药店商品销量分析(python)
一、数据分析的步骤
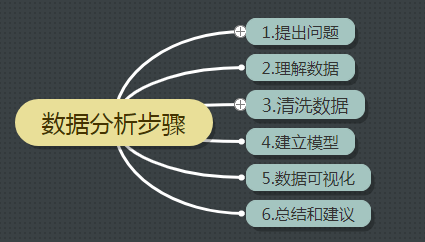
二、提出问题
分析药店商品销售情况
1)月均消费次数
2)月均消费金额
3)客单价
4)消费趋势
5)热销商品、滞销商品
三、理解数据

销售数据源为excel文件
字段的含义:
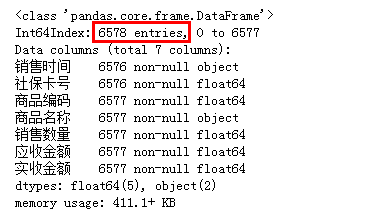
共有6579条销售数据
共有7个字段分别为:购买时间、社保卡号、商品编码、商品名称、销售数量、应收金额、实收金额
四、清洗数据

本次分析采用Jupyter Notebook分析,数据集为本地excel文件
(1)选择子集
本次分析的excel工作簿里面只有一个工作表
#导入数据分析包
import pandas as pd
salesDf = pd.read_excel('./朝阳医院2018年销售数据.xlsx')
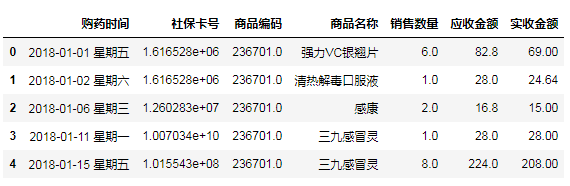
# head()打印前5行
# df = pd.read_excel(path,sheet_name=4,header=6)# 指定序号为4的工作簿,用第6行做为行索引
"""sheet_name,工作簿的序号从0开始 """
#header从0开始计数
print(salesDf.head())
(2)列表重命名
#字典:旧列名和新列名对应关系
colNameDict = {'购药时间':'销售时间'} '''
inplace=False,数据框本身不会变,而会创建一个改动后新的数据框,
默认的inplace是False
inplace=True,数据框本身会改动
'''
salesDf.rename(columns = colNameDict,inplace=True)
salesDf.head()
(3)删除重复值
print('删除重复值前大小',salesDf.shape)
# 删除重复销售记录
salesDf = salesDf.drop_duplicates()
print('删除重复值后大小',salesDf.shape)
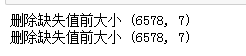
删除前后数据进行对比,发现本数据集没有重复值
(4)缺失值处理 info也可以查看字段的数据类型
"""整体观察"""
df.info()
"""如果缺失的数据很少,可以直接进行删除"""
"""如果缺失的数据量较大,超过了10%,要根据业务情况,进行删除或填充"""
"""填充数据时,可以采用均值,中位数进行填充"""
"""如果数据记录之间有明显的顺序关系,可以采用附近相邻的数据进行填充"""
总共有6578行数据只有2个缺失值,可以直接删除
"""删除缺失值"""
df.dropna()# 删除出现缺失值得行
# df.dropna(axis=1) df.dropna(how='all') # 当整行数据都为nan 时才删除
df.dropna(how='any') # 只要出现缺失值就删除
df.dropna(subset=['房价'])# 指定列出现缺失值才删除
print('删除缺失后大小',salesDf.shape)
# 查询是否有空值
print(salesDf.isnull().any())

处理后,结果显示没有缺失值
(5)一致化处理
#查看每一列的数据类型
salesDf.dtypes

只需要将销售时间改为:字符串转换为日期数据类型
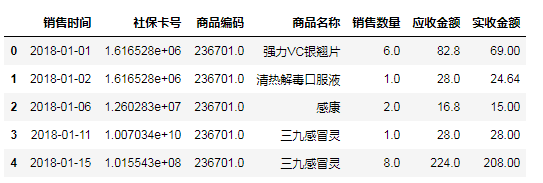
#获取“销售时间”这一列
timeSer=salesDf.loc[:,'销售时间']
#对字符串进行分割,获取销售日期
timeList=[]
for value in timeSer:
#例如2018-01-01 星期五,分割后为:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr) #将列表转行为一维数据Series类型
timeSer=pd.Series(timeList)
print(timeSer.head())

#修改销售时间这一列的值
salesDf.loc[:,'销售时间']=dateSer
salesDf.head()
'''
数据类型转换:字符串转换为日期
'''
#errors='coerce' 如果原始数据不符合日期的格式,转换后的值为空值NaT
#format 是你原始数据中日期的格式
salesDf.loc[:,'销售时间']=pd.to_datetime(salesDf.loc[:,'销售时间'],
format='%Y-%m-%d',
errors='coerce')
# 查询是否有空值
print(salesDf.isnull().any())
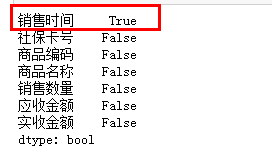
'''
转换日期过程中不符合日期格式的数值会被转换为空值,
这里删除列(销售时间)中为空的行
'''
salesDf=salesDf.dropna(subset=['销售时间'],how='any') # 查询是否有空值
print(salesDf.isnull().any())

(6)数据排序
按照销售时间进行排序
'''
by:按哪几列排序
ascending=True 表示升序排列,
ascending=True表示降序排列
na_position=first表示排序的时候,把空值放到前列,这样可以比较清晰的看到哪些地方有空值
官网文档:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html
'''
#按销售日期进行升序排列
salesDf=salesDf.sort_values(by='销售时间',
ascending=True,
na_position='first')
print('排序后的数据集')
salesDf.head(3)

#重命名行名(index):排序后的列索引值是之前的行号,需要修改成从0到N按顺序的索引值
salesDf=salesDf.reset_index(drop=True)
salesDf.head()
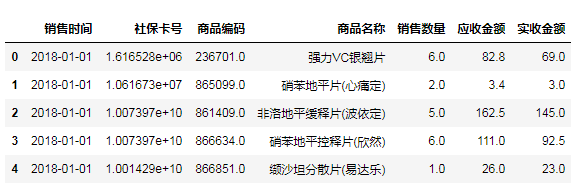
(7)异常值处理
#描述指标:查看出“销售数量”值不能小于0
salesDf.describe()
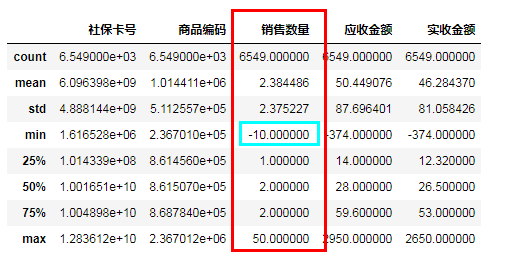
#删除异常值:通过条件判断筛选出数据
#查询条件
querySer=salesDf.loc[:,'销售数量']>0
#应用查询条件
print('删除异常值前:',salesDf.shape) # 筛选数据 salesDf=salesDf.loc[querySer,:] print('删除异常值后:',salesDf.shape)
print(salesDf.head())

五、构建模型
(1)业务指标1:月均消费次数=总消费次数 / 月份数
'''
总消费次数:同一天内,同一个人发生的所有消费算作一次消费
#根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除
''' kpi1_Df=salesDf.drop_duplicates(
subset=['销售时间', '社保卡号']
) #总消费次数:有多少行
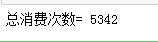
# shape几行几列
totalI=kpi1_Df.shape[0] print('总消费次数=',totalI)
'''
计算月份数:时间范围
'''
#第1步:按销售时间升序排序
kpi1_Df=kpi1_Df.sort_values(by='销售时间',
ascending=True)
#重命名行名(index)
kpi1_Df=kpi1_Df.reset_index(drop=True)
#第2步:获取时间范围
#最小时间值
startTime=kpi1_Df.loc[0,'销售时间']
#最大时间值 totallI总行数
endTime=kpi1_Df.loc[totalI-1,'销售时间'] #第3步:计算月份数
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
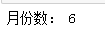
monthsI=daysI//30
print('月份数:',monthsI)
#业务指标1:月均消费次数=总消费次数 / 月份数
kpi1_I=totalI // monthsI
print('业务指标1:月均消费次数=',kpi1_I)
业务指标1:月均消费次数= 890
(2)指标2:月均消费金额 = 总消费金额 / 月份数
#总消费金额
totalMoneyF=salesDf.loc[:,'实收金额'].sum()
#月均消费金额
monthMoneyF=totalMoneyF / monthsI
print('业务指标2:月均消费金额=',monthMoneyF)
业务指标2:月均消费金额= 50668.35166666666
(3)指标3:客单价=总消费金额 / 总消费次数
'''
totalMoneyF:总消费金额
totalI:总消费次数
'''
pct=totalMoneyF / totalI
print('客单价:',pct)
客单价: 56.909417821040805
(4)指标4:消费趋势,画图:折线图
#在进行操作之前,先把数据复制到另一个数据框中,防止对之前清洗后的数据框造成影响
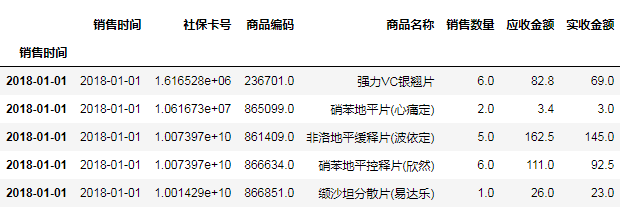
groupDf=salesDf
#第1步:重命名行名(index)为销售时间所在列的值
groupDf.index=groupDf['销售时间']
groupDf.head()
#第2步:分组 print(groupDf.index.month)
gb=groupDf.groupby(groupDf.index.month)

# Pandas 无法显示中文问题 解决方案##
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import matplotlib.pyplot as plt
ax = data_mounth.plot(
secondary_y=['销售数量'],
x_compat=True,
grid=True,figsize=(10,4))
ax.right_ax.set_ylabel('销售数量')
ax.set_ylabel(['应收金额','实收金额'])
#ax.set_ylabel()
plt.show()
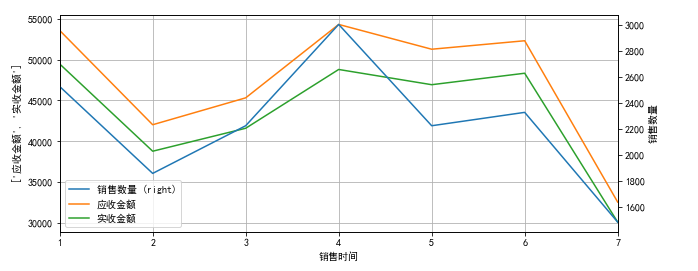
(5)热销商品、滞销商品
product = salesDf.groupby('商品名称').count()
#print(product)
# print(type(product))
sum_product = product.loc[:,'销售数量']
# print(sum_product)
# 可以看出商品整体的销量情况
print(sum_product.sort_values(ascending=True))


六、总结和建议
药店商品销量分析(python)的更多相关文章
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- Kaggle 商品销量预测季军方案出炉,应对时间序列问题有何妙招
https://www.leiphone.com/news/201803/fPnpTdrkvUHf7uAj.html 雷锋网 AI 研习社消息,Kaggle 上 Corporación Favorit ...
- 电商打折套路分析 —— Python数据分析练习
电商打折套路分析 ——2016天猫双十一美妆数据分析 数据简介 此次分析的数据来自于城市数据团对2016年双11天猫数据的采集和整理,原始数据为.xlsx格式 包括update_time/id/tit ...
- B2C电子商务系统研发——商品SKU分析和设计(二)
转:http://www.cnblogs.com/winstonyan/archive/2012/01/07/2315886.html 上文谈到5种商品SKU设计模式,本文将做些细化说明. 笔者研究过 ...
- 让ecshop显示商品销量或者月销量
首先,ecshop的信息显示模块在. ./includes/lib_goods.php文件 在其末尾添加下面这个函数 月销量:(和总销量二选一) function ec_buysum($goods_i ...
- ecshop获取商品销量函数
以下函数会获取订单状态为已完成的订单中该商品的销量,此函数放在lib_goods.php文件中即可调用 /** * 获取商品销量 * * @access public * @param ...
- arp协议分析&python编程实现arp欺骗抓图片
arp协议分析&python编程实现arp欺骗抓图片 序 学校tcp/ip协议分析课程老师布置的任务,要求分析一种网络协议并且研究安全问题并编程实现,于是我选择了研究arp协议,并且利用pyt ...
- [深度分析] Python Web 开发框架 Bottle
[深度分析] Python Web 开发框架 Bottle(这个真的他妈的经典!!!) 作者:lhf2009913 Bottle 是一个非常精致的WSGI框架,它提供了 Python Web开发中需要 ...
随机推荐
- Mysql中事务ACID实现原理
引言 照例,我们先来一个场景~ 面试官:"知道事务的四大特性么?"你:"懂,ACID嘛,原子性(Atomicity).一致性(Consistency).隔离性(Isola ...
- C#开发BIMFACE系列20 服务端API之获取模型数据5:批量获取构件属性
系列目录 [已更新最新开发文章,点击查看详细] 在<C#开发BIMFACE系列18 服务端API之获取模型数据3:获取构件属性>中介绍了获取单个文件/模型的单个构建的属性,本篇介绍 ...
- 一文学会 TypeScript 的 82% 常用知识点(下)
一文学会 TypeScript 的 82% 常用知识点(下) 前端专栏 2019-11-23 18:39:08 都已经 9021 年了,TypeScript(以下简称 TS)作为前端工程师不得 ...
- 【MySQL报错】ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot exec ...
- 03-模板(过滤器,代码复用,表单,CSRF)
模块代码复用 在模板中,可能会遇到以下情况: 多个模板具有完全相同的顶部和底部内容 多个模板中具有相同的模板代码内容,但是内容中部分值不一样 多个模板中具有完全相同的 html 代码块内容 像遇到这种 ...
- python3在mac下配置
目的 https://github.com/VonSdite/Plane_Wars 可以本地跑起来. 下载并安装python3 https://www.python.org/downloads/mac ...
- MVC过滤器:自定义异常过滤器使用案例
在上一篇文章中讲解了自定义异常过滤器,这篇文章会结合工作中的真实案例讲解一下如何使用自定义异常过滤器. 一.需求 本案例要实现的功能需求:在发生异常时记录日志,日志内容包括发生异常的Controlle ...
- python处理oracle数据库的返回数据
上代码: import SqlHelper.ORACLE as ORA import pandas as pd if __name__ == '__main__': #连接数据库 ms = ORA.O ...
- NetCore 下使用 DataTable 以及可视化工具
DtatTable 在命名空间System.Data下,NetCore2.0及以上支持.但是2017DataTable没有可视化工具,我也没有深研究直接下载的VS2019.然后在网上早了个SQLHel ...
- vue-基本动画
不使用动画 <div id="app"> <input type="button" value="toggle" @cli ...