Learning Context Graph for Person Search
Learning Context Graph for Person Search
2019-06-24 09:14:03
Code: https://github.com/sjtuzq/person_search_gcn
Person Search Paper List: https://github.com/wangxiao5791509/Person-Search-Paper-List
1. Background and Motivation:
作者首先总结了现有的 re-ID 方法的挑战:
1). 现有的 re-ID 的设定(prob-gallery)是属于多模态的,例如:手机拍的照片和常规的低分辨率监控相机;
2). 不同的光照和行人姿态将会增加 intra-class variation;
3). 不准确的检测/跟踪,遮挡和复杂背景将会导致严重的外观变化,将会进一步增加 person re-ID 的难度。
紧跟着,作者开始基于上述挑战,引出 re-ID 的设定,在实际应用中存在的挑战。然后,引入 person search 这个课题。现有的 person search 的方法尝试将 context/group 信息用于解决实际问题,但是这些方法仍然有如下的不足:如何定义 group 是一个很重要的任务。有的方法尝试用手工标注的方式,但是这就需要额外的人力。其他的方法有尝试利用时空信息,如:场景中的速度和相对位置,来帮助 re-ID。作者认为这些 social force models 利用协同设计的约束来模拟场景中的社交影响力,并没有提供很好的解决方案,很难优化。
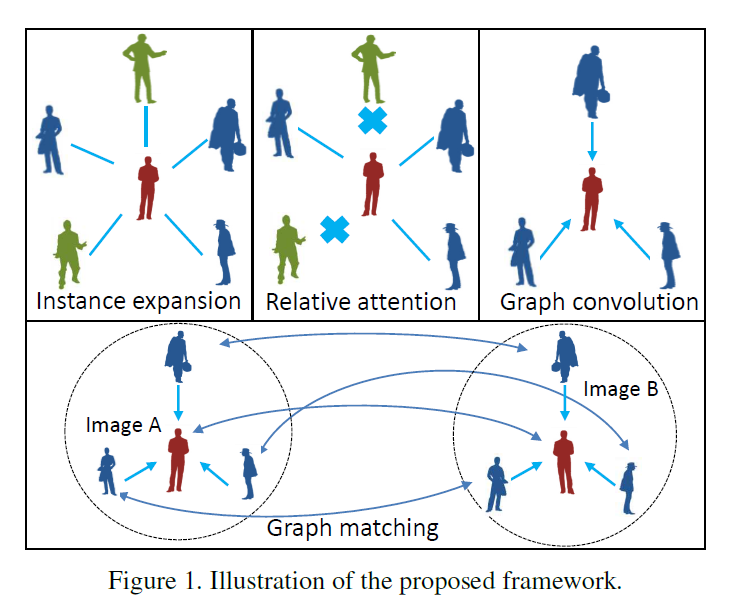
本文基于上述观察,提出一种新的利用 context 信息的方法,来解决 person search 的问题。首先从图像中产生很多 candidates,然后用 relative attention module 筛选出有用的图像对。在这些图像对上,构建 context graph 来建模 prob-gallery pairs 的全局相似性。图的节点是:target pair and context pairs。为了充分的利用 context 信息,作者将所有的 context nodes 都和 target nodes 进行相连。该 graph 输出的是 target pair 的相似性。
2. 算法总览:
本文的算法主要是由三个模块构成的,示意图如上图所示。
Instance Detection and Feature Learning: 在常规物体检测方法 Faster RCNN 的基础上,作者引入了 part-based feature learning,以得到更加具有判别性的表达。
Context Instance Expansion: 该模块是本文的核心,作者在 instance feature 的基础上进行拓展,引入 context information。Query 和 gallery 之间所有的 instance pairs 都被作为 context candidates,其中的 noise contexts 将会被过滤掉。这里就是采用简单的相似性度量的方法,仅将高置信度的 pairs 选出作为 information contexts。
Contextual Graph Representation Learning:这是另外一个核心的模块了,作者构建 graph 来考虑 target pairs 之间的相似性。通过 GCN 来学习 prob-gallery pair 之间的相似性。
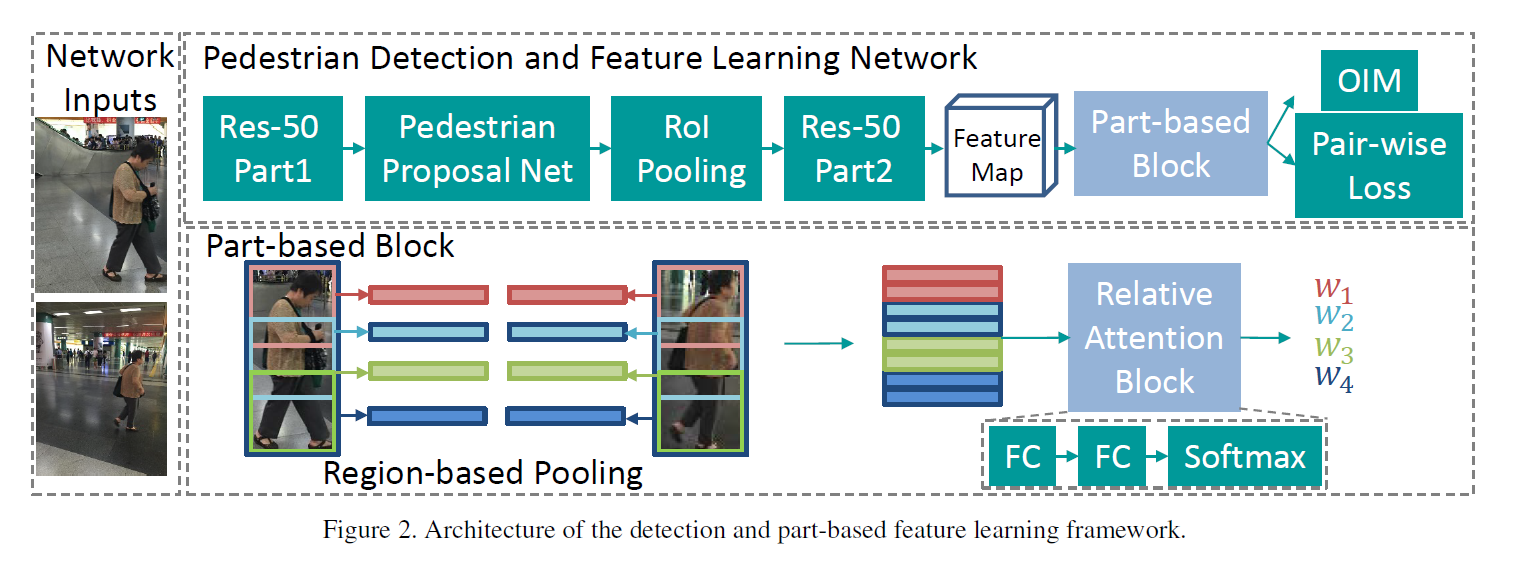
3. Instance Detection and Feature Learning :
作者将 ResNet-50 拆分成两个部分来用,前半部分用于 Pedestrian Proposal 的生成,后半部分用于 part-based feature learning。
关于 part-based feature learning,其实就是将行人划分 part,然后用 global pooling 和 local pooling 的方法得到更加具有判别性的 feature。这里的 global 和 local 分别是针对整个行人区域和行人的局部区域(本文考虑上肢,下肢,腹部三个区域)。
4. Context Instance Expansion:
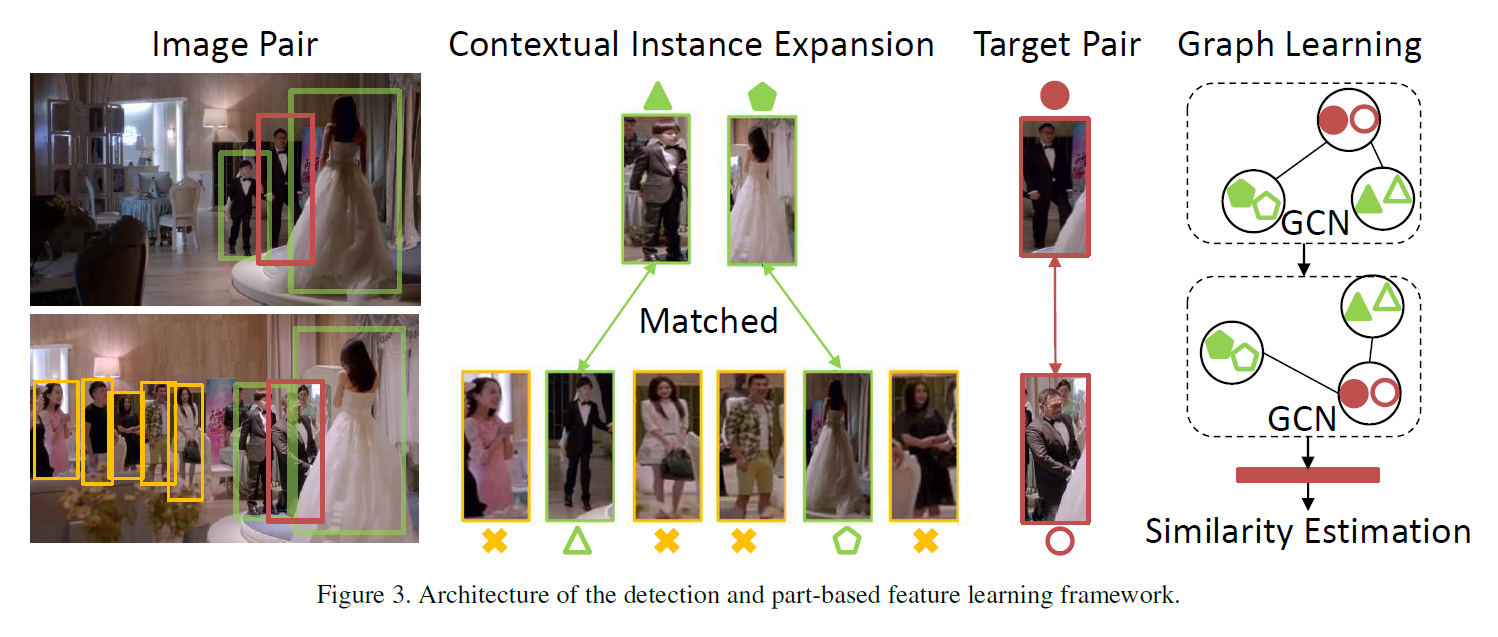
划重点!划重点!划重点!由于单独的 features 并不能很好的处理实际问题中 person retrieval 任务,作者提出利用 context information 的方法来作为互补信息。如上图所示,该示例图的目标是:判断红色 BBox 中的男人,是否属于同一个人。然而,由于不同场景下的外观变化,导致利用常规 feature 进行判断时,总不能很确信。在这个时候,作者观察到:the same persons in green BBox appear in both scenes, 所以可以更加确定的是红色的 BBox 的确是属于同一个人。为什么呢?因为这个时候,相当于用了排除法,利用 context 信息的比对,协助 target object 的对比,使其更加确定,就是同一个人。所以,绿色 BBox 里面的行人扮演了 positive 的角色,其他的人则是 noise contexts。在这个部分,作者提出 relative attention model 来过滤掉无法提供 positive contexts 的 pair。
一种直观的方法是直接计算不同 part 之间的 feature 距离,然后加和起来用于衡量相似度,然后设置一个阈值,得到二值结果,即:

但是这种加权的方法,并非是最优的解决方案。因为不同的 part 在不同的样本上,其贡献是不同的。所以,也有工作对其进行改善,Huang et al. 提出 instance region attention network (请参考:Huang, Qingqiu, Yu Xiong, and Dahua Lin. "Unifying identification and context learning for person recognition." CVPR-2018.) 来给不同的 parts 赋予不同的权重。紧跟着,作者的原文是:“The attention weights measure the instance-wise part contributions, and part similarity is multiplied by both parts’ attention weights.” 感觉跟公式 1 加权的思路一样啊,哪里有改进?等抽空看下这个文章再说吧。然后,作者注意到:part contributionos are not only related to sample itself, but are also related to the part to be matched。换句话说,part 的贡献是和 part pairs 相关的。受到该观测的启发,作者设计了 relative attention network 来考虑 pair-wise information 来预测 part weights。
具体来说,本文所提出的 relative attention network 是有 两个 fc 和 一个 softmax layer 构成的。该网络的输入是 4 pairs of feature vectors,Softmax layer 输出 4 个归一化后的 attention weights。为了训练该网络,采用了 cosine embedding verification loss。
5. Contextual Graph Representation Learning :
在本文中,作者引入 GCN 模型来学习结构化的信息。如下图所示:
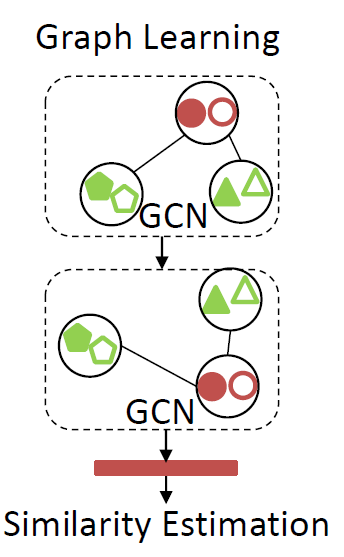
给定图像 A 和 B, 模型的主要目标是:判断给定的图像对是否是同一个 Identity。这里给定了红色标志的 target pairs,以及 绿色标志的 context pairs。目标就是要将这些样本结合到一个模型中,然后输出其相似性得分。具体来说,给定这些 feature 之后,可以构建一个 graph g = {V, E},其顶点就是 a pair of features, 其邻接矩阵 A 表示了 edge 的连接关系,其定义如下:
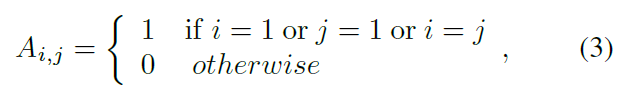
作者用 $\hat{A}$ 来表示归一化之后的邻接矩阵,layer-wise GCN 传递方式如下所示:
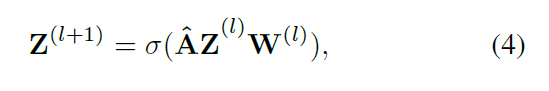
最终,作者用一层 fc 来融合所有的顶点特征为 1024-D 的特征向量。并且用一层 softmax loss layer 来进行监督的学习。
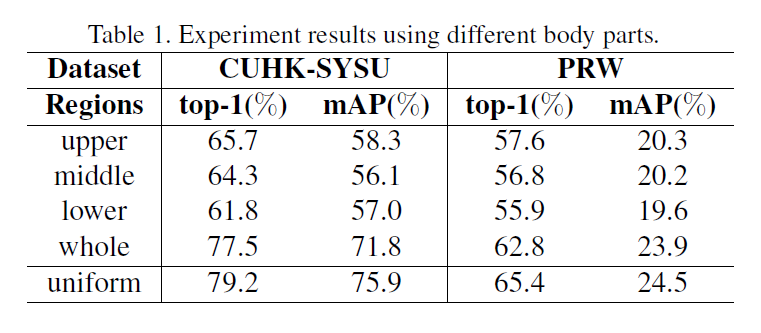
6. Experimental Results :

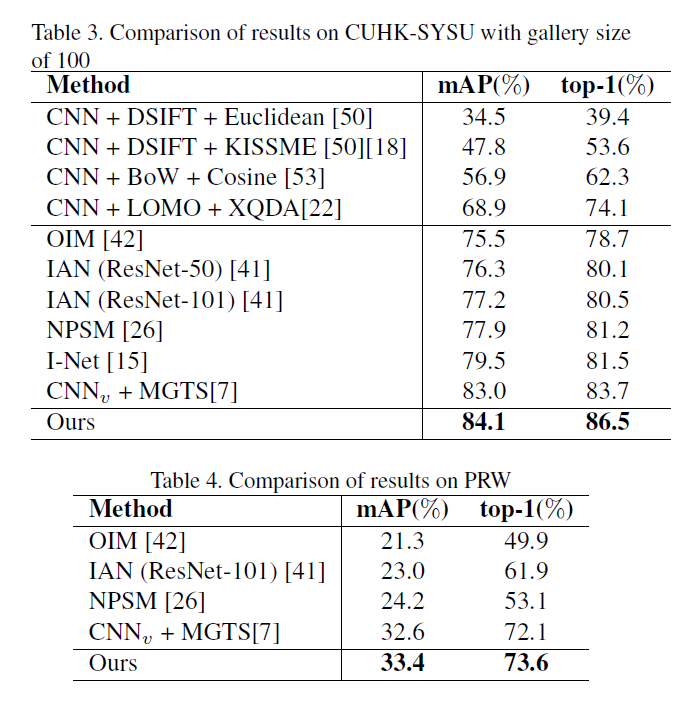
==
Learning Context Graph for Person Search的更多相关文章
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- 《Deep Learning of Graph Matching》论文阅读
1. 论文概述 论文首次将深度学习同图匹配(Graph matching)结合,设计了end-to-end网络去学习图匹配过程. 1.1 网络学习的目标(输出) 是两个图(Graph)之间的相似度矩阵 ...
- DAG-GNN: DAG Structure Learning with Graph Neural Networks
目录 概 主要内容 代码 Yu Y., Chen J., Gao T. and Yu M. DAG-GNN: DAG structure learning with graph neural netw ...
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
论文信息 论文标题:Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximiz ...
- 论文解读(GMT)《Accurate Learning of Graph Representations with Graph Multiset Pooling》
论文信息 论文标题:Accurate Learning of Graph Representations with Graph Multiset Pooling论文作者:Jinheon Baek, M ...
- Learning Latent Graph Representations for Relational VQA
The key mechanism of transformer-based models is cross-attentions, which implicitly form graphs over ...
- Learning Python 008 正则表达式-003 search()方法
Python 正则表达式 - search()方法 findall()方法在找到第一个匹配之后,还会继续找下去,findall吗,就是找到所有的匹配的意思.如果你只是想找到第一个匹配的信息后,就不在继 ...
- Deep Image Retrieval: Learning global representations for image search In ECCV, 2016学习笔记
- 论文地址:https://arxiv.org/abs/1604.01325 contribution is twofold: (i) we leverage a ranking framework ...
随机推荐
- 笔谈kxmovie开源播放器库的使用
开源播放器项目 kxmovie(https://github.com/kolyvan/kxmovie),现在仍然是很多刚开始接触播放器开发的程序员的参照范本.以下是我操作kxmovie项目的过程: ( ...
- 如何自行给指定的SAP OData服务添加自定义日志记录功能
有的时候,SAP标准的OData实现或者相关的工具没有提供我们想记录的日志功能,此时可以利用SAP系统强大的扩展特性,进行自定义日志功能的二次开发. 以SAP CRM Fiori应用"My ...
- 介绍一种在ABAP内核态进行内表高效拷贝的方法,和对应的Java和JavaScript版本的伪实现
内表操作是ABAP开发人员几乎在每个ABAP程序里都会遇到的. 看一个例子:有两个行结构不一样的内表,每个内表的行结构有三列,除了name这一列名字一致外,其他两列的名称都不同,下图用红色和蓝色标注出 ...
- matplotlib绘图难题解决
# coding=utf-8 import pandas as pd import yagmail import requests import arrow import numpy as np im ...
- 关于jupyter notebook密码设置
对于一个jupyter编辑器使用的新手,更换浏览器或者Logout后,需要输入密码进行登陆时 按照网上的教程怎么设置都不行,那么自己整理了一个适用于初学者的操作. 1.windows下,打开命令行,重 ...
- IDA7.0安装findcrypt插件
效果图附上 安装成功的话,快捷键Ctrl+Alt+F可以调出上图的窗口,识别一些常见的算法,上面识别出是Base64加密 插件链接放上:https://github.com/polymorf/find ...
- php将原数组倒序array_reverse()
1.数组倒序排列 $arr = array(1,2,3); $arr = array_reverse($arr); print_r($arr);
- svn: E155004: Working copy '/data/www' locked.
svn: run 'svn cleanup' to remove locks (type 'svn help cleanup' for details) svn: E155004: Working c ...
- layui开发的一些技巧
选择人员功能 //保存选择结果,用于回调 /* window.saveSelectTeachers = function () { //1.检查用户的最终选择是什么 var rule_course_i ...
- Spring源码窥探之:声明式事务
1. 导入驱动,连接池,jdbc和AOP的依赖 <!-- c3p0数据库连接池 --> <dependency> <groupId>c3p0</groupId ...