ElasticSearch工作原理与优化
elasticsearch设计的理念就是分布式搜索引擎,底层其实还是基于lucene的,通过倒排索引的方式快速查询。比如一本书的目录是索引,然后快速找到每一章的的文本内容这种叫正向索引;而如果一件衣服比如有:蓝色,389元,L码这些信息,我们通过搜索这些信息就能找到这条记录,这就叫倒排索引,实际就是通过分词、重组、来共享前缀存储索引。
倒排索引
比如有5条数据,左边是id右边是名称,我要查询名字包含james的记录,就需要把所有记录遍历一遍才行。
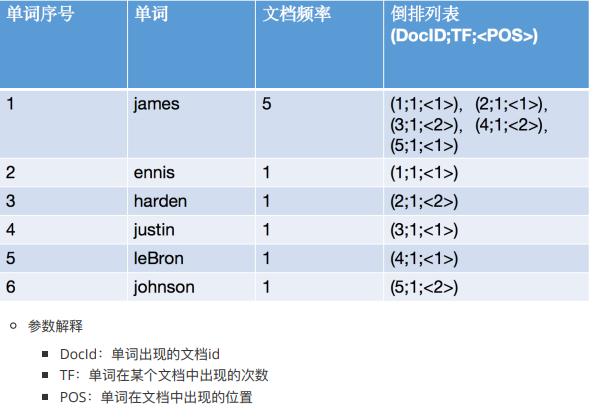
如果我们把名字进行分词,然后对这些分词进行分组,统计它所在的文档位置就好了。倒排索引会记录每个分词锁出现的次数,以及这些分词存在于那些doc中等等一系列信息。
es中存储数据的基本单位是索引,比如说你现在要在es中存储一些订单数据,你就应该在es中创建一个索引,order_idx,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是mysql里的数据库。index -> type -> mapping -> document -> field。
index:mysql数据库
type:就像一张表。ES5.X中一个index可以有多个type、
ES6.X中一个type只能有一个type、
ES7.X中移除了type这个概念,此时的index就像一张表了。
mapping:定义了每个字段的类型等信息。相当于关系型数据库中的表结构。
document:一条document就代表了mysql表里的一条记录。
field:每个field就代表了这个document中的一个字段的值。
ES如何实现分布式的(es架构原理)
创建一个索引,这个索引可以拆分成多个shard,每个shard存储部分数据。每个shard的数据实际是有多个备份,就是说每个shard都有一个主分片写数据、还有一个或多个副分片同步数据(主副并不在一个服务上),es集群多个节点会自动选一个为master节点,这个节点其实就是干一些管理的工作的,比如维护索引元数据拉,负责切换 主/副节点 的身份之类的;如果一个节点的主分片挂了,副分片会切换为主分片,一个主分片及其所有副分片都挂了,集群就崩塌了。一个集群中会有以下几个角色:
集群(cluster)
集群由一个或多个节点组成,一个集群有一个默认名称"elasticsearch"。
节点(node)
一个Elasticsearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例应该会部署在不同的机器上。Elasticsearch 的配置文件中可以通过 node.master、node.data 来设置节点类型。node.master:表示节点是有资格竞选为主节点的资格。node.data:表示节点是否存储数据。
主节点+数据节点:即有成为主节点的资格,又存储数据
node.master: true
node.data: tru
数据节点:节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true
客户端节点:不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进⾏负载均衡
node.master: false
node.data: false
分片和副本(shard)
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片( primary shard)和副分片(replica shard),副分片是主分片的拷贝。默认每个主分片有一个副分片,一个索引的副分片的数量可以动态地调整,副分片从不与它的主分片在同一个节点上。
ES 读/写 数据过程
写入文档
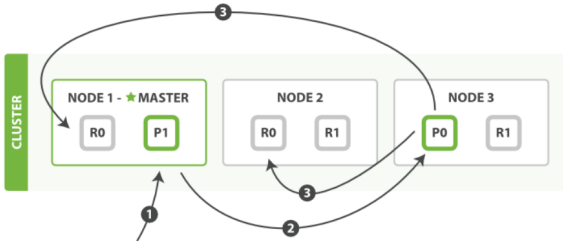
1. 客户端向任意一个节点发送新增文档请求,比如node1(此时node1就成了协调节点)。
2. 节点对这个document进行路由,发现这个document属于主分片P0,因为P0在node3上,所以请求会转发到node3.
3. document在P0上新增成功后,会转发到node1、node2上的副分片R0 R1。
4. node1发现他们都搞定之后,就会将结果响应给客户端。
读取文档
1. 客户端向任意一个节点发送读请求,比如node2(此时node2就成了协调节点)。
2. node2对document进行路由,将请求转发到对应的node,比如node1。
3. 此时会使用round-robin随机轮询算法,然后对其所有主副节点随机选择一个,让读请求负载均衡。
4. node1处理完成之后将结果给node2,node2将结果响应给客户端。
路由算法
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing默认是文档的id,也可以自定义,hash(routing)后得到一个数字,再对主分片个数取余,这个数字肯定是0~number_of_primary_shards-1 之间的余数,就是我们文档所在的位置。所以我们在创建索引的时候就要确定好主分片个数,并永远不修改,否则就找不到之前的数据了。
es大量数据(数十亿级别)时,如何提高查询效率
1. filesystem cache
往es写入数据时,其实就是写入到磁盘中的。而es的搜索引擎底层是严重依赖于文件系统缓存的,es所有的indx segment file索引数据文件就存在这里面,如果filesystem cache的内存够大,那么你搜索的时候基本就是走内存的,性能会很高。打个比方说:
es节点有3台机器,每台机器,看起来内存很多,64G,总内存,64 * 3 = 192g;每台机器给es jvm heap是32G,那么剩下来留给filesystem cache的就是每台机器才32g,总共集群里给filesystem cache的就是32 * 3 = 96g内存。如果有1T的数据量,那就只有10%的索引文件被存到file cache里面去,效率肯定是比较低的,就是你的机器的内存,至少可以容纳你的总数据量的一半。
2. 数据预热/冷热分离
预热:比如file cache有50g内存,而数据超过了100g怎么办呢?我们可以做一个后台系统定时去拉取一些容易被人访问的数据。因为我们查询es时,它会重新记录这个索引的信息、进行排序将这些数据放到file cache中。
冷热分离:大量不搜索的字段拆到别的index里面去,就有点像mysql的垂直拆分,这样可以确保热数据在被预热之后,尽量都让他们留在filesystem os cache里,别让冷数据给冲刷掉。热数据可能就占总数据量的10%,此时数据量很少,几乎全都保留在filesystem cache里面了,就可以确保热数据的访问性能是很高的。
3. document模型设计
es里面的复杂的关联查询,复杂的查询语法,尽量别用,一旦用了性能一般都不太好。有关联的最好写入es的时候,搞成两个索引,order索引,orderItem索引,order索引里面就包含id order_code total_price;orderItem索引直接包含id order_code total_price id order_id goods_id purchase_count price,这样就不需要es的语法来完成join了。
4. 分页性能优化
es的分页是较坑的,假如你每页是10条数据,你现在要查询第100页,实际上是会把每个shard上存储的前1000条数据都查到一个协调节点上,如果你有个5个shard,那么就有5000条数据,接着协调节点对这5000条数据进行一些合并、处理,再获取到最终第100页的10条数据。翻页的时候,翻的越深,每个shard返回的数据就越多,而且协调节点处理的时间越长。非常坑爹。所以用es做分页的时候,你会发现越翻到后面,就越是慢。有2个折中的优化方案:
1 不允许分页,直接把数据给客户端(这么说估计会被打)。
2 允许一页页的翻但是不允许选择页数,就像app的推荐商品一样。用scroll api一页页去刷,scroll的原理实际上是保留一个数据快照,然后在一定时间内,你如果不断的滑动往后翻页的时候,类似于你现在在浏览微博,不断往下刷新翻页。那么就用scroll不断通过游标获取下一页数据,这个性能是很高的,比es实际翻页要好的多的多。
ElasticSearch工作原理与优化的更多相关文章
- Elasticsearch工作原理
一.关于搜索引擎 各位知道,搜索程序一般由索引链及搜索组件组成. 索引链功能的实现需要按照几个独立的步骤依次完成:检索原始内容.根据原始内容来创建对应的文档.对创建的文档进行索引. 搜索组件用于接收用 ...
- MySQL/MariaDB数据库的索引工作原理和优化
MySQL/MariaDB数据库的索引工作原理和优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 实际工作中索引这个技术是影响服务器性能一个非常重要的指标,因此我们得花时间去了 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- memcached工作原理与优化建议
申明,本文为转载文:http://my.oschina.net/liuxd/blog/63129 工作原理 基本概念:slab,page,chunk. slab,是一个逻辑概念.它是在启动memcac ...
- Nginx工作原理和优化、漏洞
1. Nginx的模块与工作原理 第三方模块:HTTP Upstream Request Hash模块.Notice模块和HTTP Access Key模块. 图1-1展示了Nginx模块常规的HT ...
- Nginx 工作原理和优化、漏洞
1. Nginx的模块与工作原理 Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(locat ...
- Nginx工作原理和优化、漏洞(转)
查看安装了哪些模块命令: [root@RG-PowerCache-X xcache]# nginx/sbin/nginx -Vnginx version: nginx/1.2.3built by gc ...
- 【转载】Nginx 的工作原理 和优化
1. Nginx的模块与工作原理 Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(locati ...
- ElasticSearch 工作原理
ElasticSearch 工作原理图 文字说明,以后更新
随机推荐
- kafka 性能测试脚本
[参考文章]:Kafka自带的性能测试脚本 1. 生产消息压测脚本 1.1 脚本及参数 bin/kafka-producer-perf-test.sh --topic kafka-test-0 -- ...
- 微信小程序支持windows PC版了
微信 PC 版新版本中,支持打开聊天中分享的小程序,开发者可下载安装微信 PC 版内测版本进行体验和适配.最新版微信开发者工具新增支持在微信 PC 版中预览小程序 查看详情 微信 PC 版内测版下载地 ...
- 【南工程开源计划】南京工程学院 信息与通信工程学院 课程设计说明书(论文) 宽带接入技术--WLAN接入设计
文章目录 蓝奏云文件存放地址 一.课程设计目的 二.课程设计要求 三.课程设计网络环境 四.课程设计内容 4.1 WLAN接入设计 4.1.1设计拓扑 4.1.2设计原理 1)WLAN 2)RADIU ...
- __declspec(dllexport)的使用
1. 用法 在 VS 的“预编译”选项里定义_EXPORTING宏 #ifdef _EXPORTING #define API_DECLSPEC __declspec(dllexport) #else ...
- 3709: [PA2014]Bohater
3709: [PA2014]Bohater 或者:Bohater 题解 好狠啊这个题 z 要开 long long ,可能算掉血回血的时候会爆 long long 吧 首先把能回血的怪打死(不然你后面 ...
- layui 表单遇到的小问题
select中的option 居中显示 /*select显示的option居中*/ /*.layui-select-title input{ text-align: center; }*/ /*opt ...
- linux命令行下常用快捷键
快捷键的使用: ctrl+d或者使用logout.exit退出终端ctrl+a跳到开始ctrl+e跳到最后ctrl+u向前删除ctrl+k向后删除ctrl+c中断命令ctrl+z暂停命令 fg:将暂停 ...
- linux/windows/Mac平台生成随机数的不同方法
linux平台,使用rand.Seed() //rand_linux.go package main import ( "math/rand" "time" ) ...
- 五十九:Flask.Cookie之flask设置cookie过期时间
设置cookie有效期1.max_age:距离现在多少秒后过期,在IE8以下不支持2.expires:datatime类型,使用此参数,需参照格林尼治时间,即北京时间-8个小时3.如果max_age和 ...
- java文件夹上传下载控件分享
用过浏览器的开发人员都对大文件上传与下载比较困扰,之前遇到了一个需要在JAVA.MyEclipse环境下大文件上传的问题,无奈之下自己开发了一套文件上传控件,在这里分享一下.希望能对你有所帮助. 以下 ...