Python数据分析 之时间序列基础
1. 时间序列基础
import numpy as np
import pandas as pd
np.random.seed(12345)
import matplotlib.pyplot as plt
plt.rc('figure', figsize=(10, 6))
PREVIOUS_MAX_ROWS = pd.options.display.max_rows
pd.options.display.max_rows = 20
np.set_printoptions(precision=4, suppress=True)
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series:
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
这些datetime对象实际上是被放在一个DatetimeIndex中的:
ts.index

跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对 齐:
print(ts[::2]) #每隔一个取一个
ts + ts[::2]
pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳:
ts.index.dtype
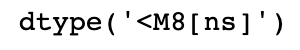
DatetimeIndex中的各个标量值是pandas的Timestamp对象:
stamp = ts.index[0]
stamp
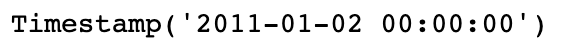
只要有需要,TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话),且知道如何执行时区转换以及其他操作。 之后将对此进行详细讲解。
2. 索引、选取、子集构造
当你根据标签索引选取数据时,时间序列和其它的pandas.Series很像:
print(ts)
stamp = ts.index[2]
print(ts[stamp]) #标签索引
print(ts[2]) #整数索引
还有一种更为方便的用法:传入一个可以被解释为日期的字符串:
print(ts['1/10/2011'])
print(ts['20110110'])
ts['2011-01-10']

对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
longer_ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))#天为单位
longer_ts
longer_ts['2001']
这里,字符串“2001”被解释成年,并根据它选取时间区间。指定月也同样奏效:
longer_ts['2001-05']
datetime对象也可以进行切片:
print(ts)
ts[datetime(2011, 1, 7):]
由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询):
ts['1/6/2011':'1/11/2011']

跟之前一样,你可以传入字符串日期、datetime或Timestamp进行索引。注意,这样 切片所产生的是原时间序列的视图(共享内存),跟NumPy数组的切片运算是一样的。
这意味着,没有数据被复制,对切片进行修改会反映到原始数据上。
此外,还有一个等价的实例方法也可以截取两个日期之间TimeSeries:
ts.truncate(after='1/9/2011')无锡妇科医院哪家好 http://www.xasgyy.net/

这些操作对DataFrame也有效。例如,对DataFrame的行进行索引:
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED') #间隔单位为周
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas',
'New York', 'Ohio'])
long_df.loc['5-2001']
3. 带有重复索引值的时间序列
在某些应用场景中,可能会存在多个观测数据落在同一个时间点上的情况。下面就是一个例子:
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
'1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts

通过检查索引的is_unique属性,我们就可以知道它是不是唯一的:
dup_ts.index.is_unique
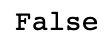
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复:
print(dup_ts['1/3/2000'])# not duplicated
dup_ts['1/2/2000'] # duplicated
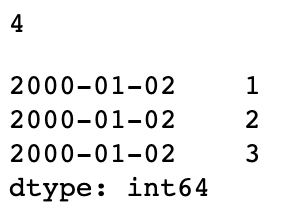
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法是使用 groupby,并传入level=0:
grouped = dup_ts.groupby(level=0)
print(grouped.mean())
grouped.count()
Python数据分析 之时间序列基础的更多相关文章
- 第一章:Python数据分析前的基础铺垫
本节概要 - 数据类型 - 数据结构 - 数据的常用操作方法 数据类型 基础铺垫 定义 我们搞数据时,首先要告诉Python我们的数据类型是什么 数值型:直接写一个数字即可 逻辑型:True,Fals ...
- python数据分析02语法基础
在我来看,没有必要为了数据分析而去精通Python.我鼓励你使用IPython shell和Jupyter试验示例代码,并学习不同类型.函数和方法的文档.虽然我已尽力让本书内容循序渐进,但读者偶尔仍会 ...
- 零基础学习Python web开发、Python爬虫、Python数据分析,从基础到项目实战!
随着大数据和人工智能的发展,目前Python语言的上升趋势比较明显,而且由于Python语言简单易学,所以不少初学者往往也会选择Python作为入门语言. Python语言目前是IT行业内应用最为广泛 ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- 【Python数据分析】IPython基础
一.配置启动IPython 打开cmd窗口,在dos界面下输入ipython,结果报错了!!! 出现这个问题是由于环境变量未配置(前提:已经安装了ipython),那么接下来配置环境变量 我的电脑→右 ...
- Python数据分析 Pandas模块 基础数据结构与简介(二)
重点方法 分组:groupby('列名') groupby(['列1'],['列2'........]) 分组步骤: (spiltting)拆分 按照一些规则将数据分为不同的组 (Applying)申 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
随机推荐
- Comet OJ 夏季欢乐赛 距离产生美
距离产生美 https://cometoj.com/contest/59/problem/B?problem_id=2680 题目描述 JWJU放暑假了,于是鸡尾酒就和女朋友璇璇一起出去玩.但是外面太 ...
- UEditor在开发环境中正常运作,但是部署到Tomcat中却无法使用
背景 SpringBoot项目,在 JSP 中使用 UEditor 问题 UEditor 在开发环境中正常运作,但是导致部署到 Tomcat 中却无法使用 原因 在开发环境中,路径不够严谨,多 ...
- Seminar Schedule
Seminar Schedule (C2017 | 2019.9-12 | 3rd semester S0500783) *************************************** ...
- springcloud的Hystrix turbine断路器聚合监控实现(基于springboot2.02版本)
本文基于方志朋先生的博客实现:https://blog.csdn.net/forezp/article/details/70233227 一.准本工作 1.工具:Idea,JDK1.8,Maven3. ...
- dockerfile+docker-compose
Dockerfile 一.简介 1.1 dockerfile中常用的命令合集 1.2 docker build 基于dockerfile制作镜像的命令 docker build [OPTIONS] P ...
- varnish搭建cdn网络-------3.0.5版本
CDN分发网络CDN的全称是Content Delivery Network,即内容分发网络.其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快.更稳定.通过在 ...
- 出现:Microsoft Visual C++ 14.0 is required 的解决方案
以安装pandas为例: 如:pip install scrapy 时出现: error: Microsoft Visual C++ 14.0 is required. Get it with “Mi ...
- Notepad++ 【自动完成】与【输入时提示函数参数】互相冲突,无奈
Notepad++ 既然可以在输入时提示函数参数,可是当提示函数参数的时候,输入具体参数时[自动完成]失效了. 一位用户遇到和我一样的问题:https://community.notepad-plus ...
- SQL工具 Red Gate
Red Gate提供了很多对于sql server的工具. 这边介绍两个:Sql Prompt和Sql doc Sql Prompt:智能提示sql语句等等 Sql doc:生成数据库文档页面 Red ...
- nginx mysqlnd驱动引擎提升mysql性能
nginx mysqlnd驱动引擎提升mysql性能 前期要安装 mysql mysqli pdo_mysql libiconv 1 先去PHP官网下个 php-5.6.29.tar.gz wget ...