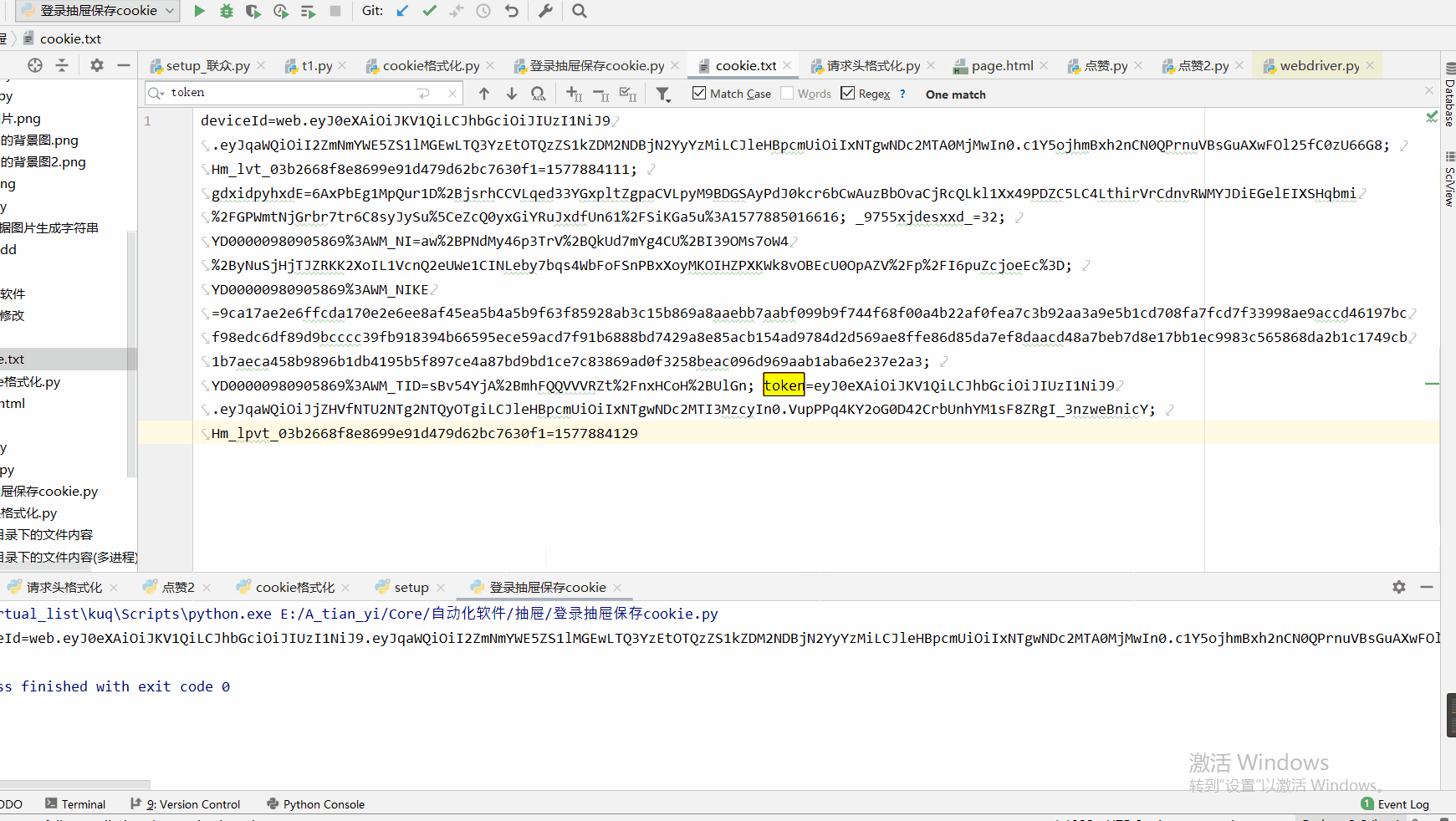
Cookie是怎么玩的呢,我他把写在了本地,但是测试发现selenium获取cookie不全,所以我们依然使用js获取
注意事项:抽屉如果登录多了,可能会让输入滑块验证码之类的,本文这部分并未有进行处理
自动登录示例效果图
开始自动点赞
上面我们已经成功的拿到登录返回的cookie了,所以,下面我们就好办多了
我们先看一下,点赞请求的是那个接口
我们清空NetWork日志,点击第一个文章的赞按钮
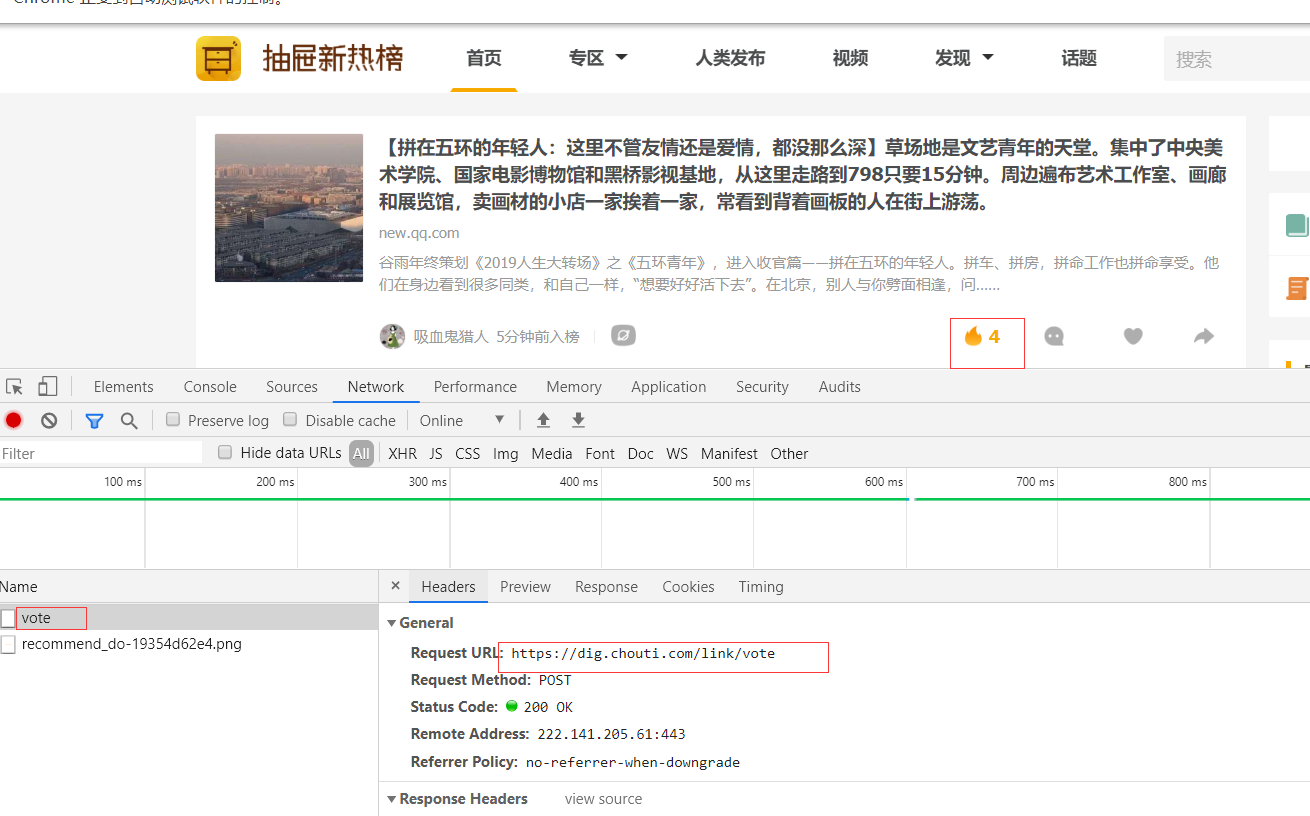
我们可以看到,这个接口发的是post请求,但是发送的是什么数据呢,我们下滑看看

2921....,我tm...,这个是什么玩意呢,马上揭晓!!!
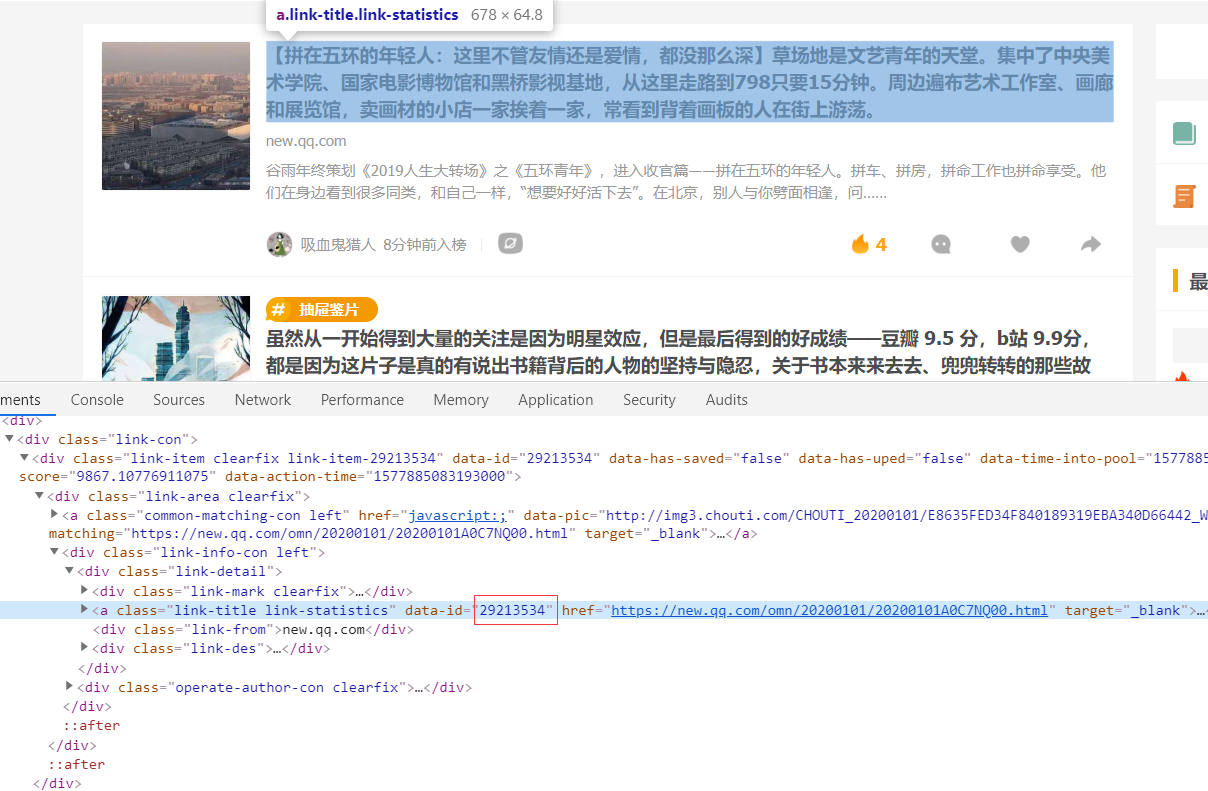
看出来吧,其实post的那一串数字,是文章ID,所以,我们只需要把这个ID都获取到,就可以点赞啦
Over,look code
import time from lxml import etree
import requests with open("cookie.txt", "r", encoding="utf-8") as f:
cookie = f.read() base_url = "https://dig.chouti.com/"
header_dict = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Host": "dig.chouti.com",
"Referer": "https://dig.chouti.com/?showLogin=true",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
}
r1 = requests.get(url=base_url, headers=header_dict)
r1.encoding = r1.apparent_encoding html = etree.HTML(r1.content) # 文章id列表
data_id_list = html.xpath("//a[@class='link-title link-statistics']/@data-id")
print(data_id_list) lick_url = "https://dig.chouti.com/link/vote"
header_dict = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": f"{cookie}",
"Host": "dig.chouti.com",
"Origin": "https://dig.chouti.com",
"Referer": "https://dig.chouti.com/",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
} # 点赞
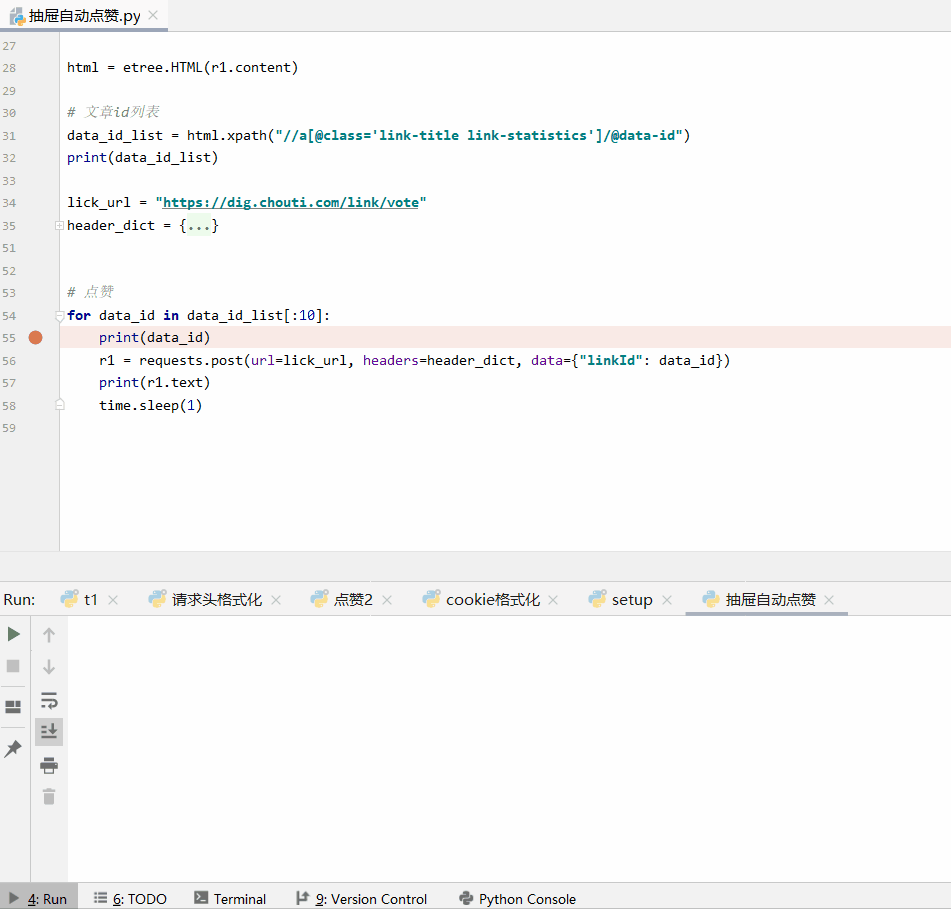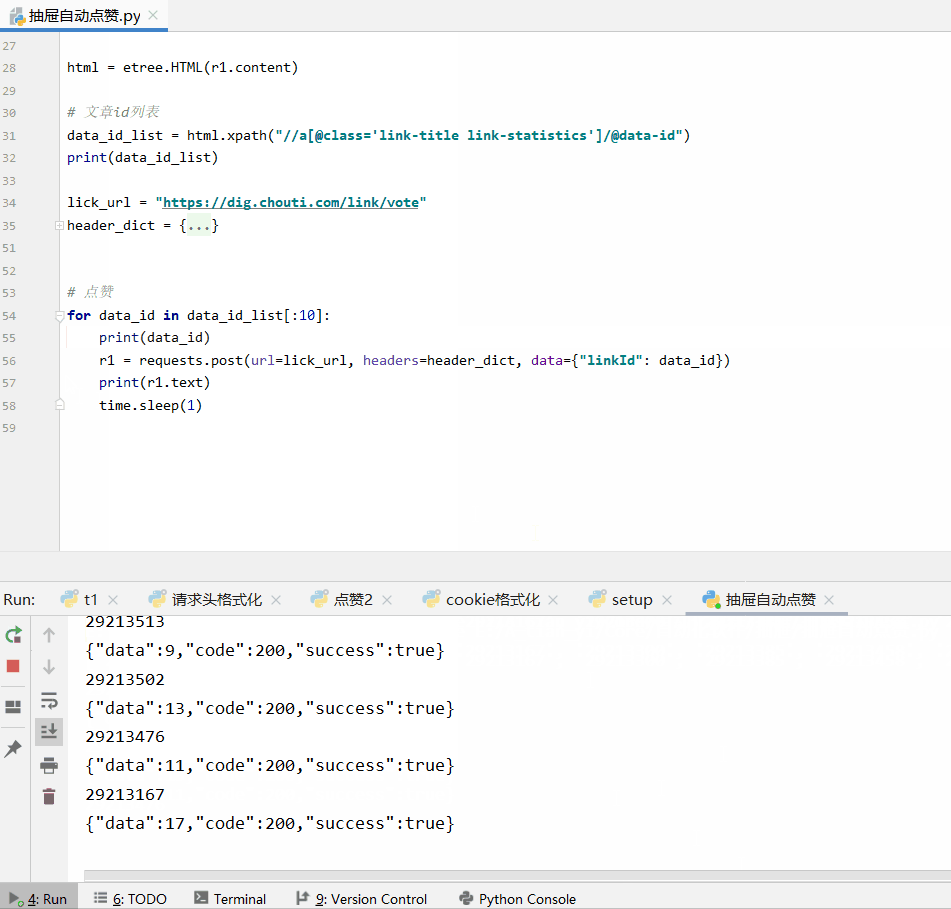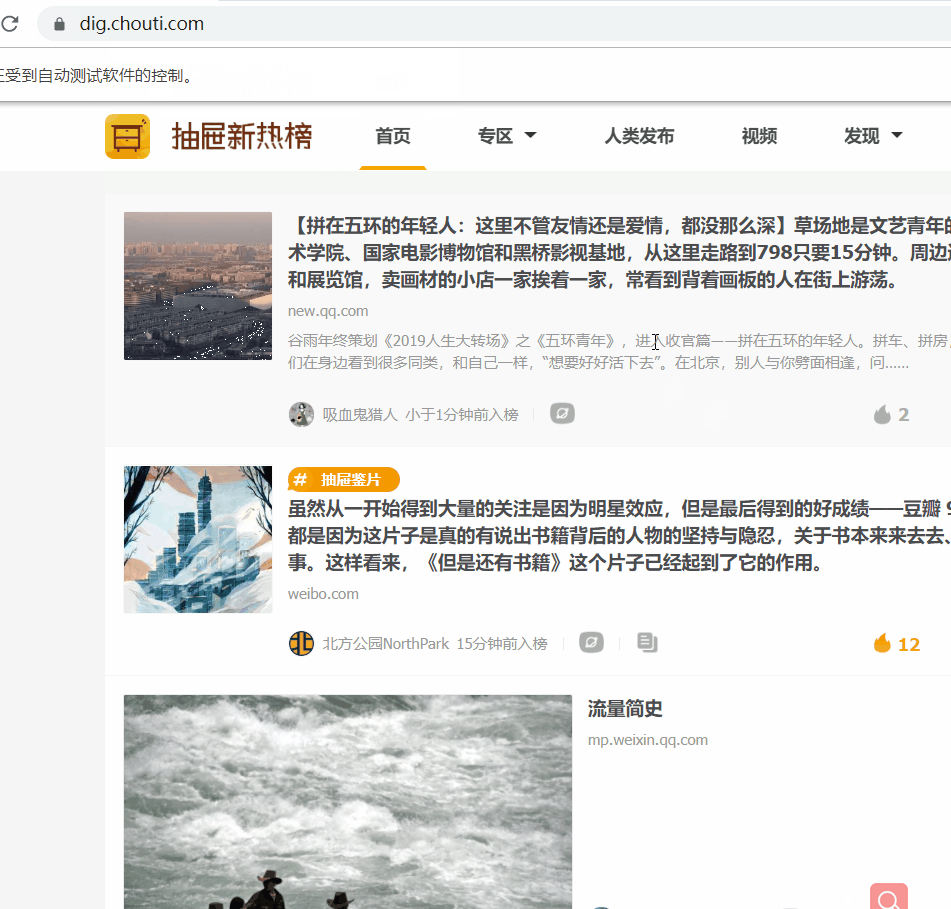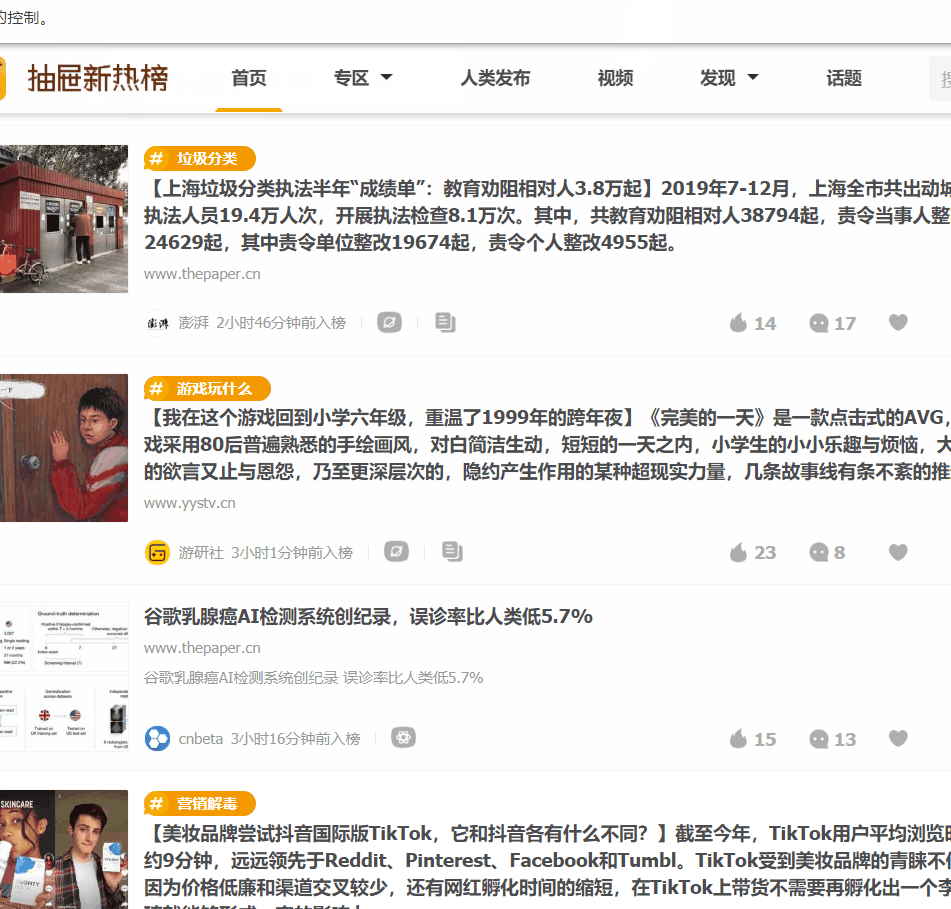
for data_id in data_id_list[:10]:
print(data_id)
r1 = requests.post(url=lick_url, headers=header_dict, data={"linkId": data_id})
print(r1.text)
time.sleep(1)
自动点赞
注:这里只是测试了前10个文章
效果图
python奇淫技巧之 抽屉 自动点赞的更多相关文章
- python 奇淫技巧之自动登录 哔哩哔哩
前言 嘿,各位小伙伴好呀,今天要带来点什么干货呢,就从我的实际开发中来给大家带来一个案例吧,如何自动登录 哔哩哔哩 接到老大通知,让我自动写一个自动登录 哔哩哔哩 的脚本,我当然是二话不说直接开怼,咱 ...
- Gradle更小、更快构建APP的奇淫技巧
本文已获得原作者授权同意,翻译以及转载原文链接:Build your Android app Faster and Smaller than ever作者:Jirawatee译文链接:Gradle更小 ...
- ASP.NET Core 奇淫技巧之伪属性注入
一.前言 开局先唠嗑一下,许久未曾更新博客,一直在调整自己的状态,去年是我的本命年,或许是应验了本命年的多灾多难,过得十分不顺,不论是生活上还是工作上.还好当我度过了所谓的本命年后,许多事情都在慢慢变 ...
- 优化DP的奇淫技巧
DP是搞OI不可不学的算法.一些丧心病狂的出题人不满足于裸的DP,一定要加上优化才能A掉. 故下面记录一些优化DP的奇淫技巧. OJ 1326 裸的状态方程很好推. f[i]=max(f[j]+sum ...
- 12个实用的 Javascript 奇淫技巧
这里分享12个实用的 Javascript 奇淫技巧.JavaScript自1995年诞生以来已过去了16个年头,如今全世界无数的网页在依靠她完成各种关键任务,JavaScript曾在Tiobe发布的 ...
- NGINX的奇淫技巧 —— 5. NGINX实现金盾防火墙的功能(防CC)
NGINX的奇淫技巧 —— 5. NGINX实现金盾防火墙的功能(防CC) ARGUS 1月13日 发布 推荐 0 推荐 收藏 2 收藏,1.1k 浏览 文章整理中...... 实现思路 当服务器接收 ...
- NGINX的奇淫技巧 —— 3. 不同域名输出不同伺服器标识
NGINX的奇淫技巧 —— 3. 不同域名输出不同伺服器标识 ARGUS 1月13日 发布 推荐 0 推荐 收藏 6 收藏,707 浏览 大家或许会有这种奇葩的需求...要是同一台主机上, 需要针对不 ...
- NGINX的奇淫技巧 —— 6. IF实现数学比较功能 (1)
NGINX的奇淫技巧 —— 6. IF实现数学比较功能 (1) ARGUS 1月13日 发布 推荐 0 推荐 收藏 3 收藏,839 浏览 nginx的if支持=.!= 逻辑比较, 但不支持if中 & ...
- Zepto源码分析(二)奇淫技巧总结
Zepto源码分析(一)核心代码分析 Zepto源码分析(二)奇淫技巧总结 目录 * 前言 * 短路操作符 * 参数重载(参数个数重载) * 参数重载(参数类型重载) * CSS操作 * 获取属性值的 ...
随机推荐
- 前端学习笔记系列一:12 js中获取时间new date()的用法
获取时间: 1 var myDate = new Date();//获取系统当前时间 获取特定格式的时间: 1 myDate.getYear(); //获取当前年份(2位) 2 myDate.get ...
- GetHub上很实用的几个Demo
手机号匹配的正则表达式:https://github.com/VincentSit/ChinaMobilePhoneNumberRegex/blob/master/README-CN.md FEBS- ...
- 61 C项目------家庭收支软件
1,目标: ①模拟实现一个基于文本界面的<家庭收支软件> ②涉及知识点 局部变量和基本数据类型 循环语句 分支语句 简单的屏幕输出格式控制 2,需求说明: ①模拟实现基于文本界面的< ...
- jenkins#配置插件加速
系统管理 -> 插件管理 -> 高级 -> 升级站点 -> 填写新的url -> 提交. 新的url为:https://mirrors.tuna.tsinghua.e ...
- hashCode() 和 equals()的问题解答及重写示范
本章的内容主要解决下面几个问题: 1 equals() 的作用是什么? 2 equals() 与 == 的区别是什么? 3 hashCode() 的作用是什么? 4 hashCode() 和 equa ...
- 003.CI4框架CodeIgniter, 控制器Controllers的访问地址
01.我们新建一个System文件夹,然后创建一个Login.php类,代码如下: <?php namespace App\Controllers\System; use App\Control ...
- DStream-05 updateStateByKey函数的原理和源码
Demo updateState 可以到达将每次 word count 计算的结果进行累加. object SocketDstream { def main(args: Array[String]): ...
- P1052 卖个萌
P1052 卖个萌 转跳点:
- gpasswd命令 gpasswd -a user_name group_name
最后一句 gpasswd命令是Linux下工作组文件/etc/group和/etc/gshadow管理工具. 语法 gpasswd(选项)(参数) 选项 -a:添加用户到组: -d:从组删除用户: - ...
- jQuery原理系列-css选择器实现
jQuery最强大的功能在于它可以通过css选择器查找元素,它的源码中有一半是sizzle css选择器引擎的代码,在html5规范出来之后,增加了document.querySelector和doc ...