[NLP] 相对位置编码(一) Relative Position Representatitons (RPR) - Transformer
对于Transformer模型的positional encoding,最初在Attention is all you need的文章中提出的是进行绝对位置编码,之后Shaw在2018年的文章中提出了相对位置编码,就是本篇blog所介绍的算法RPR;2019年的Transformer-XL针对其segment的特定,引入了全局偏置信息,改进了相对位置编码的算法,在相对位置编码(二)的blog中介绍。
本文参考链接:
1. Self-Attention with Relative Position Representations (Shaw et al.2018): https://arxiv.org/pdf/1803.02155.pdf
2. Attention is all you need (Vaswani et al.2017): https://arxiv.org/pdf/1706.03762.pdf
3. How Self-Attention with Relative Position Representations works: https://medium.com/@_init_/how-self-attention-with-relative-position-representations-works-28173b8c245a
4. [NLP] 相对位置编码(二) Relative Positional Encodings - Transformer-XL: https://www.cnblogs.com/shiyublog/p/11236212.html
Motivation
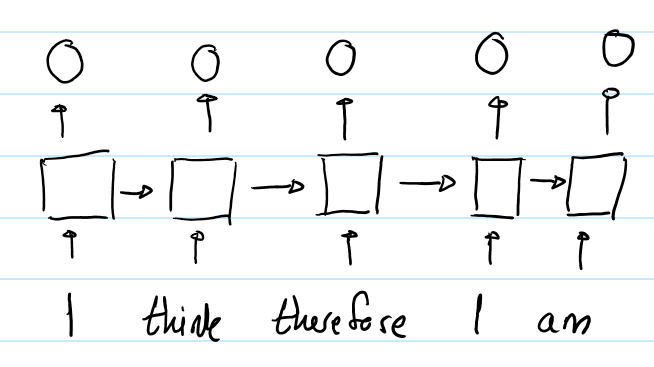
RNN中,第一个"I"与第二个"I"的输出表征不同,因为用于生成这两个单词的hidden states是不同的。对于第一个"I",其hidden state是初始化的状态;对于第二个"I",其hidden state是编码了"I think therefore"的hidden state。所以RNN的hidden state 保证了在同一个输入序列中,不同位置的同样的单词的output representation是不同的。
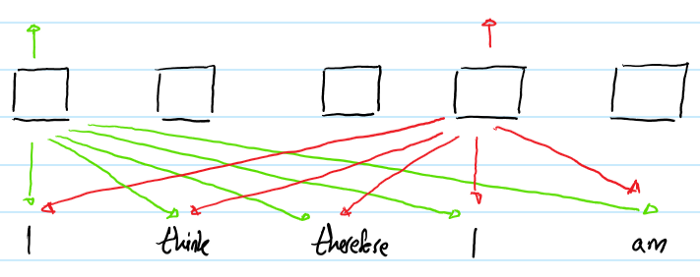
在self-attention中,第一个"I"与第二个"I"的输出将完全相同。因为它们用于产生输出的“input”是完全相同的。即在同一个输入序列中,不同位置的相同的单词的output representation完全相同,这样就不能提现单词之间的时序关系。--所以要对单词的时序位置进行编码表征。
概述
作者提出了在Transformer模型中加入可训练的embedding编码,使得output representatino可以表征inputs的时序信息。这些embedding vectors是 在计算输入序列中的任意两个单词$i, j$ 之间的attention weight 和 value时被加入到其中。embedding vector用于表示单词$i,j$之间的距离(即为间隔的单词数),所以命名为"相对位置表征" (Relative Position Representation) (RPR)
比如一个长度为5的序列,需要学习9个embeddings。(1个表示当前单词,4个表示其左边的单词,4个表示其右边的单词。)

以下例子展示了这些embeddings的用法:
1)
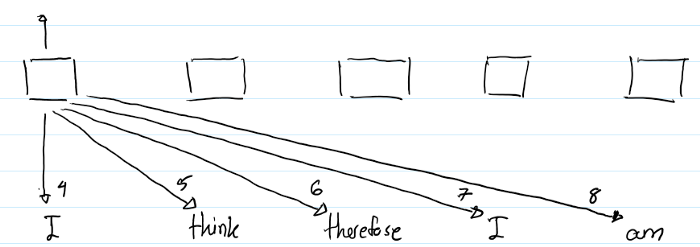
以上图示显示了计算第一个"I"的output representation的过程。箭头下面的数字显示了计算attention时用到的哪个RPRs.(比如,本示例是求第一个“I”的输出,需要用第一个“I”,记为''I_1',与sequence中每一个单词两两做self-attention运算。'I_1' with 'I_1'用到 index = 4 的RPR,“I_1”with 'think'用到index = 5 的RPR--因为是右边第一个, 'I_1' with 'therefore' 用到index = 6的RPR--因为是右边第二个... )
2)
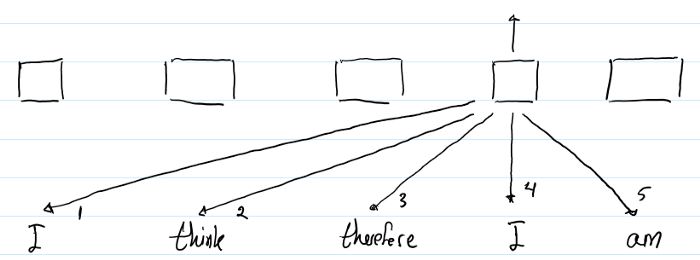
与(1)同理。
符号含义

两点需要注意:
1. 有2个RPR的表征。需要在计算$z_i$和$e_{ij}$时分别引入对应的RPR的embedding。计算$z_i$时对应的RPR vector 是$a_{ij}^V$, 计算$e_{ij}时引入的RPR vector$是$a_{ij}^K$. 不同于在做multi-head attention时引入的线性映射矩阵W——对于每个head都不同;这个RPR embedding 在同一层的attention heads之间共享,但是在不同层的RPR可能不同。
2. 最大单词数被clipped在一个绝对的值k以内。向左k个, 再左边均为0, 向右k个,再右边均为k, 所表示的index范围: 2k + 1.
eg. 10 words, k = 3, RPR embedding lookup table
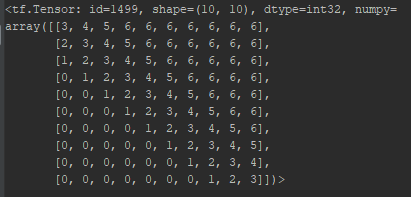
设置k值截断的意义:
1. 作者假设精确的相对位置编码在超出了一定距离之后是没有必要的
2. 截断最大距离使得模型的泛化效果好,可以更好的Generalize到没有在训练阶段出现过的序列长度上。
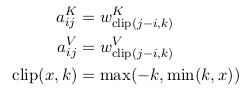
之后,将分别学习key, value的相对位置表征。
$$w^{K} = (w_{-k}^K, ..., w_{k} ^K), w^{V} = (w_{-k}^V, ..., w_{k} ^V)$$
其中$w_i^K, w_i^V \in \mathbb{R}^{d_a}$.
实现
1. 若不使用RPR, 计算$z_i$的过程:

2. 若使用RPR,计算$z_i$的过程:
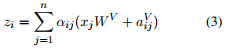
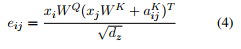
(3) 表示在计算word i 的output representation时,对于word j的value vector进行了修改,加上了word i, j 之间的相对位置编码。
(4) 在计算query(i), key(j)的点积时,对key vector进行了修改,加上了word i, j 之间的相对位置编码。
这里用加法引入RPR的信息,是一种高效的实现方式。
高效实现
不加RPR时,Transformer计算$e_{ij}$使用了 batch_size * h 个并行的矩阵乘法运算。
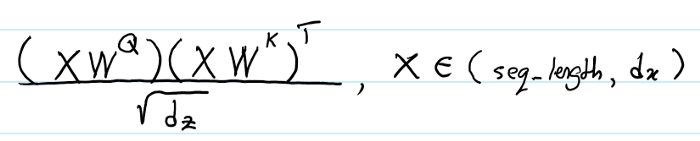
其中的x是给定input sequence后的(row-wise)
将(4) 式写为以下形式:
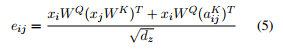
(1) 首先看第一项,$$x_iW^Q(x_jW^K)^T$$
首先看对于一个batch,的一个head, 其中$x_i$的shape是(seq_length, dx),现在假设seq_length = 1,来简化推导过程。假设$W^Q, W^K$的shape均为(dx, dz),那么第一项运算后的shape为:[(1 * dx) * (dx, dz)] * [(dz, dx) * (dx, 1)] = (1, 1),
这是对于一个batch,一个head, seq_length = 1的情况,那么扩充到真实的情况,其shape 为: (batch_size, h, seq_length, seq_length)
所以我们的目标是产生另一个有相同shape的tensor,其内容是word i 与关于Wordi, j 的RPR的embedding的点积。
(2) A.shape: (seq_length, seq_length, d_a),
$transpose \rightarrow A^T.shape: $(seq_length, d_a, seq_length)
(3) 第二项中的$x_i W^Q.shape:$ (batch_size, h, seq_length, d_z)
$transpose \rightarrow $ (seq_length, batch_size, h, d_z)
$reshape \rightarrow $ (seq_length, batch_size * h, d_z)
之后可以与$A^T$相乘,可以看做是seq_length个并行的(batch_size * h, d_z) matmul (d_a, seq_length),因为$d_z = d_a$,所以每个并行的运算结果是:(batch_size * h, seq_length), 总的大矩阵的shape: (seq_length, batchsize * h, seq_length).
$reshape \rightarrow $(seq_length, batch_size, h, seq_length)
$transpose \rightarrow$ (batch_size, h, seq_length, seq_length)
与第一项的shape一致,可以相加。
(3)式的推导同理。
下面给出tensor2tensor中对于相对位置编码的代码:https://github.com/tensorflow/tensor2tensor/blob/9e0a894034d8090892c238df1bd9bd3180c2b9a3/tensor2tensor/layers/common_attention.py#L1556-L1587
其中x,对应上面推导中的$x_i * W^Q$, y对应上面推导中的$x_j * W^K$, z对应上面的a。
def _relative_attention_inner(x, y, z, transpose):
"""Relative position-aware dot-product attention inner calculation.
This batches matrix multiply calculations to avoid unnecessary broadcasting.
Args:
x: Tensor with shape [batch_size, heads, length or 1, length or depth].
y: Tensor with shape [batch_size, heads, length or 1, depth].
z: Tensor with shape [length or 1, length, depth].
transpose: Whether to transpose inner matrices of y and z. Should be true if
last dimension of x is depth, not length.
Returns:
A Tensor with shape [batch_size, heads, length, length or depth].
"""
batch_size = tf.shape(x)[0]
heads = x.get_shape().as_list()[1]
length = tf.shape(x)[2] # xy_matmul is [batch_size, heads, length or 1, length or depth]
xy_matmul = tf.matmul(x, y, transpose_b=transpose)
# x_t is [length or 1, batch_size, heads, length or depth]
x_t = tf.transpose(x, [2, 0, 1, 3])
# x_t_r is [length or 1, batch_size * heads, length or depth]
x_t_r = tf.reshape(x_t, [length, heads * batch_size, -1])
# x_tz_matmul is [length or 1, batch_size * heads, length or depth]
x_tz_matmul = tf.matmul(x_t_r, z, transpose_b=transpose)
# x_tz_matmul_r is [length or 1, batch_size, heads, length or depth]
x_tz_matmul_r = tf.reshape(x_tz_matmul, [length, batch_size, heads, -1])
# x_tz_matmul_r_t is [batch_size, heads, length or 1, length or depth]
x_tz_matmul_r_t = tf.transpose(x_tz_matmul_r, [1, 2, 0, 3])
return xy_matmul + x_tz_matmul_r_t
结果
使用Attention is All You Need的机器翻译的任务。在training steos每秒去掉7%的条件下,模型的BLEU分数对于English-to-German最高提升了1.3, 对于English-to-French最高提升了0.5.
 [支付宝] 感谢您的捐赠!
[支付宝] 感谢您的捐赠!
But one thing I do: Forgetting what is behind and straining toward what is ahead. ~Bible.Philippians.
[NLP] 相对位置编码(一) Relative Position Representatitons (RPR) - Transformer的更多相关文章
- [NLP] 相对位置编码(二) Relative Positional Encodings - Transformer-XL
参考: 1. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context https://arxiv.org/pdf ...
- 中文NER的那些事儿5. Transformer相对位置编码&TENER代码实现
这一章我们主要关注transformer在序列标注任务上的应用,作为2017年后最热的模型结构之一,在序列标注任务上原生transformer的表现并不尽如人意,效果比bilstm还要差不少,这背后有 ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- 13-[CSS]-postion位置:相relative,绝absolute,固fixed,static(默认),z-index
1.postion位置属性 <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- 第五课第四周实验一:Embedding_plus_Positional_encoding 嵌入向量加入位置编码
目录 变压器预处理 包 1 - 位置编码 1.1 - 位置编码可视化 1.2 - 比较位置编码 1.2.1 - 相关性 1.2.2 - 欧几里得距离 2 - 语义嵌入 2.1 - 加载预训练嵌入 2. ...
- Dedecms当前位置{dede:field name='position'/}修改
这个实在list_article.htm模板出现的,而这个模板通过loadtemplage等等一系列操作是调用的include 下的arc.archives.class.php $this->F ...
- Dedecms当前位置{dede:field name='position'/}修改,去掉>方法
Dedecms当前位置{dede:field name='position'/}修改,如何去掉> 一.修改{dede:field name='position'/}的文字间隔符,官方默认的是&g ...
- css背景图片位置:background的position(转)
css背景图片位置:background的position position的两个参数:水平方向的位置,垂直方向的位置----------该位置是指背景图片相对于前景对象的 1.backgroun ...
- DIV滚动条滚动到指定位置(jquery的position()与offset()方法区别小记)
相对浏览器,将指定div滚到到指定位置,其用法如下 $("html,body").animate({scrollTop: $(obj).offset().top},speed); ...
随机推荐
- 伪元素黑魔法:一个替代onerror解决图片加载失败的方案
问题的引出是这样的,在一个项目中有大量的页面主体是table做数据展示,所以就封装了一个table的组件,提供动态渲染的方案.有个问题是数据类型中有图片,对于图片的加载失败我们需要做容错.一般我们的思 ...
- 前端开发在手机UC浏览器上遇到的坑
1.user-scalable问题 写手机页面都会加一个meta标签 <meta content="width=device-width, initial-scale=1.0, max ...
- 【Web前端Talk】React-loadable 进行代码分割的基本使用
随着项目功能的扩充.版本迭代,我们与Webpack捆绑起来的的项目越来越大,大到开始影响加载速度了.这时我们就该考虑如何对代码进行拆分了. 这次我们一起学习一下如何对React项目中的代码进行Code ...
- python常用数据结构(2)
1.有名字的元组——namedtuple >>> from collections import namedtuple >>> Point = namedtuple ...
- 一步到位安装Centos7、配置VMware、连接Xshell
1.创建虚拟机 1.0 创建新的虚拟机 1.0.1 选择自定义配置 打开VMware,点击创建新的虚拟机. 如下图所示: 1.0.2 选择虚拟机硬件兼容性 如下图所示: 1.0.3 安装客户操 ...
- Spark学习之路(三)—— 弹性式数据集RDDs
弹性式数据集RDDs 一.RDD简介 RDD全称为Resilient Distributed Datasets,是Spark最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集 ...
- spring 5.x 系列第4篇 —— spring AOP (代码配置方式)
文章目录 一.说明 1.1 项目结构说明 1.2 依赖说明 二.spring aop 2.1 创建待切入接口及其实现类 2.2 创建自定义切面类 2.3 配置切面 2.4 测试切面 2.5 切面执行顺 ...
- mysql数据库在linux下的导出和导入及每天的备份
mysql数据库的导出,导入 1. 导出数据库为sql文件 mysqldump 数据库名 -uroot -p > xxx.sql 导出数据表结构和数据 eg. mysqldump cloud ...
- linuxprobe培训第1节课笔记2019年7月5日
报了老刘的RHCE培训,这是老刘上课笔记简略版. 老刘在课上介绍了开源共享精神和大胡子(Richard M. Stallman—GNU创始人).linux发展史(Linus Benedict Torv ...
- 阿里巴巴 -- MySQL DBA 面试题
1.MySQL的复制原理以及流程 (1).先问基本原理流程,3个线程以及之间的关联: (2).再问一致性延时性,数据恢复: (3).再问各种工作遇到的复制bug的解决方法. 2.MySQL中myisa ...