spark 源码分析之十四 -- broadcast 是如何实现的?
本篇文章主要剖析broadcast 的实现机制。
BroadcastManager初始化
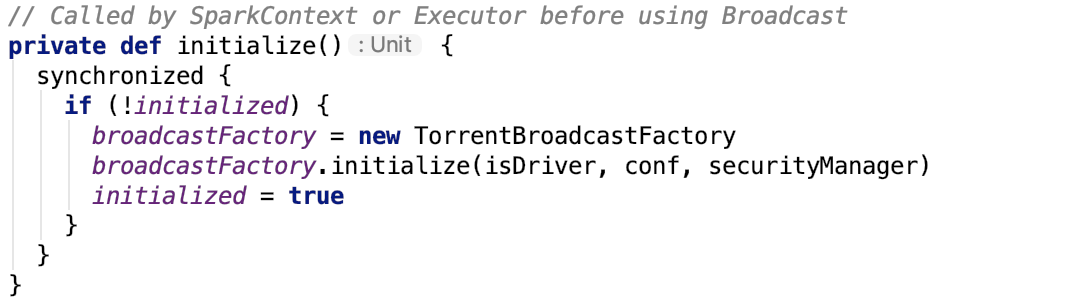
BroadcastManager初始化方法源码如下:
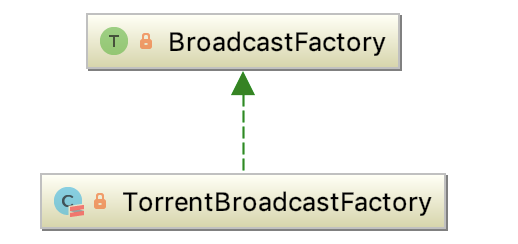
TorrentBroadcastFactory的继承关系如下:
BroadcastFactory
An interface for all the broadcast implementations in Spark (to allow multiple broadcast implementations). SparkContext uses a BroadcastFactory implementation to instantiate a particular broadcast for the entire Spark job.
即它是Spark中broadcast中所有实现的接口。SparkContext使用BroadcastFactory实现来为整个Spark job实例化特定的broadcast。它有唯一子类 -- TorrentBroadcastFactory。
它有两个比较重要的方法:
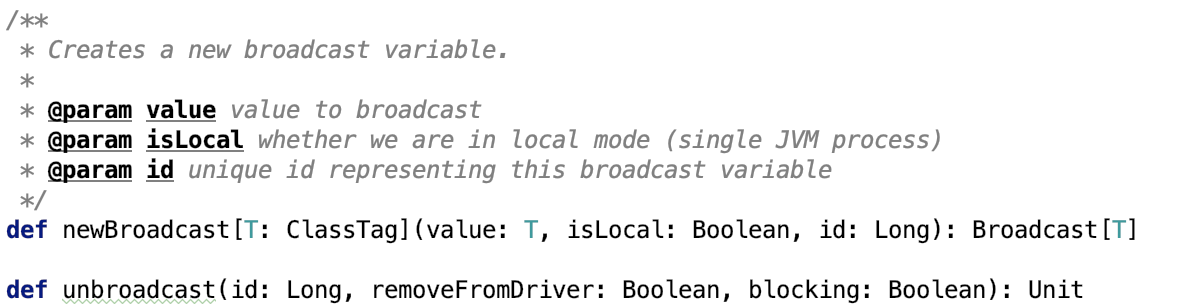
newBroadcast 方法负责创建一个broadcast变量。
TorrentBroadcastFactory
其主要方法如下:
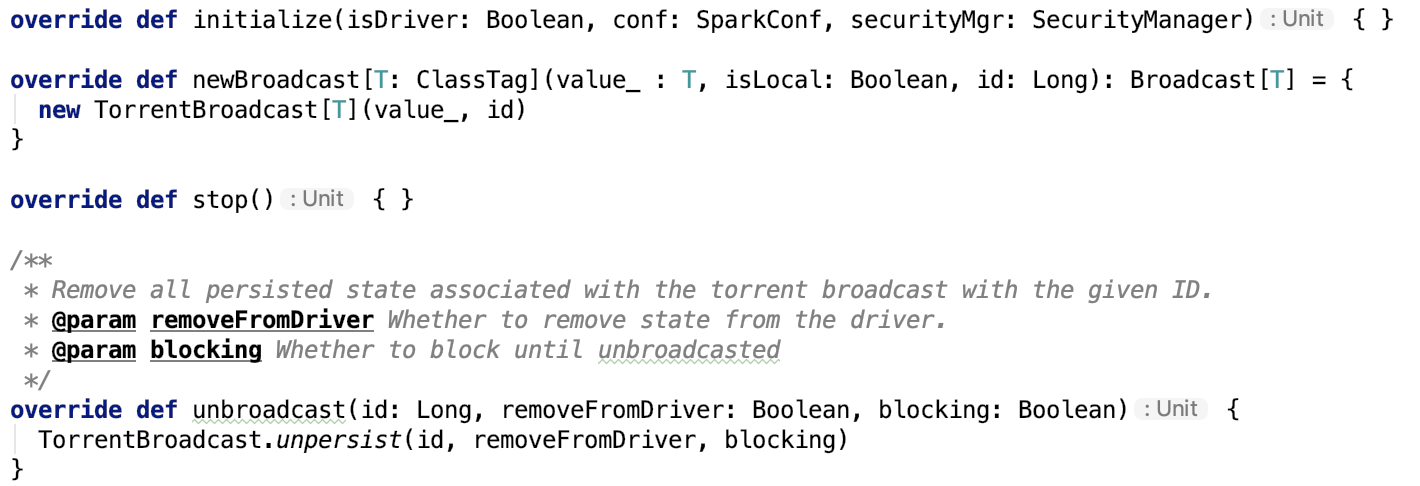
newBroadcast其实例化TorrentBroadcast类。
unbroadcast方法调用了TorrentBroadcast 类的 unpersist方法。
TorrentBroadcast父类Broadcast
官方说明如下:
A broadcast variable. Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks.
They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost. Broadcast variables are created from a variable v by calling org.apache.spark.SparkContext.broadcast. The broadcast variable is a wrapper around v, and its value can be accessed by calling the value method.
The interpreter session below shows this: scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0) scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3) After the broadcast variable is created, it should be used instead of the value v in any functions run on the cluster so that v is not shipped to the nodes more than once. In addition, the object v should not be modified after it is broadcast in order to ensure that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped to a new node later).
即广播变量允许编程者将一个只读变量缓存到每一个机器上,而不是随任务一起发送它的副本。它们可以被用来用一种高效的方式拷贝输入的大数据集。Spark也尝试使用高效的广播算法来减少交互代价。它通过调用SparkContext的broadcast 方法创建,broadcast变量是对真实变量的包装,它可以通过broadcast对象的value方法返回真实对象。一旦真实对象被广播了,要确保对象不会被改变,以确保该数据在所有节点上都是一致的。
TorrentBroadcast继承关系如下:

TorrentBroadcast 是 Broadcast 的唯一子类。
TorrentBroadcast
其说明如下:
A BitTorrent-like implementation of org.apache.spark.broadcast.Broadcast.
The mechanism is as follows:
The driver divides the serialized object into small chunks and stores those chunks in the BlockManager of the driver.
On each executor, the executor first attempts to fetch the object from its BlockManager.
If it does not exist, it then uses remote fetches to fetch the small chunks from the driver and/or other executors if available.
Once it gets the chunks, it puts the chunks in its own BlockManager, ready for other executors to fetch from.
This prevents the driver from being the bottleneck in sending out multiple copies of the broadcast data (one per executor).
When initialized, TorrentBroadcast objects read SparkEnv.get.conf.
实现机制:
driver 将数据拆分成多个小的chunk并将这些小的chunk保存在driver的BlockManager中。在每一个executor节点上,executor首先先从它自己的blockmanager获取数据,如果不存在,它使用远程抓取,从driver或者是其他的executor中抓取数据。一旦它获取到chunk,就将其放入到自己的BlockManager中,准备被其他的节点请求获取。这使得driver发送多个副本到多个executor节点的瓶颈不复存在。
driver 端写数据

广播数据的保存有两种形式:
1. 数据保存在memstore中一份,需要反序列化后存入;保存在磁盘中一份,磁盘中的那一份先使用 SerializerManager序列化为字节数组,然后保存到磁盘中。
2. 将对象根据blockSize(默认为4m,可以通过spark.broadcast.blockSize 参数指定),compressCodec(默认是启用的,可以通过 spark.broadcast.compress参数禁用。压缩算法默认是lz4,可以通过 spark.io.compression.codec 参数指定)将数据写入到outputStream中,进而拆分为几个小的chunk,最终将数据持久化到blockManager中,也是memstore一份,不需要反序列化;磁盘一份。
其中,TorrentBroadcast 的 blockifyObject 方法如下:

压缩的Outputstream对 ChunkedByteBufferOutputStream 做了装饰。
driver或executor读数据
broadcast 方法调用 value 方法时, 会调用 TorrentBroadcast 的 getValue 方法,如下:

_value 字段声明如下:
private lazy val _value: T = readBroadcastBlock()
接下来看一下 readBroadcastBlock 这个方法:
private def readBroadcastBlock(): T = Utils.tryOrIOException {
TorrentBroadcast.synchronized {
val broadcastCache = SparkEnv.get.broadcastManager.cachedValues
Option(broadcastCache.get(broadcastId)).map(_.asInstanceOf[T]).getOrElse {
setConf(SparkEnv.get.conf)
val blockManager = SparkEnv.get.blockManager
blockManager.getLocalValues(broadcastId) match {
case Some(blockResult) =>
if (blockResult.data.hasNext) {
val x = blockResult.data.next().asInstanceOf[T]
releaseLock(broadcastId)
if (x != null) {
broadcastCache.put(broadcastId, x)
}
x
} else {
throw new SparkException(s"Failed to get locally stored broadcast data: $broadcastId")
}
case None =>
logInfo("Started reading broadcast variable " + id)
val startTimeMs = System.currentTimeMillis()
val blocks = readBlocks()
logInfo("Reading broadcast variable " + id + " took" + Utils.getUsedTimeMs(startTimeMs))
try {
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks.map(_.toInputStream()), SparkEnv.get.serializer, compressionCodec)
// Store the merged copy in BlockManager so other tasks on this executor don't
// need to re-fetch it.
val storageLevel = StorageLevel.MEMORY_AND_DISK
if (!blockManager.putSingle(broadcastId, obj, storageLevel, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
if (obj != null) {
broadcastCache.put(broadcastId, obj)
}
obj
} finally {
blocks.foreach(_.dispose())
}
}
}
}
}
对源码作如下解释:
第3行:broadcastManager.cachedValues 保存着所有的 broadcast 的值,它是一个Map结构的,key是强引用,value是虚引用(在垃圾回收时会被清理掉)。
第4行:根据 broadcastId 从cachedValues 中取数据。如果没有,则执行getOrElse里的 default 方法。
第8行:从BlockManager的本地获取broadcast的值(从memstore或diskstore中,获取的数据是完整的数据,不是切分之后的小chunk),若有,则释放BlockManager的锁,并将获取的值存入cachedValues中;若没有,则调用readBlocks将chunk 数据读取到并将数据转换为 broadcast 的value对象,并将该对象放入cachedValues中。
其中, readBlocks 方法如下:
/** Fetch torrent blocks from the driver and/or other executors. */
private def readBlocks(): Array[BlockData] = {
// Fetch chunks of data. Note that all these chunks are stored in the BlockManager and reported
// to the driver, so other executors can pull these chunks from this executor as well.
val blocks = new Array[BlockData](numBlocks)
val bm = SparkEnv.get.blockManager for (pid <- Random.shuffle(Seq.range(0, numBlocks))) {
val pieceId = BroadcastBlockId(id, "piece" + pid)
logDebug(s"Reading piece $pieceId of $broadcastId")
// First try getLocalBytes because there is a chance that previous attempts to fetch the
// broadcast blocks have already fetched some of the blocks. In that case, some blocks
// would be available locally (on this executor).
bm.getLocalBytes(pieceId) match {
case Some(block) =>
blocks(pid) = block
releaseLock(pieceId)
case None =>
bm.getRemoteBytes(pieceId) match {
case Some(b) =>
if (checksumEnabled) {
val sum = calcChecksum(b.chunks(0))
if (sum != checksums(pid)) {
throw new SparkException(s"corrupt remote block $pieceId of $broadcastId:" +
s" $sum != ${checksums(pid)}")
}
}
// We found the block from remote executors/driver's BlockManager, so put the block
// in this executor's BlockManager.
if (!bm.putBytes(pieceId, b, StorageLevel.MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(
s"Failed to store $pieceId of $broadcastId in local BlockManager")
}
blocks(pid) = new ByteBufferBlockData(b, true)
case None =>
throw new SparkException(s"Failed to get $pieceId of $broadcastId")
}
}
}
blocks
}
源码解释如下:
第14行:根据pieceid从本地BlockManager 中获取到 chunk
第15行:如果获取到了chunk,则释放锁。
第18行:如果没有获取到chunk,则从远程根据pieceid获取远程获取chunk,获取到chunk后做checksum校验,之后将chunk存入到本地BlockManager中。
注:本篇文章没有对BroadcastManager中关于BlockManager的操作做进一步更详细的说明,下一篇文章会专门剖析Spark的存储体系。
spark 源码分析之十四 -- broadcast 是如何实现的?的更多相关文章
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
- spark 源码分析之十九 -- Stage的提交
引言 上篇 spark 源码分析之十九 -- DAG的生成和Stage的划分 中,主要介绍了下图中的前两个阶段DAG的构建和Stage的划分. 本篇文章主要剖析,Stage是如何提交的. rdd的依赖 ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析
spark 源码分析之十--Spark RPC剖析之TransportResponseHandler.TransportRequestHandler和TransportChannelHandler剖析 ...
- Vue.js 源码分析(二十四) 高级应用 自定义指令详解
除了核心功能默认内置的指令 (v-model 和 v-show),Vue 也允许注册自定义指令. 官网介绍的比较抽象,显得很高大上,我个人对自定义指令的理解是:当自定义指令作用在一些DOM元素或组件上 ...
- Android源码分析(十四)----如何使用SharedPreferencce保存数据
一:SharedPreference如何使用 此文章只是提供一种数据保存的方式, 具体使用场景请根据需求情况自行调整. EditText添加saveData点击事件, 保存数据. diff --git ...
随机推荐
- mingw64 构建 Geos
简述 在做某个小程序时候用到了QT,而用的Qt是mingw版本的,所以使用mingw构建了一下geos库. 1.准备工作 首先需要先安装好mingw,这里直接使用http://www.mingw-w6 ...
- excel操作for(lutai)
条件统计某个区域的值 第一种方法: =SUMIFS(P2:P5,L2:L5,A2) 第一个参数:被求和的单元格范围 第二个参数:明细表条件值单元格范围 第三个参数:主表条件单元格(可以是范围) 公式的 ...
- Win8Metro(C#)数字图像处理--2.30直方图均衡化
原文:Win8Metro(C#)数字图像处理--2.30直方图均衡化 [函数名称] 直方图均衡化函数HistogramEqualProcess(WriteableBitmap src) [算法说明] ...
- Win8Metro(C#)数字图像处理--2.7图像伪彩色
原文:Win8Metro(C#)数字图像处理--2.7图像伪彩色 2.7图像伪彩色函数 [函数名称] 图像伪彩色函数PseudoColorProcess(WriteableBitmap src) ...
- mysql自动化安装脚本(二进制安装)
为了日后安装数据库方便,遂写了一个自动安装MySQL的脚本: 测试可以安装mariadb和MySQL-5.7.X 安装前配置好对应的my.cnf文件放在/tmp路径下 将启动脚本mysql3306放在 ...
- ORACLE RAC+OGG配置
实验环境主机名 IP地址rac01 192.168.56.10rac02 192.168.56.20rac-scan 192.168.56.30 目标库:ora-ogg 192. ...
- MongoDB.Driver 管道 Aggregate
目前mongodb for C#这个驱动,在进行Aggregate时,只支持BsonDocument类型,也就是说,你的集合collection也必须返回的是BsonDocument,而实体类型是不可 ...
- PHP 的异步并行 C 扩展 Swoole
PHP的异步.并行.高性能网络通信引擎,使用纯C语言编写,提供了PHP语言的异步多线程服务器,异步TCP/UDP网络客户端,异步MySQL,异步Redis,数据库连接池,AsyncTask,消息队列, ...
- SpringMVC与uploadify结合进行上传
uploadify是一个第三方js插件,支持多文件上传,拥有较为强大的上传功能 1.uploadify实现 下载其flash版本 http://www.uploadify.com/ 解压后将其内容区 ...
- How Qt Signals and Slots Work(感觉是通过Meta根据名字来调用)
Qt is well known for its signals and slots mechanism. But how does it work? In this blog post, we wi ...