CTR@因子分解机(FM)
1. FM算法
FM(Factor Machine,因子分解机)算法是一种基于矩阵分解的机器学习算法,为了解决大规模稀疏数据中的特征组合问题。FM算法是推荐领域被验证效果较好的推荐算法之一,在电商、广告、直播等推荐领域有广泛应用。
2. FM算法优势
特征组合:通过对两两特征组合,引入交叉项特征。
解决维数灾难:通过引入隐向量,实现对特征的参数估计。
3. FM表达式
对于度为2的因子分解机FM的模型为:
 其中,参数
其中,参数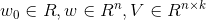 。 aaarticlea/gif;base64,R0lGODlhMAAUALMAAP///wAAAHZ2du7u7kRERIiIiKqqqjIyMszMzGZmZpiYmNzc3FRUVLq6uhAQECIiIiH5BAEAAAAALAAAAAAwABQAAATdEEghq704a0vvIFsobsxyFcaork1XHWs8whWSyLhWNFWC5EDLgPGyNBQ3wMBhUh2Ty2aGMAAYFJUB1vEDHHgjLYAr+W6uAGqFtwhUCk2DC8N2S+CWxwVE4xAlWBJVIgJ/AIEVUmUAAl0VDymAMpAViBkLRAtJFQGDCE0FhhudEp+VjRxdIBakh5IPg5iDrIOIBgNyFn0KkRIGCQqWC30IDpa+wJZVCb0NBVmrIQLHvSoHUgyzACUisJbVIw7QFy2EeHfaIgjRKBh9K+AiBc+LGIpBGhTXifhABLwbIgAAOw==" alt="" />表示的是两个大小为aaarticlea/gif;base64,R0lGODlhCQANALMAAP///wAAAHZ2du7u7szMzDIyMhAQEKqqqlRUVJiYmNzc3Lq6ukRERIiIiCIiIgAAACH5BAEAAAAALAAAAAAJAA0AAAQyEEgxpCXF2H3QtkjySYYyKhpwJB7AusOSMs0xBsVRXRpRWo2Ww7YAFEQAByGW3CUEyAgAOw==" alt="" />的向量aaarticlea/gif;base64,R0lGODlhDQALALMAAP///wAAALq6upiYmGZmZu7u7hAQENzc3MzMzDIyMoiIiHZ2dlRUVCIiIqqqqgAAACH5BAEAAAAALAAAAAANAAsAAAQ6EIhBACjmWFsGMIiVCJsEHMGmaICzWAuzedzWOHO5BYWFsAqZhWeheRq9FmFAsxwSuuiiGbUgqdJVBAA7" alt="" />和向量aaarticlea/gif;base64,R0lGODlhDwAOALMAAP///wAAALq6upiYmGZmZu7u7hAQENzc3MzMzDIyMoiIiHZ2dlRUVCIiIqqqqkRERCH5BAEAAAAALAAAAAAPAA4AAARLEIhBACjm2H0HMIiVCJxFHsGmaFuzLczmcSzQOHLJBYWF1INFyMKzzACOgmOxcRAGxwuAgNPpEjXrxqAtIR5djkIRBjCx5cegCogAADs=" alt="" />的点积:
。 aaarticlea/gif;base64,R0lGODlhMAAUALMAAP///wAAAHZ2du7u7kRERIiIiKqqqjIyMszMzGZmZpiYmNzc3FRUVLq6uhAQECIiIiH5BAEAAAAALAAAAAAwABQAAATdEEghq704a0vvIFsobsxyFcaork1XHWs8whWSyLhWNFWC5EDLgPGyNBQ3wMBhUh2Ty2aGMAAYFJUB1vEDHHgjLYAr+W6uAGqFtwhUCk2DC8N2S+CWxwVE4xAlWBJVIgJ/AIEVUmUAAl0VDymAMpAViBkLRAtJFQGDCE0FhhudEp+VjRxdIBakh5IPg5iDrIOIBgNyFn0KkRIGCQqWC30IDpa+wJZVCb0NBVmrIQLHvSoHUgyzACUisJbVIw7QFy2EeHfaIgjRKBh9K+AiBc+LGIpBGhTXifhABLwbIgAAOw==" alt="" />表示的是两个大小为aaarticlea/gif;base64,R0lGODlhCQANALMAAP///wAAAHZ2du7u7szMzDIyMhAQEKqqqlRUVJiYmNzc3Lq6ukRERIiIiCIiIgAAACH5BAEAAAAALAAAAAAJAA0AAAQyEEgxpCXF2H3QtkjySYYyKhpwJB7AusOSMs0xBsVRXRpRWo2Ww7YAFEQAByGW3CUEyAgAOw==" alt="" />的向量aaarticlea/gif;base64,R0lGODlhDQALALMAAP///wAAALq6upiYmGZmZu7u7hAQENzc3MzMzDIyMoiIiHZ2dlRUVCIiIqqqqgAAACH5BAEAAAAALAAAAAANAAsAAAQ6EIhBACjmWFsGMIiVCJsEHMGmaICzWAuzedzWOHO5BYWFsAqZhWeheRq9FmFAsxwSuuiiGbUgqdJVBAA7" alt="" />和向量aaarticlea/gif;base64,R0lGODlhDwAOALMAAP///wAAALq6upiYmGZmZu7u7hAQENzc3MzMzDIyMoiIiHZ2dlRUVCIiIqqqqkRERCH5BAEAAAAALAAAAAAPAA4AAARLEIhBACjm2H0HMIiVCJxFHsGmaFuzLczmcSzQOHLJBYWF1INFyMKzzACOgmOxcRAGxwuAgNPpEjXrxqAtIR5djkIRBjCx5cegCogAADs=" alt="" />的点积:
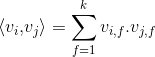
其中,aaarticlea/gif;base64,R0lGODlhDQALALMAAP///wAAALq6upiYmGZmZu7u7hAQENzc3MzMzDIyMoiIiHZ2dlRUVCIiIqqqqgAAACH5BAEAAAAALAAAAAANAAsAAAQ6EIhBACjmWFsGMIiVCJsEHMGmaICzWAuzedzWOHO5BYWFsAqZhWeheRq9FmFAsxwSuuiiGbUgqdJVBAA7" alt="" />表示的是系数矩阵aaarticlea/gif;base64,R0lGODlhDgAMALMAAP///wAAAHZ2dhAQEGZmZszMzJiYmDIyMqqqqoiIiO7u7rq6ulRUVAAAAAAAAAAAACH5BAEAAAAALAAAAAAOAAwAAAQ7EIgRSAEYmHAQTkGWKYSIBIoIJGoRXNkCj4GHKawKBEKW6wcGRqbDMA4AXBEzkSwxG8OsuAj8lgrkMgIAOw==" alt="" />的第aaarticlea/gif;base64,R0lGODlhBgANALMAAP///wAAAKqqqhAQEO7u7tzc3Lq6upiYmGZmZszMzHZ2diIiIoiIiAAAAAAAAAAAACH5BAEAAAAALAAAAAAGAA0AAAQiEMg5xaCk0L3NQRJxAEMCGEARUAo4ldVySooCMFKCHAQQAQA7" alt="" />维向量,且aaarticlea/gif;base64,R0lGODlh5gAWALMAAP///wAAALq6upiYmGZmZu7u7hAQENzc3MzMzDIyMoiIiHZ2dlRUVCIiIqqqqkRERCH5BAEAAAAALAAAAADmABYAAAT+EMhJq7046827/2AojmRpnmiqrmw7IoILFoNs3+FQ4LLg8BsCcEicFISfxa548TErCsRzahMoOoiEQbZoBKSSAiPw+FGcVEAizWatOw6GTdGQU5CAI4HweOwJB0wDNW2FJwpmGwyEHAcLfX1XGgMKAUt5iWeZTA+Bhp8vdhsGnhsDD2AdAgcFAZIADpeaFQIDSAWkMltntmG5J7W3v2zBvqUguxoHuw4DorR4HpIEya+0mTQABmAJMS7JeTXbEt0n2eNq3mnn3OogARzOADoC4BRvIJIIAd7WsxMxDsCToMCTgwUXCDBYyLAhQgsHGpwBIHBCQQkHIT7YEHAggIv+sB5OcKBgQbQWHS0aFBnmgT8JDWRdcLkJIssO2chtPOCugkwAC0Qx+lkiooWgE4ZaGNClA1IJSikUkMTgZoun84xcYNATJlEKARLE0iCgAaSzLwGWchDgACMPDRK9XYHLQtykG4xyuAs1g4A3A/DJ4JtVg8QL9iwg2LL4WIUDJ+NVMLAgrQZLEhB4UvDsTsPPVTEkxgxAM8HOEvRuIG36I2pPJnGw3vx6zUF3iaHYuduVXI4KCwxYzkCaUI2YKzpVKN4X+ePDqRn8ZJ7VuV1PB6Q/1k6Re/Yl3y1QPy7TAQEdUSYgEBX+HqEGCAr0Lo06A4K5reZnMD+IwgHBKPTcRwF/b/13gWqlGTAXLOcVCOAEXKmnYAWLgVFhZugstiCB/j1ITU2ISDiXc0wtOGAZjllATQNzRUbCAiaWUMBGHMB4IHQjeWCjBekdUxMIP16wIwUxVVbBg0F+QAMfkVARU4wvppLBkwAIcAmCGMGVjZUYxXKANUnCoWUNXBYg0UGt1WJBmKA4BdIKLgJ3kUsSCECAK6Uo8NVRc14hUACAiqRnCYO6GQidCAhxBCFH8Lhnm2zk5EGYbO6nQaWXkpCkDmtC6qkIBWAaQqiekvrpqTKIGoKqRbCK6gYRAAA7" alt="" />称为超参数。在因子分解机FM模型中,前面两部分是传统的线性模型,最后一部分将两个互异特征分量之间的交叉关系考虑进来。
因子分解机也可以推广到高阶的形式,即将更多互异特征分量之间的相互关系考虑进来。
4. 交叉项

算法核心为交叉项计算,可以明显降低模型时间复杂度,现在模型的复杂度为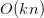 。
。
5. 求解问题
FM算法主要可以处理三类问题:回归问题、二分类问题、排序。
5.1 回归问题
在回归问题中,直接使用aaarticlea/gif;base64,R0lGODlhDAASALMAAP///wAAALq6uqqqqtzc3ERERDIyMszMzO7u7nZ2dlRUVGZmZoiIiJiYmBAQECIiIiH5BAEAAAAALAAAAAAMABIAAARREEgpxryAFLPPRYniZcuCSAyBAQhzrnA8HcMyDcqENIAzKomJIBOYOIaXkORQxDwsAIZhFXgVgpgqEXlpJLzaGKOwOkoeXAnCBkiwMQ0vbxUBADs=" alt="" />作为最终的预测结果。在回归问题中使用最小均方误差作为优化标准,即

其中,aaarticlea/gif;base64,R0lGODlhEAAIALMAAP///wAAAJiYmIiIiO7u7lRUVLq6uszMzNzc3KqqqiIiIkRERHZ2dmZmZhAQEDIyMiH5BAEAAAAALAAAAAAQAAgAAAQ/EIgxiBDFWHwAIAYSCF6ikNLiGYDpScrLFC/QMG+BewvqOaxfkBBAvETHwEvwAASZS5WnMQBUAQxf9nVgVAARADs=" alt="" />表示样本的个数。
5.2 二分类问题
在二分类问题中使用Logitloss作为优化标准,即

其中,aaarticlea/gif;base64,R0lGODlhCwAIALMAAP///wAAAJiYmCIiIhAQEFRUVGZmZu7u7kRERHZ2drq6ujIyMszMzKqqqtzc3AAAACH5BAEAAAAALAAAAAALAAgAAAQoEEgxgg1EgmLOQYkGCIimLCLBaE0pOZlmhNKZHuKgFY0IMAlBYiWKAAA7" alt="" />表示的是阶跃函数Sigmoid,其数学表达式为:

6. FM&SVM
SVM的二元特征交叉参数是独立的,而FM的二元特征交叉参数是两个维的向量,交叉参数并不独立,两者相互影响。
FM可以在原始形式下进行优化学习,而基于核的非线性SVM通常需要在对偶形式下优化学习。
FM的模型预测与训练样本独立,而SVM则与训练样本有关(支持向量)。
7. 交叉项核心代码
v = normalvariate(0, 0.2) * ones((n, k)) #初始化隐向量
inter_1 = dataMatrix[x] * v
inter_2 = multiply(dataMatrix[x], dataMatrix[x]) * multiply(v, v) #multiply对应元素相乘
interaction = sum(multiply(inter_1, inter_1) - inter_2) / 2. #完成交叉项
p = w_0 + dataMatrix[x] * w + interaction #计算预测的输出
Time : 2019-10-14 09:39:44
CTR@因子分解机(FM)的更多相关文章
- 因子分解机 FM
特征组合 人工方式的特征工程,通常有两个问题: 特征爆炸 大量重要的特征组合都隐藏在数据中,无法被专家识别和设计 针对上述两个问题,广度模型和深度模型提供了不同的解决思路. 广度模型包括FM/FFM等 ...
- 推荐算法之因子分解机(FM)
在这篇文章我们将介绍因式分解机模型(FM),为行文方便后文均以FM表示.FM模型结合了支持向量机与因子分解模型的优点,并且能够用了回归.二分类以及排序任务,速度快,是推荐算法中召回与排序的利器.FM算 ...
- Factorization Machine因子分解机
隐因子分解机Factorization Machine[http://www. w2bc. com/article/113916] https://my.oschina.net/keyven/blog ...
- 万字长文,详解推荐系统领域经典模型FM因子分解机
在上一篇文章当中我们剖析了Facebook的著名论文GBDT+LR,虽然这篇paper在业内广受好评,但是毕竟GBDT已经是有些老旧的模型了.今天我们要介绍一个业内使用得更多的模型,它诞生于2010年 ...
- FM解析(因子分解机,2010)
推荐参考:(知乎) https://zhuanlan.zhihu.com/p/37963267 要点理解: 1.fm应用场景,为什么提出了fm(和lr的不同点) ctr预测,特征组合,fm的隐向量分解 ...
- fm 讲解加代码
转自: 博客 http://blog.csdn.net/google19890102/article/details/45532745/ github https://github.com/zhaoz ...
- 聊聊推荐系统,FM模型效果好在哪里?
本文始发于公众号:Coder梁 大家好,我们今天继续来聊聊推荐系统. 在上一回当中我们讨论了LR模型对于推荐系统的应用,以及它为什么适合推荐系统,并且对它的优点以及缺点进行了分析.最后我们得出了结论, ...
- Factorization Machine算法
参考: http://stackbox.cn/2018-12-factorization-machine/ https://baijiahao.baidu.com/s?id=1641085157432 ...
- 3.1、Factorization Machine模型
Factorization Machine模型 在Logistics Regression算法的模型中使用的是特征的线性组合,最终得到的分隔超平面属于线性模型,其只能处理线性可分的二分类问题,现实生活 ...
随机推荐
- JavaScript 面向对象编程 · 理解对象
前言: 在我们深入 面向对象编程之前 ,让我们先理解一下Javascript的 对象(Object),我们可以把ECMAScript对象想象成散列表,其值无非就是一组名值对,其中值可以是数据 ...
- 一个原生JS实现的不太成熟的贪吃蛇游戏
一个初初初初级前端民工 主要是记录一下写过的东西,复习用 大佬们如果看到代码哪里不符合规范,或者有更好写法的,欢迎各位批评指正 十分感谢 实现一个贪吃蛇游戏需要几步? 1.有地图 2.有蛇 3.有食物 ...
- Nginx+Tomcat Https SSL部署方案
1.软件版本: nginx-1.15+ tomcat-8.0+ 2.先解决一个疑问:Tomcat到底需不需要配置SSL? 答案:不需要 3.SSL申请 使用腾讯云.阿里云的服务器,会更加方便申请.(申 ...
- ping本地局域网
#!/bin/bash for i in `seq 1 254` do ping -c 1 192.168.192.$i > /dev/null if [ $? -eq 0 ];then ech ...
- Spring Boot (十一): Spring Boot 定时任务
在实际的项目开发工作中,我们经常会遇到需要做一些定时任务的工作,那么,在 Spring Boot 中是如何实现的呢? 1. 添加依赖 在 pom.xml 文件中只需引入 spring-boot-sta ...
- 人生,还没困难到"非死不可"
最近半个月,美国著名的Facebook公司,出了好几件大事.第一件事,2019年9月19日,一名陈姓中国软件工程师在Facebook加州总部跳楼自杀.第二件事,2019年10月4日,一名软件工程师在座 ...
- springboot+thymeleaf国际化方法一:LocaleResolver
springboot中大部分有默认配置所以开发起项目来非常迅速,仅对需求项做单独配置覆盖即可 spring采用的默认区域解析器是AcceptHeaderLocaleResolver,根据request ...
- B-概率论-常见的概率分布模型
目录 常见的概率分布模型 一.离散概率分布函数 二.连续概率分布函数 三.联合分布函数 四.多项分布(Multinomial Distribution) 4.1 多项分布简介 4.2 多项分布公式解析 ...
- java架构之路-(Redis专题)Redis的高性能和持久化
上次我们简单的说了一下我们的redis的安装和使用,这次我们来说说redis为什么那么快和持久化数据 在我们现有的redis中(5.0.*之前的版本),Redis都是单线程的,那么单线程的Redis为 ...
- 爬虫2:html页面+beautifulsoap模块+post方式+demo
爬取html页面,有时需要设置参数post方式请求,生成json,保存文件中. 1)引入模块 import requests from bs4 import BeautifulSoup url_ = ...