happen before 原则
并发一直都是程序开发者绕不开的难题,在上一篇文章中我们知道了导致并发问题的源头是 : 多核 CPU 缓存导致程序的可见性问题、多线程间切换带来的原子性问题以及编译优化带来的顺序性问题。
原子性问题我们暂且不谈,Java 中有足够健壮的锁机制来保证程序的原子性,后面学习的重点也是在这方面。今天我们就先来看看 Java 是怎么解决可见性与顺序性问题的。
合理的建议是 按需禁用缓存与编译优化,但是怎么才算是按需禁用呢?这就要具体问题具体分析了。Java 内存模型也规定了 JVM 如何按需提供禁用缓存与编译优化的方法,这些方法就是 volatile、syncronized、final 三个关键字与 happen-before 原则。
volatile
volatile 其实是一种稍弱的同步机制,在并发场景下它并不能保证线程安全。
加锁机制既可以保证可见性又可以保证原子性,而 volatile 变量则只能保证可见性。
在 jdk1.5 之前 volatile 给我们最深刻的印象就是 禁用缓存,即每次读写都是直接操作内存(不是 CPU 缓存),从内存中取值。Java 从 jdk1.5 开始对 volatile 进行了优化, 我们先来看下面的例子,再讨论优化了什么和怎么优化的。
假设有线程 A 和线程 B,A 线程调用 write(),将 flag 赋值为 true,B 线程调用 read() ,根据 volatile 定义变量的可见性,B 线程中 flag 为 true 所以会进入if 判断,那么此时的输出 index 的值是多少呢?
class VolatileTest{
int index = 0;
volatile boolean flag = false;
public void write(){
index = 10;
flag = true;
}
public void read(){
if(flag){
System.out.println(index);
}
}
}
这个问题在 jdk1.5 之前,显示的结果可能为 0,也可能为 10,原因在于 CPU 缓存导致的可见性问题,flag 是可以保证可见性,但是 index 却无法保证,当 A 线程执行完写进 CPU 缓存还没有更新的内存时,此时 B 线程读出的 index 值就是 0。
为了解决上述问题,从 jdk1.5 开始对 volatile 修饰的变量进行了优化, 在 jdk1.5 以后 此时 index 输出结果就是 10 。
到底是怎么优化的呢? 答案是 happen-before 原则中的传递性规则。
happen before 原则
happen before 并不是字面的英文的意思,想要理解它必须知道 happen before 的含义,它真正的意思是前面的操作对后续的操作都是可见的,比如 A happen before B 的意思并不是说 A 操作发生在 B 操作之前,而是说 A 操作对于 B 操作一定是可见的。
知道了它的意思,我们再来看一下 happen before 原则中与开发相关的几项规则:
程序的顺序性规则
这条规则很简单,也符合我们常规的思维,就是说在一个线程中程序的执行顺序,前面的操作对后面的操作是可见的,同样是上面的代码,在执行 write() 方法时,index = 10 对 flag = true 是可见的,如下 :
class VolatileTest{
int index = 0;
volatile boolean flag = false;
public void write(){
index = 10; // index 赋值 对 flag 是可见的
flag = true;
}
public void read(){
if(flag){
System.out.println(index);
}
}
}
volatile 变量规则
volatile 修饰的变量,对该变量的写操作一定可见于对该变量的读操作。
同样是上面的代码,A 线程执行 write() 为 flag 变量赋值为 true,B 线程执行 read() 方法,那么此时的 flag 一定为true,与 A B 线程执行顺序无关。
传递性
传递性就是 jdk1.5 之后对 volatile 语义的增强。啥叫传递性呢 ?
举个简单的数学比大小的例子,你就明白了。
有 a、b、c 三个数,如果 a > b, b > c, 那么由传递性可知 a > c。
这里的传递性的意思与例子类似, A 操作 happen before 于 B 操作,B 操作 happen before 于 C 操作,那么 A 操作 happen before 于 C 操作。同样是上面的代码,我们来解释下为什么 在 jdk1.5 之后 B 线程执行 read() 方法打印的结果一定为 10 呢?如图:
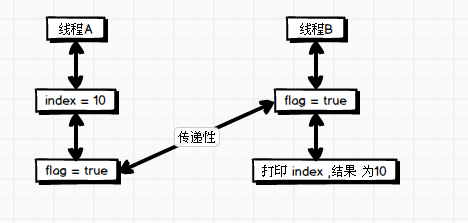
根据第一条程序的顺序性规则可知,A线程中 index = 10 对 flag = true 可见;
根据第二条 volatile 规则可知,flag 使用 volatile 修饰的变量, A 线程 flag 写 对 B 线程 flag 的读可见;
综合以上两条规则:
index = 10 happen before 于 flag 的写 ,
A 线程 flag 的写 happen before 于 B 线程 flag 的读,
根据传递性 , A 线程 对 index 的写 happen before 于 B 线程 对 flag 的读。所以 A 线程对 index 变量的写操作对 B 线程 flag 变量的读操作是可见的,即 B 线程读取 index 的打印结果为 10 。
管程中锁的规则
管程是一种通用的同步原语,管程在 java 中指的就是 syncronized。这条规则说的是 线程的解锁 happen before 于对这个线程的加锁。
也就是说线程的解锁对线程的加锁是可见的,那么在一个线程中操作的变量,在这个线程解锁后,根据传递性规则,当另一个线程加锁的时候,就会读到上一个线程对这个变量的操作后的新值。
线程的 start 规则
A 线程中调用 B 线程的 start(), 则 start() 操作 happen before 于 B 线程所有操作,也就是说 A 线程调用 start() 操作前对共享变量的赋值,对 B 线程可见,即在 B 线程中能获取 A 对到共享变量操作后的新值。
线程的 join 规则
A线程中调用B线程的 join() 操作,如果成功返回 则 B的所有操作对 join() 结果的返回一定是可见的,即在 A 线程能获取到 B 对共享变量操作后的新值。
除了以上列举几条规则,happen before 还有些其他的规则,在开发中不常用到,这里我们就不一一列举了。其实 Java 内存模型大体可以分为两部分,一部分是编写并发程序的开发人员,另一部分是 面向JVM 的实现人员 。当然我们更关注前者,而前者的核心就是 happen before 原则,常用的就是上面我们列举的原则,了解这些也就可以了。
在编译器优化方面使用的最多的就是 final 了, final 修饰变量就是常量,因此编译器可以使劲的优化,在 jdk1.5 以后 Java 内存模型对 final 类型变量的重排进行了约束。现在只要我们提供正确构造函数没有“逸出”,就不会出问题了。
总结:
happen before 原则核心就是可见性,并不是说 一个操作发生在另一个操作前面,它真正要表达的是:前面一个操作的结果对后续操作是可见的。
参考资料 : 《JAVA 并发编程实战》
happen before 原则的更多相关文章
- jvm(三)指令重排 & 内存屏障 & 可见性 & volatile & happen before
参考文档: https://tech.meituan.com/java-memory-reordering.html http://0xffffff.org/2017/02/21/40-atomic- ...
- Java集合---ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- Java并发集合的实现原理
本文简要介绍Java并发编程方面常用的类和集合,并介绍下其实现原理. AtomicInteger 可以用原子方式更新int值.类 AtomicBoolean.AtomicInteger.AtomicL ...
- java并发编程(十六)happen-before规则
转载请注明出处:http://blog.csdn.net/ns_code/article/details/17348313 happen-before规则介绍 Java语言中有一个"先行发生 ...
- 深入分析ConcurrentHashMap
术语定义 哈希算法 hash algorithm 是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值. 哈希表 hash table 根据设定的哈希函数H(key)和处理冲突方 ...
- 并发编程 02—— ConcurrentHashMap
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- 深入分析ConcurrentHashMap(转)
线程不安全的HashMap 因为多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap,如以下代码 final HashMap ...
- ConcurrentHashMap总结
线程不安全的HashMap 因为多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap,如以下代码 final HashM ...
- 转:【Java并发编程】之十六:深入Java内存模型——happen-before规则及其对DCL的分析(含代码)
转载请注明出处:http://blog.csdn.net/ns_code/article/details/17348313 happen-before规则介绍 Java语言中有一个"先行发生 ...
随机推荐
- 3、K-近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法 1.定义:如果一个样本在特征空间中的k个最近似(即特征空间中最临近)的样本中大多数属于某一类别,则该样本也属于这个类别. 2.计算公式 ...
- iview自定义实现多级表头
最近更新: 2018-07-19 注意:最新版iview已经提供多级表头功能 参考 原理:利用多个Table组件通过显示和隐藏thead和tbody来拼接表格(较粗暴) html <div st ...
- Linux文件及目录管理
1.Linux文件目录树 /:根目录,linux文件系统的最顶端和入口 bin:存放用户二进制文件(如:ls,cd,mv等),实则/user/bin的硬链接(相当于Windows系统的快捷方式) bo ...
- .Net Core2.1 秒杀项目一步步实现CI/CD(Centos7.2)系列一:k8s高可用集群搭建总结以及部署API到k8s
前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署的,这个集群差不多搞了一周时间,关于k8s的知识点,我也是刚入门,这方面的知识建议参考博客园 ...
- django报错信息解决方法
You have 17 unapplied migration(s). Your project may not work properly until you apply the migration ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第4章 栈
定场诗 金山竹影几千秋,云索高飞水自流: 万里长江飘玉带,一轮银月滚金球. 远自湖北三千里,近到江南十六州: 美景一时观不透,天缘有分画中游. 前言 本章是重读<学习JavaScript数据结构 ...
- 关于c++中的复合类型
目录 数组 字符串 结构体 共用体 枚举 指针 数和指针的关系 常见的存储方式 数组替代品 一.数组 存储在每个元素中值的类型 数组名 数组中的元素数 通用格式:typename arrayname ...
- springboot+mybatis+druid+atomikos框架搭建及测试
前言 因为最近公司项目升级,需要将外网数据库的信息导入到内网数据库内.于是找了一些springboot多数据源的文章来看,同时也亲自动手实践.可是过程中也踩了不少的坑,主要原因是我看的文章大部分都是s ...
- ZooKeeper实现读写锁
在上一篇文章,我们已经实现了分布式锁.今天更进一步,在分布式锁的基础之上,实现读写锁. 完整代码在 https://github.com/SeemSilly/codestory/tree/master ...
- 用代码说话:synchronized关键字和多线程访问同步方法的7种情况
synchronized关键字在多线程并发编程中一直是元老级角色的存在,是学习并发编程中必须面对的坎,也是走向Java高级开发的必经之路. 一.synchronized性质 synchronized是 ...