efk
第一步 三台虚拟机做zookeeper
1.安装jdk环境
2.测试环境
[root@localhost ~]# java -version
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
3.安装 zookeeper
tar -zxvf zookeeper-3.4.14.tar.gz
5. 创建两个目录后面要用
6. 编辑zookeeper配置文件
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
执行 :g/^#/d 删除说有注释行

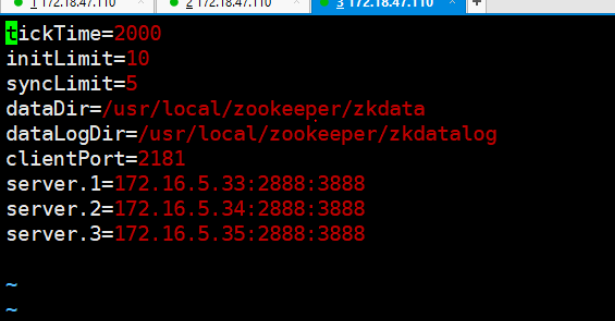
7.给三个zkdata 分别不同的东西
echo '1'>/usr/local/zookeeper/zkdata/myid echo '2'>/usr/local/zookeeper/zkdata/myid echo '3'>/usr/local/zookeeper/zkdata/myid
8.启动 检测 成不成功 先关闭防火墙 和selinux
./zkServer.sh start
[root@kafka03 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader
第二部 三台虚拟主机 安装Kafka
1.安装 kafka
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.0/kafka_2.11-2.2.0.tgz
tar -zxvf zookeeper-3.4.14.tar.gz
mv zookeeper-3.4.14 /usr/local/kafka
2.编辑配置文件
[root@kafka03 bin]# cd /usr/local/kafka/config
[root@kafka03 config]# vim server.properties
第一台 :



第二台
broker.id=2
advertised.listeners=PLAINTEXT://kafka02:9092
zookeeper.connect=192.168.202.131:2181,192.168.202.132:2181,192.168.202.133:2181
第三台
broker.id=3
advertised.listeners=PLAINTEXT://kafka03:9092
zookeeper.connect=192.168.202.131:2181,192.168.202.132:2181,192.168.202.133:2181
3. vim /etc/hosts
192.168.202.131 kafka01
192.168.202.132 kafka02
192.168.202.133 kafka03
9 如果要收集nginx的日志 需要配置yum源
[root@localhost yum.repos.d]# cd /etc/yum.repos.d
[root@localhost yum.repos.d]# vim filebeat.repo [filebeat-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
10 安装filebeat
[root@localhost yum.repos.d]# yum -y install filebeat
11 编辑filebeat的配置文件
efk的更多相关文章
- 从ELK到EFK演进
背景 作为中国最大的在线教育站点,目前沪江日志服务的用户包含网校,交易,金融,CCTalk 等多个部门的多个产品的日志搜索分析业务,每日产生的各类日志有好十几种,每天处理约10亿条(1TB)日志,热数 ...
- OpenShift实战(六):OpenShift日志监控EFK
1.镜像下载 为了防止安装过程中由于镜像下载缓慢导致自动部署失败,所以首先提前下载好EFK镜像. docker pull openshift/origin-logging-fluentd docker ...
- 单机安装EFK(一)
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-install.html#ge ...
- docker+efk+.net core部署
部署环境 centos7 本主要利用efk实现日志收集 一.创建docker-compose es地址:https://www.elastic.co/guide/en/elasticsearch/re ...
- 从 ELK 到 EFK 的演进
背景 作为中国最大的在线教育站点,目前沪江日志服务的用户包含网校,交易,金融,CCTalk 等多个部门的多个产品的日志搜索分析业务,每日产生的各类日志有好十几种,每天处理约10亿条(1TB)日志,热数 ...
- 12-部署EFK插件
配置和安装 EFK 官方文件目录:cluster/addons/fluentd-elasticsearch $ ls *.yaml es-controller.yaml es-service.yaml ...
- docker-compose 部署 EFK
信息: Docker版本($ docker --version):Docker版本18.06.1-ce,版本e68fc7a 系统信息($ cat /etc/centos-release):CentOS ...
- EFK收集Kubernetes应用日志
本节内容: EFK介绍 安装配置EFK 配置efk-rbac.yaml文件 配置 es-controller.yaml 配置 es-service.yaml 配置 fluentd-es-ds.yaml ...
- 从ELK到EFK
https://my.oschina.net/itshare/blog/775466 http://blog.51cto.com/467754239/1700828 日志系统 日志就是程序产生的,遵循 ...
- EFK Stack容器部署
基础环境 安装docker # curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/intern ...
随机推荐
- JS---DOM---点击操作---part1---20个案例
点击操作:------>事件: 就是一件事, 有触发和响应, 事件源 按钮被点击,弹出对话框 按钮---->事件源 点击---->事件名字 被点了--->触发了 弹框了---& ...
- JavaScript设计模式基础(二)
JavaScript 设计模式基础(一) 原型模式 在以类为中心的面向对象编程语言中,类和对象的关系就像铸模和铸件的关系,对象总是从类中创建.而原型编程中,类不是必须的,对象未必从类中创建而来,可以拷 ...
- jQuery淡入淡出轮播图实现
大家好我是 只是个单纯的小白,这是人生第一次写博客,准备写的内容是Jquery淡入淡出轮播图实现,在此之前学习JS写的轮播图效果都感觉不怎么好,学习了jQuery里的淡入淡出效果后又写了一次轮播图效果 ...
- Android RecyclerView SearchView基本用法1
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/82 背景: 做了很多年的app开发,貌似没见过没有搜索功能 ...
- Android几种多渠道打包
1.什么是多渠道打包 在不同的应用市场可能有不同的统计需求,需要为每个应用市场发布一个安装包,这里就引出了Android的多渠道打包.在安装包中添加不同的标识,以此区分各个渠道,方便统计app在市场的 ...
- oracle 查询两个字段值相同的记录
select A.* from tb_mend_enrol A, (select A.Typeid, A.address from tb_mend_enrol A group by A.Typeid, ...
- python与数据库交互的模块pymysql
一.Mysql 1.前提 pip install pymysql import pymysql 2.详情 Connection对象 =====>用于连接数据库 用于建立与数据库的连接 创建对象: ...
- 21.决策树(ID3/C4.5/CART)
总览 算法 功能 树结构 特征选择 连续值处理 缺失值处理 剪枝 ID3 分类 多叉树 信息增益 不支持 不支持 不支持 C4.5 分类 多叉树 信息增益比 支持 ...
- [C]表达式结合规律和运算符优先级
表达式结合规律 如果运算符具有相同的优先级(precedence)有些表达式的结合方式是从左往右,有些则是从右往左结合的(例如赋值运算符): 表达式 结合律 组合方式 a/b%c 从左往右 (a/b) ...
- [译]Vulkan教程(25)描述符布局和buffer
[译]Vulkan教程(25)描述符布局和buffer Descriptor layout and buffer 描述符布局和buffer Introduction 入门 We're now able ...