Neo4j Cypher语法(二)
目录
4.4 Create match return连用来返回一个关系基础
4 子句
4.1 CREATE
CREATE (//创建节点或关系
<node-name>:<label-name>
{
<Property1-name>:<Property1-Value>
........
<Propertyn-name>:<Propertyn-Value>
}
)
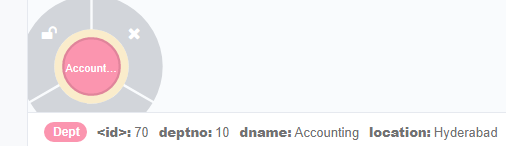
CREATE (dept:Dept { deptno:10,dname:"Accounting",location:"Hyderabad" })
4.2 MATCH
(
<node-name>:<label-name>
)
在Neo4j CQL中,我们不能单独使用MATCH或RETURN命令,因此我们应该合并这两个命令以从数据库检索数据。
Neo4j使用CQL MATCH + RETURN命令 -
检索节点的某些属性
检索节点的所有属性
检索节点和关联关系的某些属性
检索节点和关联关系的所有属性
//返回节点的部分或者全部属性
MATCH (dept: Dept)
RETURN dept.deptno,dept.dname,dept.location

//以图形式返回节点
MATCH (dept: Dept)
RETURN dept
4.3 Match
想要查询直接的连接关系,使用--> 或者<--即可
MATCH (:Person { name: 'Oliver Stone' })-->(movie)
RETURN movie.title
4.3.1 匹配一种或者多种类型的关系
在表示关系的方括号里面使用|表示或
MATCH (wallstreet { title: 'Wall Street' })<-[:ACTED_IN|:DIRECTED]-(person)
RETURN person.name
4.3.2 带有不常见字符的关系类型
若关系类型带有空格或者特殊字符,需要使用引号将它们括起来。
4.3.3 获取路径长度不确定的关系
MATCH (martin { name: 'Charlie Sheen' })-[:ACTED_IN*1..3]-(movie:Movie)
RETURN movie.title
返回具体路径:
MATCH p =(actor { name: 'Charlie Sheen' })-[:ACTED_IN*2]-(co_actor)
RETURN relationships(p)
4.3.4 与可变长路径上的属性匹配
如果需要与可变长路径上的属性匹配,对于节点来说是不好去匹配的,比较正常的思路是把需要判断的属性加到关系上,直接判断路径上的关系属性即可。
MATCH p =(charlie:Person)-[* { blocked:false }]-(martin:Person)
WHERE charlie.name = 'Charlie Sheen' AND martin.name = 'Martin Sheen'
RETURN p
4.4 Create match return连用来返回一个关系基础
注-我们将创建两个节点:
客户节点包含:ID,姓名,出生日期(dob)属性
CreditCard节点包含:id,number,cvv,expiredate属性
客户与信用卡关系:DO_SHOPPING_WITH
CreditCard到客户关系:ASSOCIATED_WITH
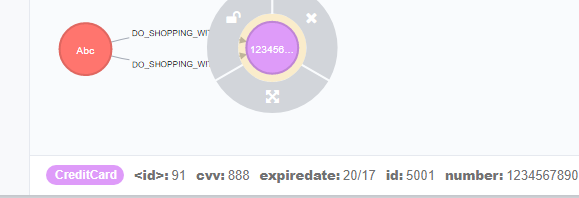
CREATE (e:Customer{id:"1001",name:"Abc",dob:"01/10/1982"})
CREATE (cc:CreditCard{id:"5001",number:"1234567890",cvv:"888",expiredate:"20/17"})
创建关系的几种方式
在以下场景中,我们可以使用Neo4j CQL CREATE命令来创建两个节点之间的关系。 这些情况适用于Uni和双向关系。
4.4.1 在两个现有节点之间创建无属性的关系
创建无属性关系的通用语法
MATCH (<node1-name>:<node1-label-name>),(<node2-name>:<node2-label-name>)
CREATE
(<node1-name>)-[<relationship-label-name>:<relationship-name>]->(<node2-name>)
RETURN <relationship-label-name>
在现有节点新建关系
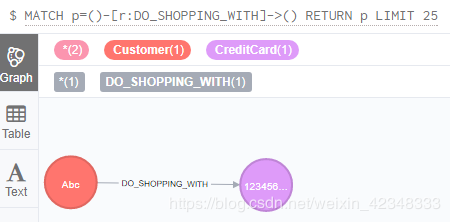
MATCH (e:Customer),(cc:CreditCard)
CREATE (e)-[r:DO_SHOPPING_WITH ]->(cc)
查看关系
MATCH p=(e)-[r:DO_SHOPPING_WITH ]->(cc)
RETURN p
4.4.2 在两个现有节点之间创建有属性的关系
MATCH (cust:Customer),(cc:CreditCard)
CREATE (cust)-[r:DO_SHOPPING_WITH{shopdate:"12/12/2014",price:55000}]->(cc)
RETURN r
4.4.3 在两个新节点之间创建无属性的关系(这种情况下节点本身也没有属性)
CREATE (fb1:FaceBookProfile1)-[like:LIKES]->(fb2:FaceBookProfile2)
4.4.4 在两个新节点之间创建有属性的关系
create(video1:YoutubeVideo1{title:"Action Movie1",updated_by:"Abc",upload_date:"10/10/2010"})-[movie:ACTION_MOVIES{rating:1}]->(video2:YoutubeVideo2{title:"Action Movie2",updated_by:"Xyz",upload_date:"12/12/2012"})
match p=(video1)-[movie:ACTION_MOVIES]->(video2) return p
4.4.5 检查关系节点的属性
MATCH (cust)-[r:DO_SHOPPING_WITH]->(cc)
RETURN cust,cc
4.4.6 其余语句
CREATE创建标签
为节点创建单个标签、多个标签,为关系创建单个标签
CREATE (m:Movie:Cinema:Film:Picture)
M是节点名,使用冒号并列创建多个标签
Where子句
用match来做匹配时,
MATCH (emp:Employee)
RETURN emp.empid,emp.name,emp.salary,emp.deptno
Where语句中的bool运算符:and、or、not、xor
比较运算符:=、<>、< 、>、<=、>=
Match类似于select 可以和where连用
MATCH (emp:Employee)
WHERE emp.name = 'Abc'
RETURN emp
使用where子句创建关系
MATCH (cust:Customer),(cc:CreditCard)
WHERE cust.id = "1001" AND cc.id= "5001"
CREATE (cust)-[r:DO_SHOPPING_WITH{shopdate:"12/12/2014",price:55000}]->(cc)
RETURN r
Delete子句
删除节点、删除节点及相关节点和关系
MATCH (e: Employee) DELETE e
删除关系 这种方式更加像删除了两种标签的所有节点和这两种标签节点的所有关系,似乎无法针对性对节点的联系做删除。
MATCH (cc: CreditCard)-[rel]-(c:Customer)
DELETE cc,c,rel
Remove
Neo4j CQL REMOVE命令用于删除节点或关系的标签、删除节点或关系的属性。Delete主要用于删除节点和关联关系,remove主要用于删除标签和属性。类似于sql中的alter。
CREATE (book:Book {id:122,title:"Neo4j Tutorial",pages:340,price:250})
删除属性
MATCH (book { id:122 })
REMOVE book.price
RETURN book
删除节点/关系的标签:
MATCH (m:Movie) RETURN m
MATCH (m:Movie)
REMOVE m:Picture
Set子句 update
向现有节点或关系添加新属性
添加或更新属性值
4.5 Optional_match
与match一致,只是对于模式不匹配的部分,optional_match会返回null,类似于SQL中的外连接。
Return *表示返回模式中定义的所有变量。
4.6 With
With可以用于链接查询语句,将上一查询语句的结果传递至下一查询语句。
主要用法有:
过滤聚合函数结果
MATCH (david { name: 'David' })--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name
David到otherperson是无向的,查询将返回与David关联且具有至少多个传出关系的人员的姓名。
在使用collect之前对结果进行排序
限制路径搜索的分支
4.7 Unwind
4.7.1 展开列表
UNWIND [1, 2, 3, NULL ] AS x
RETURN x, 'val' AS y

4.7.2 展开两个相加的列表
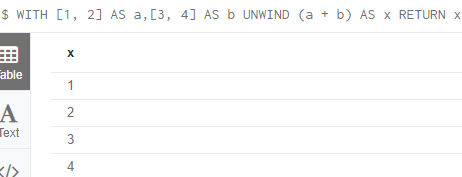
WITH [1, 2] AS a,[3, 4] AS b
UNWIND (a + b) AS x
RETURN x
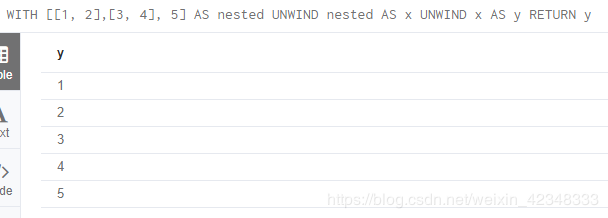
4.7.3 嵌套列表的双重展开
WITH [[1, 2],[3, 4], 5] AS nested
UNWIND nested AS x
UNWIND x AS y
RETURN y
4.8 Order by
对单个属性使用order by
MATCH (n)
RETURN n.name, n.age
ORDER BY n.name//也可以对多个属性使用order by,order by n.age,n.name
默认是按照升序排列,可以将其修改为按照降序排列
Order by n.name desc
如果需要排序的属性,在某条记录中缺失,会以null形式展现在最后一行,order by desc会展现在第一行。
4.9 Skip
从哪一行开始输出
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 3//n的名字是ABCDE,跳过前三个,则意味着输出是DE
//limit 与skip类似,限制输出的条目数。
4.10 FOREACH
Foreach子句用于更新列表中的数据,无论是路径组件或者聚合的结果。
在foreach的括号中,可以使用各种更新命令,例如 create、create unique、merge、delete、forEach。
MATCH p =(begin)-[*]->(END )
WHERE begin.name = 'A' AND END .name = 'D'
FOREACH (n IN nodes(p)| SET n.marked = TRUE )
4.11 Merge
Merge子句确保一个模式会在图中存在,无论是它已经存在或者是需要被创建。
创建单标签的单个节点
MERGE (robert:Critic)//merge能够保证节点或者关系不会被重复创建,和create unique具备类似的功能
//而且一般来说用merge更好,create unique是depreciated的用法,也许会引起不期望的bug,尤其在apoc或者Spring-Data-Neo4j里面调用Cypher语句的时候。
RETURN robert, labels(robert)
4.11.1 On create
// Merge a node and set properties if the node needs to be created.
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
RETURN keanu.name, keanu.created
// Merging nodes and setting properties on found nodes.
MERGE (person:Person)
ON MATCH SET person.found = TRUE RETURN person.name, person.found
4.11.2 On match来设置多个属性
MERGE (person:Person)
ON MATCH SET person.found = TRUE , person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
4.11.3 Merge relationships
Merge用于创建关系
MATCH (charlie:Person { name: 'Charlie Sheen' }),(wallStreet:Movie { title: 'Wall Street' })
MERGE (charlie)-[r:ACTED_IN]->(wallStreet)
RETURN charlie.name, type(r), wallStreet.title
同时创建多种关系
MATCH (oliver:Person { name: 'Oliver Stone' }),(reiner:Person { name: 'Rob Reiner' })
MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:ACTED_IN]-(reiner)
RETURN movie
4.12 Call[…YIELD]
Call调用数据库中已部署的存储过程
大多数过程都返回一组记录,其中包含一组固定的结果字段,类似于运行Cypher查询返回记录流的方式。 YIELD子子句用于显式选择将哪些可用结果字段作为新绑定变量从过程调用返回给用户,或者由剩余查询进一步处理。因此,为了能够使用YIELD,需要事先知道输出参数的名称(和类型)。可以选择使用别名(即resultFieldName AS newName)重命名每个产生的结果字段。
Neo4j也支持void过程。
Neo4j带有许多内置程序。 有关这些的列表,请参阅操作手册→内置过程。
用户还可以开发自定义过程并部署到数据库。 有关详细信息,请参见第1.2节“过程”。
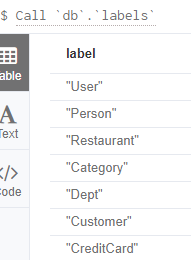
以下示例显示如何从过程调用传递参数并从中生成结果字段。 所有示例都使用以下过程:
Call `db`.`labels`
4.12.1 查看过程的签名
Call需要知道入参,yield需要知道出参。以下查询返回特定过程的签名,
CALL dbms.procedures() YIELD name, signature
WHERE name='dbms.listConfig'
RETURN signature

4.12.2 对出参进行操作
这里的YIELD用法和with类似
CALL db.labels() YIELD label
WHERE label CONTAINS 'User'
RETURN count(label) AS numLabels

4.12.3 较复杂的查询
CALL db.propertyKeys() YIELD propertyKey AS prop
MATCH (n)
WHERE n[prop] IS NOT NULL RETURN prop, count(n) AS numNodes//这里的count会根据match到的n进行分组

4.13 Create unique
Create unique是match和create的混合,会匹配它所能匹配的,会创建匹配的那一部分。
Create unique 光从字面意思就可以看得很清楚了,意味着创建唯一的节点或者说关系,而使用create来创建时,会创建多个标签、属性、完全一致的节点(内置id不同)。
感觉和merge的功能类似//确实和merge的功能类似,而且目前的版本主要是使用merge。
//如下的查询语句只会建立单一节点和单一关系,不会建立多个节点。
MERGE (p:Person {name: 'Joe'})
RETURN p
MATCH (a:Person {name: 'Joe'})
CREATE UNIQUE (a)-[r:LIKES]->(b:Person {name: 'Jill'})-[r1:EATS]->(f:Food {name: 'Margarita Pizza'})
RETURN a
MATCH (a:Person {name: 'Joe'})
CREATE UNIQUE (a)-[r:LIKES]->(b:Person {name: 'Jill'})-[r1:EATS]->(f:Food {name: 'Banana'})
RETURN a
4.14 Union
用于组合多个查询的结果
Union all仅仅是把两个结果做加合。
Union会做去重处理。
4.15 Load csv
用于从csv文件中导入数据
4.15.1 介绍
常用load csv from后面接上csv文件的URL
Csv文件支持gzip、deflate以及zip压缩文件等压缩的资源
Csv可以存储在数据库服务器上,使用file:///url来访问,也支持http、https和ftp来访问csv文件
Load csv通常与periodic commit 一起使用。
4.15.2 csv文件格式
1. 编码格式是utf-8
2. 行终止符是和系统相关的,Unix上是\n,windows上是\r\n
3. 默认的字段分隔符是,
4. 如果dbms.import.csv.legacy_quote_escaping被设置为真,那么\反斜杠可以被用作转义字符
5. 双引号必须在带引号的字符串中使用并带上转义字符\(或第二个双引号进行转义,这里的意思是使用双引号来对双引号进行转义,例如原本文件中的数据是"The ""Symbol""", 返回的数据是"The "Symbol"")。
4.15.3 从csv文件导入数据
文件格式
1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
//从外部下载对应的csv文件
LOAD CSV FROM 'https://neo4j.com/docs/cypher-manual/3.5/csv/artists.csv' AS line
CREATE (:Artist { name: line[1], year: toInteger(line[2])})
4.15.4 从包含文件头的csv文件导入对应的数据
Id,Name,Year
1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
LOAD CSV WITH HEADERS FROM 'file:///artists-with-headers.csv' AS line
CREATE (:Artist { name: line.Name, year: toInteger(line.Year)})
4.15.5 自定义分隔符的csv文件
在原本的as line后面加上FIELDTERMINATOR ';'即可
4.15.6 导入大文件
如果csv的行数接近十万行或者数百万行,则可以使用using periodic commit来指示neo4j在多行后执行提交,减少事务状态的内存开销(这种ETL的L与kettle的L类似,也是会设置多少行数据提交一次事务),默认情况下,提交将每1000行发生一次。
USING PERIODIC COMMIT// commit后面跟上数值,代表对默认的1000做的修改
LOAD CSV FROM 'https://neo4j.com/docs/cypher-manual/3.5/csv/artists.csv' AS line
CREATE (:Artist { name: line[1], year: toInteger(line[2])})
原文地址:https://blog.csdn.net/weixin_42348333/article/details/89761823
Neo4j Cypher语法(二)的更多相关文章
- Neo4j Cypher语法(三)
目录 5 函数 5.1 谓词函数 5.2 标量函数 5.3 聚合函数 5.4 列表函数 5.5 数学函数 5.6 字符串函数 5.7 Udf与用户自定义函数 6 模式 6.1 索引 6.2 限制 7 ...
- Neo4j Cypher语法(一)
目录 Cypher手册详解 1 背景 2 唯一性 3 语法 3.1 命名规则 3.2 表达式 3.3 变量与保留关键字 3.4 参数 3.5 操作符 3.6 模式 3.7 列表 Cypher手册详解 ...
- PHP语法(二):数据类型、运算符和函数
相关链接: PHP语法(一):基础和变量 PHP语法(二):数据类型.运算符和函数 PHP语法(三):控制结构(For循环/If/Switch/While) 这次整理了PHP的数据类型.运算符和函数. ...
- Python 基础语法(二)
Python 基础语法(二) --------------------------------------------接 Python 基础语法(一) ------------------------ ...
- web前端学习python之第一章_基础语法(二)
web前端学习python之第一章_基础语法(二) 前言:最近新做了一个管理系统,前端已经基本完成, 但是后端人手不足没人给我写接口,自力更生丰衣足食, 所以决定自学python自己给自己写接口哈哈哈 ...
- MySQL之单表查询 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER BY 八 限制查询的记录数:LIMIT 九 使用正则表达式查询
MySQL之单表查询 阅读目录 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER B ...
- CodeSmith 基本语法(二)
CodeSmith之四 - 典型实例(四) CodeSmith API文档 (三) CodeSmith 基本语法(二) CodeSmith 图形界面基本操作(一) CodeSmith的C#语法与Asp ...
- Pocket英语语法---二、指示代词和不定代词是什么
Pocket英语语法---二.指示代词和不定代词是什么 一.总结 一句话总结: 指示代词:标识人或事物的代词,用来代替前面已提到过的名词 this.these.that.those不定代词:指代不确定 ...
- Vue模板语法(二)
Vue模板语法(二) 样式绑定 class绑定 使用方式:v-bind:class="expression" expression的类型:字符串.数组.对象 1.2 style绑 ...
随机推荐
- php多线程的概念
来源:http://www.cnblogs.com/zhenbianshu/p/7978835.html 多线程 线程 首先说下线程: 线程(thread) 是操作系统能够进行运算调度的最小单位.它被 ...
- C#剪切生成高质量缩放图片
/// <summary> /// 高质量缩放图片 /// </summary> /// <param name="OriginFilePath"&g ...
- leetcode84 柱状图
O(n^2) time 应用heights[r]<=heights[r+1]剪枝: class Solution { public: int largestRectangleArea(vecto ...
- python 生成词云
1.知识点 """ WordCloud参数讲解: font_path表示用到字体的路径 width和height表示画布的宽和高 prefer_horizontal可以调 ...
- 史上最全最详细JNDI数据源配置说明
转: 史上最全最详细JNDI数据源配置说明 2017年08月05日 17:12:08 万米高空 阅读数 23983 版权声明:本文为博主原创文章,转载请注明出处,尊重劳动成果,谢谢~ https: ...
- Hibernate 的一些注解配置
网上参考资料很多,但总是不符合自身习惯,遂记录下来. 一对多的关系 如class与student的关系 class中 @OneToMany(mappedBy = "class") ...
- Scala中的列表可以添加元素吗?
列表或许是Scala程序中最常用到的数据结构了,其与数组非常相似,最重要的两点差别为: 1.列表是不可变的: 2.列表具有递归结构,而数组是连续的. 在实际使用中非常容易这样用: val a = Li ...
- [ZT]Enhancement-01
Enhancement(1)--BTEs 最近一个同事碰到一个FI的增强,要用BTEs实现,我也是第一次接触到这种增强,所以跟着他一起做了一下.写一个这方面的小节. BTEs(Business ...
- Spring策略模式的实现
场景: 有时候一个业务方法有多个实现类,需要根据特定的情形进行业务处理. 例如:商店支付,我们可以使用支付宝.微信扫描农行.xxx行的快捷支付(而不是微信支付.支付宝支付二维码)购买商品. 实现代码( ...
- 一个提高照片质量的网站和一个改变照片DPI的方法
相信很多童鞋都有遇到过,碰到一张很喜欢的图片,想用来做背景什么的,蛋似--因为画质太AV了怕引起误会,所以不敢使用!很气--!! 这时大神就会跳出来说,画质不好?PS是用来吃si的么! 我:我才不会用 ...