数据挖掘--K-means
K-Means方法是MacQueen1967年提出的。给定一个数据集合X和一个整数K(n),K-Means方法是将X分成K个聚类并使得在每个聚类中所有值与该聚类中心距离的总和最小。
K-Means聚类方法分为以下几步:
[1] 给K个cluster选择最初的中心点,称为K个Means。
[2] 计算每个对象和每个中心点之间的距离。
[3] 把每个对象分配给距它最近的中心点做属的cluster。
[4] 重新计算每个cluster的中心点。
[5] 重复2,3,4步,直到算法收敛。
以下几张图动态展示了这几个步骤:
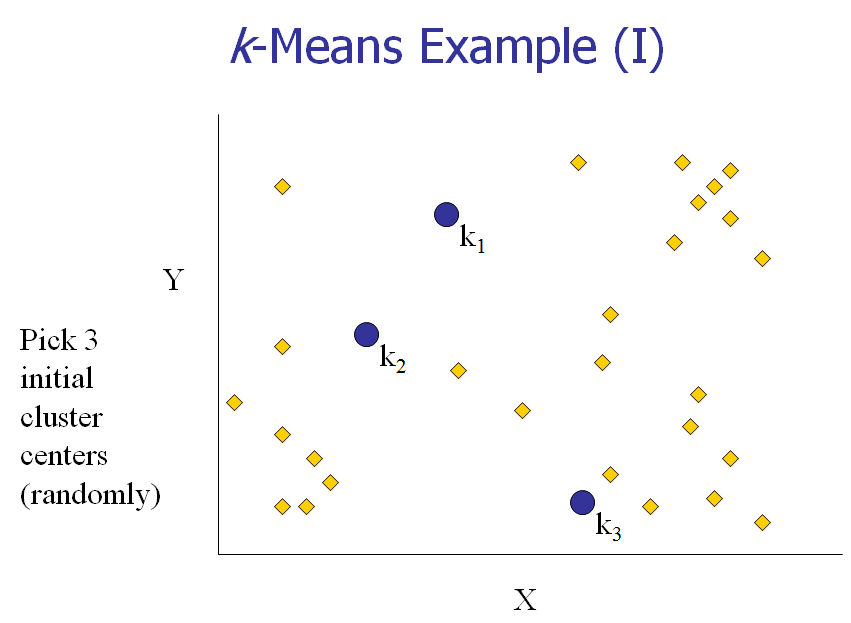
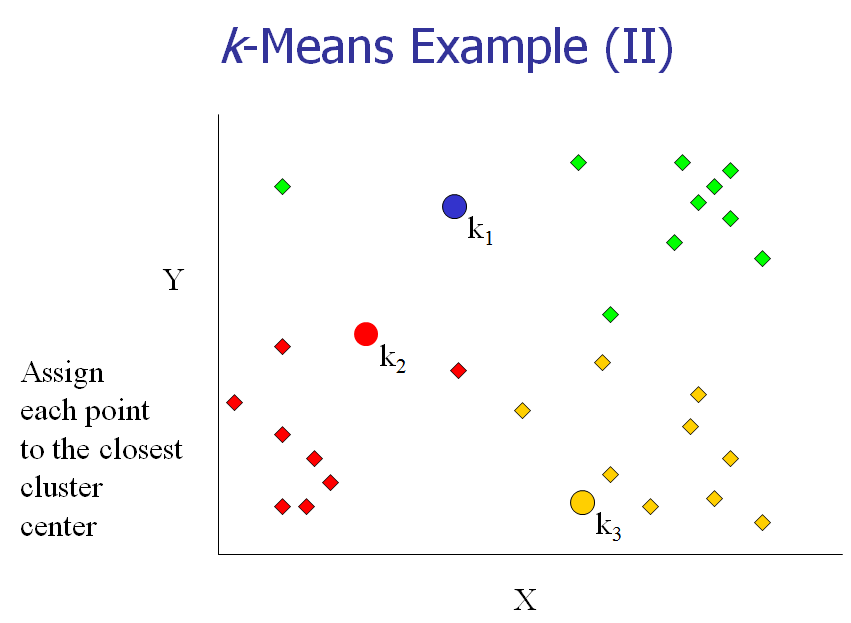


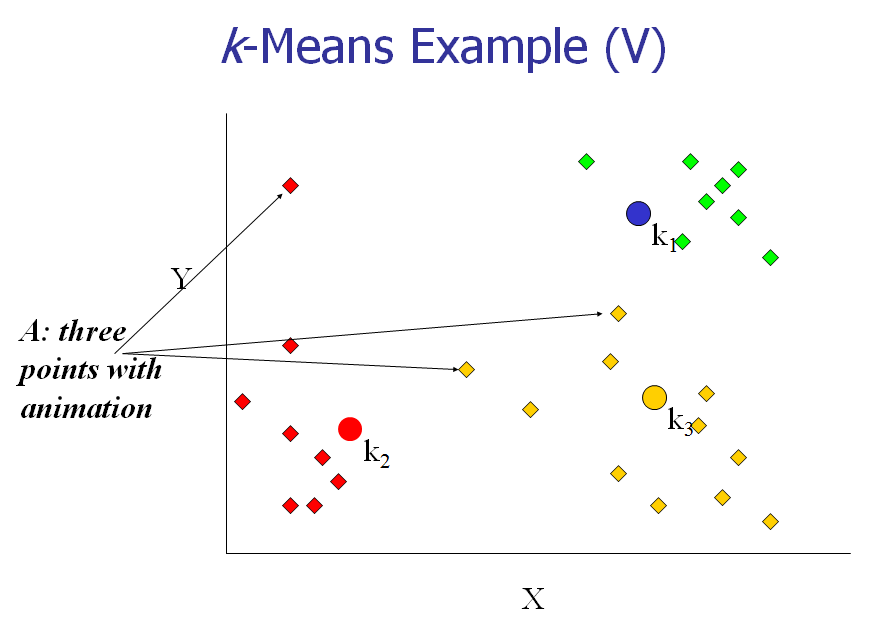


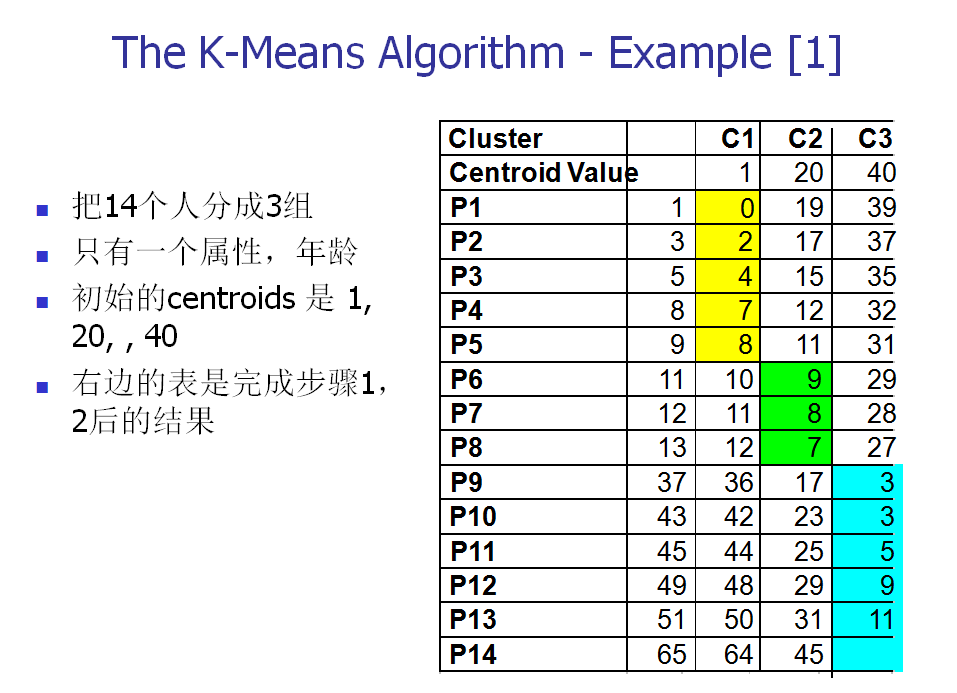
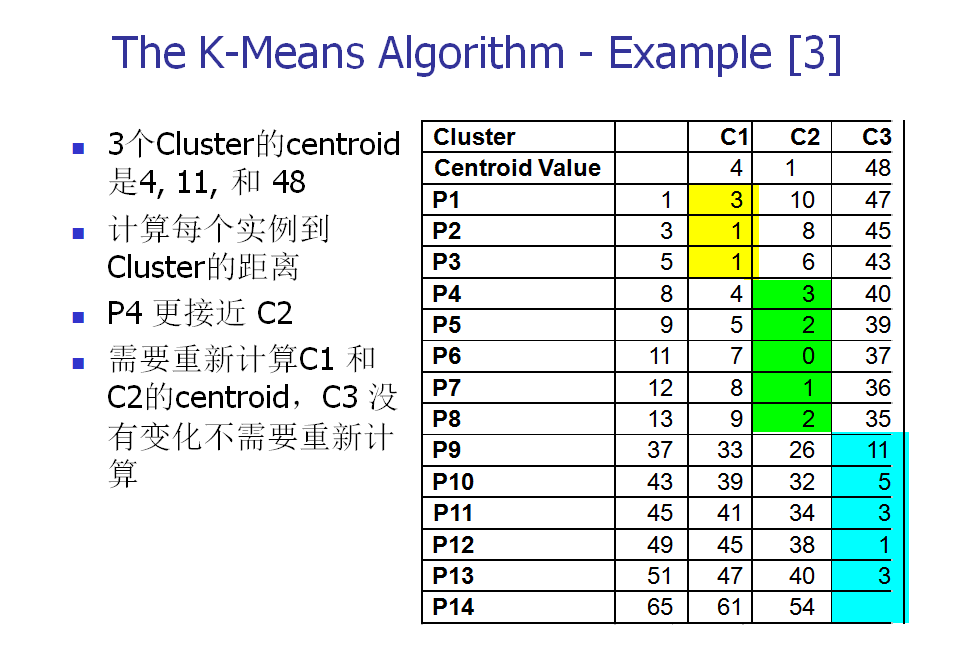
下面,我们以一个具体的例子来说明一下K-means算法的实现。


K-means算法的优缺点:
优点:
(1)对于处理大数据量具有可扩充性和高效率。算法的复杂度是O(tkn),其中n是对象的个数,k是cluster的个数,t是循环的次数,通常k,t<<n。
(2)可以实现局部最优化,如果要找全局最优,可以用退火算法或者遗传算法
缺点:
(1)Cluster的个数必须事先确定,在有些应用中,事先并不知道cluster的个数。
(2)K个中心点必须事先预定,而对于有些字符属性,很难确定中心点。
(3)不能处理噪音数据。
(4)不能处理有些分布的数据(例如凹形)
K-Means方法的变种
(1) K-Modes :处理分类属性
(2) K-Prototypes:处理分类和数值属性
(3) K-Medoids
它们与K-Means方法的主要区别在于:
(1)最初的K个中心点的选择不同。
(2)距离的计算方式不同。
(3)计算cluster的中心点的策略不同。
数据挖掘--K-means的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- K-MEANS算法总结
K-MEANS算法 摘要:在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 在数据挖掘中,K-M ...
- 关于K-Means算法
在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 问题 K-Means算法主要解决的问题如下图所示. ...
- 当我们在谈论kmeans(3)
本系列意在长期连载分享,内容上可能也会有所删改: 因此如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/(暂时公式显示有问题) ...
- K-Means 算法(转载)
K-Means 算法 在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 问题 K-Means ...
随机推荐
- Lustre 文件系统安装
制作一个本地镜像 reposync configfile: [root@localhost html]# cat lustre-repo.conf [lustre-server] name=lustr ...
- 『005』Web集群
『006』索引-The Web cluster 准备更新中
- 8.Java基础_if-else和switch选择语句
/* 选择语句(基本与C++相同) if-else语句: 格式一: if(关系式){ 语句体; } 格式二: if(关系式){ 语句体; } else{ 语句体; } 格式三: if(关系式){ 语句 ...
- Jmeter请求
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:web=& ...
- day70_10_16drf组件响应模块,异常模块和序列化模块。
一.解析模块 为什么要配置解析模块? 1)drf给我们通过了多种解析数据包方式的解析类. 2)我们可以通过配置来控制前台提交的哪些格式的数据后台在解析,哪些数据不解析. 3)全局配置就是针对每一个视图 ...
- 对象锁和class锁
对象锁:就是这个锁属于这个类的对象实例,可以通过为类中的非静态方法加synchronized关键字 或者使用 synchronized(this) 代码块,为程序加对象锁. Class锁:就是这个锁属 ...
- zz自动驾驶多传感器感知的探索
案例教学,把“问题”讲清楚了,赞 Pony.ai 在多传感器感知上积累了很多的经验,尤其是今年年初在卡车上开始了新的尝试.我们有不同的传感器配置,以及不同的场景,对多传感器融合的一些新的挑战,有了更深 ...
- 怎样用cmd脚本添加Qt的环境变量
在网上遍历了很久,终于找到了一个简单且令人满意的答案: 定位到PyQt5发布文件所需的plugins的位置: 新建一个名为“设置环境变量”的cmd脚本,在里面写上: wmic ENVIRONMENT ...
- Pandownload倒下了,还有它,又一款百度云下载神器,速度可达10M/s
最近很多小伙伴反馈 Pandownload 不好使了 对此我表示 脑壳疼 不过经过一番折腾 还是找到了一个不错的替代品 它就是 baidupcs-web 下载解压后就这么一个可执行文件 干净的不可思议 ...
- ThreadPoolExecutor 线程池 简单解析
jdk1.8 ThreadPoolExecutor ThreadPoolExecutor实际就是java的线程池,开发常用的Executors.newxxxxx()来创建不同类型和作用的线程池,其底部 ...