Hadoop_03_Hadoop分布式集群搭建
一:Hadoop集群简介:
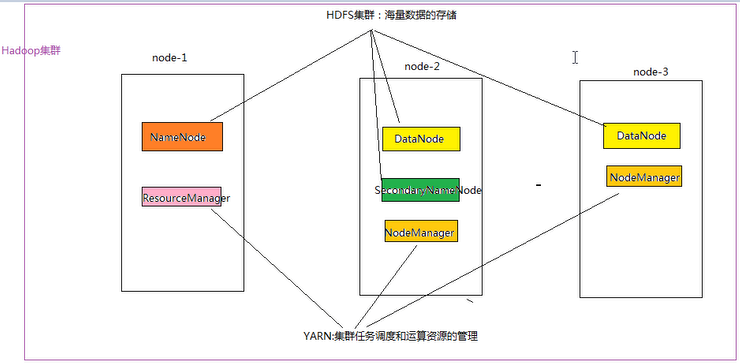
Hadoop 集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起;
HDFS集群:负责海量数据的存储,集群中的角色主要有: NameNode、DataNode、SecondaryNameNode;
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有: ResourceManager、NodeManager;
那么 Mapreduce 是什么呢:它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,
然后打包运行在 HDFS 集群上,并受到 YARN 集群的资源调度管理,由 YARN 为Mapreduce 程序分配运算硬件资源;
二:Hadoop集群部署:
Hadoop包含HDFS集群和YARN集群。部署Hadoop就是部署HDFS和YARN集群
Hadoop部署方式分为三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster rmode
(群集模式),其中前两种都是在单机部署
1. 独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试
2. 伪分布模式也是在1个机器上运行 HDFS 的NameNode和DataNode、YARN的ResourceManger和NodeManager,但分别启
动单独的java进程,主要用于调试
3. 集群模式主要用于生产坏境部署,会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在
不同的机器上
4. 本集群搭建案例,以4节点为例进行搭建,角色分配如下:
| 主机名 | IP | 角色 |
|---|---|---|
| shizhan2 | 192.168.232.201 | Name Node:9000 Resource Manager |
| shizhan3 | 192.168.232.205 | Data Node Node Manager |
| shizhan5 | 192.168.232.207 | Data Node Node Manager |
| shizhan6 | 192.168.232.208 | Data Node Node Manager |
示例图:
三:Hadoop集群安装:
1.上传安装文件到虚拟机:我使用FTP传输
2.解压文件到指定目录: tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C /usr/local/src/
3.修改配置文件:
3.1.hadoop-env.sh:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hadoop-env.sh
然后配置JAVA_HOME,可以先用echo $JAVA_HOME命令取得JAVA_HOME的位置:/usr/java/jdk1.7.0_45
export JAVA_HOME=/usr/java/jdk1.7.0_45
3.2.core-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/core-site.xml
<configuration>
<!-- 指定 Hadoop 所使用的文件系统schema(URI),HDFS的老大(NameNode:为客户提供服务,首先被访问)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://shizhan2:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
</configuration>
3.3.hdfs-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.4.mapred-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/mapred-site.xml.template
mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> //不填写默认local
</property>
</configuration>
3.5.yarn-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>shizhan2</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.将Hadoop拷贝到其他虚拟机:
scp -r /usr/local/src/hadoop-2.6.4 shizhan3:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.4 shizhan5:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.4 shizhan6:/usr/local/src/
5.将hadoop添加到环境变量:
vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/usr/local/src/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
6.格式化 HDFS文件系统:(对namenode进行初始化,生成相应目录)
首先把Hadoop配置到环境变量里面去,然后执行命令:hdfs namenode -format (hadoop namenode -format)
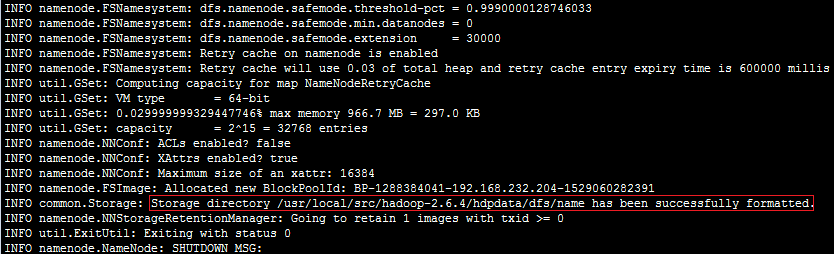
创建了NameNode的工作目录
7.修改NameNode中的slaves配置(供自动化启动脚本使用):vi /usr/local/src/hadoop-2.6.4/etc/hadoop/slaves
shizhan3
shizhan5
shizhan6
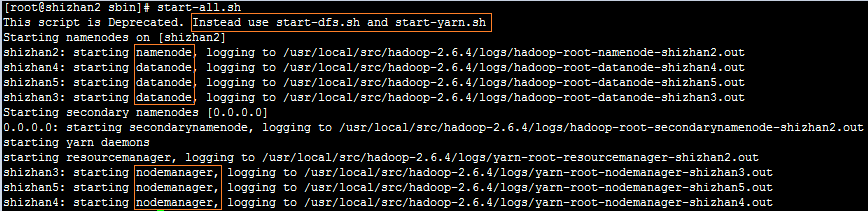
8.在NameNode节点上启动Hadoop:Hadoop/sbin/start-all.sh(先启动HDFS再启动YARN)
分开进行启动:先启动HDFS:sbin/start-dfs.sh ,再启动YARN:sbin/start-yarn.sh
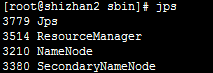
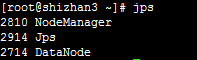
然后在NameNode上运行jps命令,应该包含下面的结果:
在其他节点上运行jps命令,应该包含下面的结果:
四:配置ssh免登陆:
1.ssh-keygen -t rsa(四个回车),执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
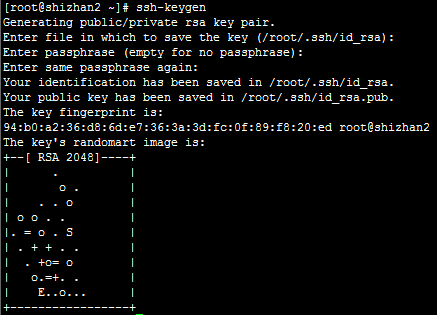
2.将公钥拷贝到要免密登陆的目标机器上:ssh-copy-id shizhan2/shizhan3/shizhan5/shizhan6
五:验证是否启动成功:
HDFS管理界面:访问http://shizhan2:50070,可以看到如下图所示的结果:

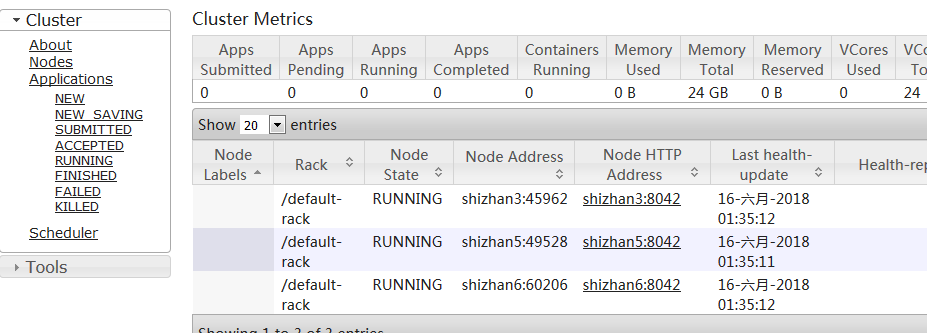
YARN管理界面,访问http://shizhan2:8088,可以看到如下图所示的结果:
五:出现的问题:
Hadoop dataNode正常启动,但是live Nodes中确缺少节点:
解决方案:修改vi /usr/local/src/hadoop-2.6.4/etc/hadoop/core-site.xml配置文件
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
之前因为配置的数据存放路径相同,所以报告中认为只有一个DataNode,所以在Web控制台dataNodes数目显示不全;
Hadoop_03_Hadoop分布式集群搭建的更多相关文章
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- kafka系列二:多节点分布式集群搭建
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安 ...
- MinIO 分布式集群搭建
MinIO 分布式集群搭建 分布式 Minio 可以让你将多块硬盘(甚至在不同的机器上)组成一个对象存储服务.由于硬盘分布在不同的节点上,分布式 Minio 避免了单点故障. Minio 分布式模式可 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
随机推荐
- JavaScript(6)—— 返回特征数字
案例要求 根据业务情况,要把核心的东西变成一个模块便于复用,慢慢沉淀后,能够更快更高效地编程. 业务核心算法: /* 数字检测 @return 返回2,能被3和7整除 返回1,能够被3整除 返回0,不 ...
- .Netcore 2.0 Ocelot Api网关教程(3)- 路由聚合
在实际的应用当中,经常会遇到同一个操作要请求多个api来执行.这里先假设一个应用场景:通过姓名获取一个人的个人信息(性别.年龄),而获取每种个人信息都要调用不同的api,难道要依次调用吗?在Ocelo ...
- 20190526 - CentOS 7 中 安装 MySQL 8 并授权 root 远程访问
1. CentOS 7 中 安装 MySQL 8 CentOS 7 中内置 MariaDB 建议升级一下用,性能好很多.但如果一定要用 MySQL 8,就得自己装. 坦白的说,Oracle 升级 My ...
- Python3 Selenium自动化web测试 ==> 第七节 WebDriver高级应用 -- 浮动框中,单击选择某个关键字选项
学习目的: 了解WebDriver的高级应用 正式步骤: 测试Python3代码 # -*- coding:utf-8 -*- from selenium import webdriver from ...
- kubernetes的namespaces总是Terminating
0.尝试强制删除不行 删除时带上–force --grace-period=0参数 ,无法删除:kubectl delete namespace rook-ceph --force --grace-p ...
- Apache——开启个人用户主页功能
个人主页功能分为不加密和加密两种 不加密: 先来建立几个用户,我这是建了两个 例:命令为:useradd qiyuan 然后输入:passwd qiyuan,改一下密码 我们看一下家目录下面: 已经 ...
- [Comet OJ - Contest #6 C][48C 2279]一道树题_树
一道树题 题目大意: 给定一棵树,边的编号为读入顺序.现在规定,区间$[L, R]$的贡献$S(L,R)$为把编号在该区间里的边都连上后,当前形成的森林中点数大于等于$2$的联通块个数. 求$\sum ...
- vsftpd下载文件时内容乱码
windows客户端访问Linux服务端的ftp并下载文档时,内容会出现乱码,这是由于vsftpd文件服务器不支持转码功能 通过java FTPClient下载 方法为 OutputStream is ...
- sysbench压力测试工具简介
一.sysbench压力测试工具简介: sysbench是一个开源的.模块化的.跨平台的多线程性能测试工具,可以用来进行CPU.内存.磁盘I/O.线程.数据库的性能测试.目前支持的数据库有MySQL. ...
- better-scroll踩坑合集
better-scroll踩坑合集:https://www.jianshu.com/p/6338a8033281