基于hive的《反贪风暴4》的影评
一:将爬虫大作业产生的csv文件上传到HDFS

查看文件中前10条信息,即可证明是否上传成功。
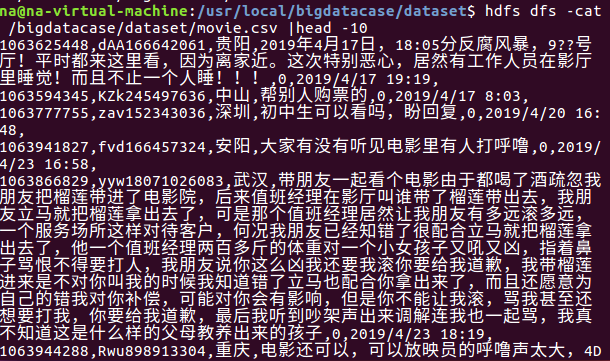
二.对CSV文件进行预处理生成无标题文本文件
创建一个deal.sh,主要实现数据分割成什么样的意思
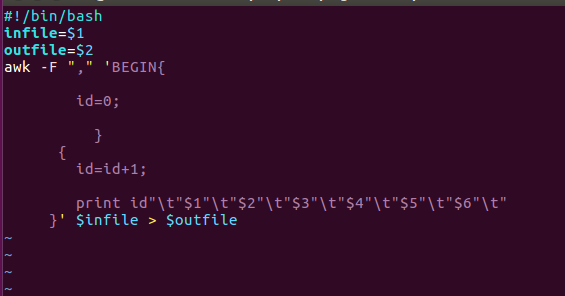
执行deal.sh 对数据进行分割预处理并输出形成movie.txt

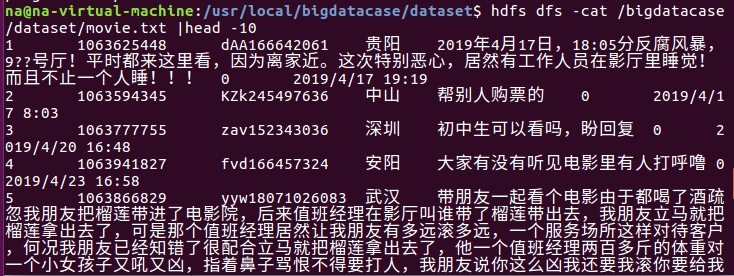
三.把hdfs中的文本文件最终导入到数据仓库Hive中

同样的,查看数据前10显示出来,和前面的csv对面显得很整齐,这就是处理数据后的样子。
四.在Hive中查看并分析数据
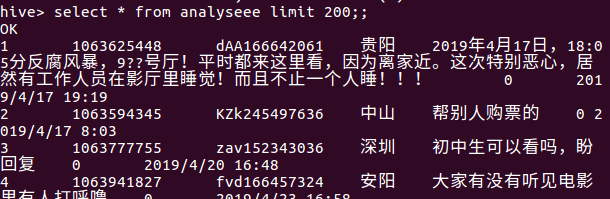
首先启动hive之后进行创建数据库再创表,语句如图下:

然后再查看一下数据,显示的数据格式正确即正确。
五.用Hive对爬虫大作业产生的进行数据分析
1.用户满意度分析:
在数据中分别获取评分为5,4,3,2,1的数量,然后进行分析,获取的数据如图所示:
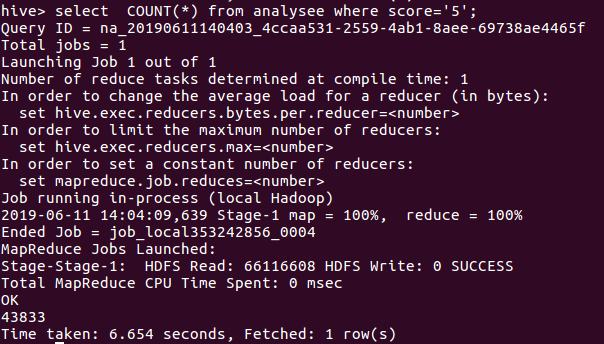
评分为5的数量

评分为4的数量
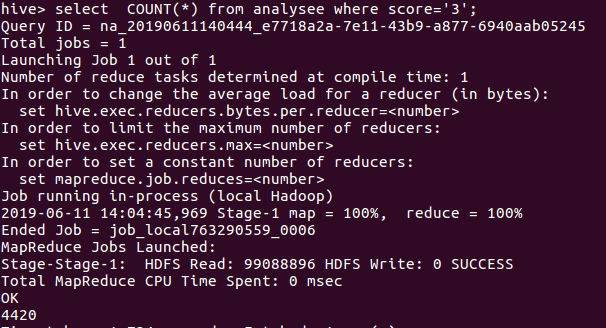
评分为3的数量

评分为2的数量

评分为1的数量
根据统计数据,做出了饼图,如图所示:
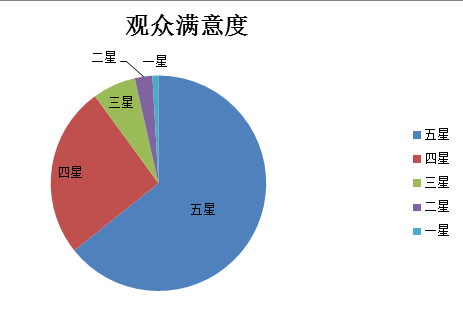
由图可以看出四星以上占据了大部分,于是我在计算一下影片的平均数,如图所示
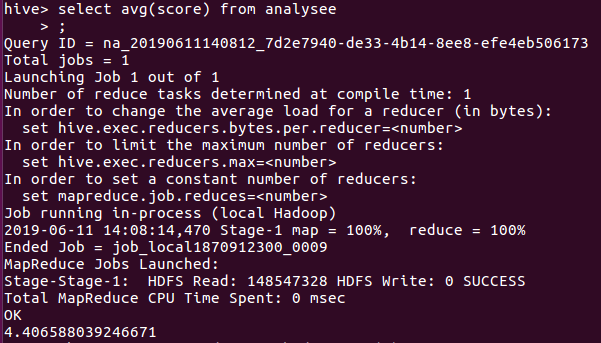
平均数为4.4左右,更加能够证明用户对该影片的满意度较高!
2.用户所在城市分析
统计出粉丝所在城市数量最多的20个城市

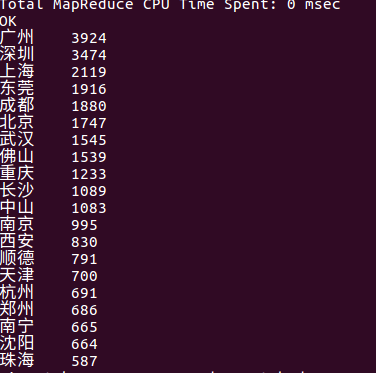
评分星级大于4的粉丝集中所在的排名前20的城市。


从数据我们可以看出,观众所在最多的20个城市都是属于比较经济发达的城市,基本都是一线,二线城市,他们在影视方面为贡献了一些GDP,同时从一些方面上可以体会为当地居民的生活恩格尔系数是不低的。
3.观众对影片的关注度
一部热门的影片在还没开始上映时就可以受到观众的关注,关注度的大小在一定程度上看出了观众对观看该影片的渴望度。
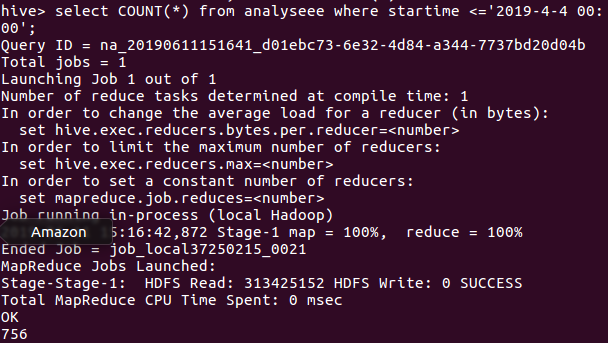
遇上统计了一下还没开始上映就有评论的数量,该影片的上映日期是2019-4-4,故我们可以看出在该日期之前的评论是756条,说明该片的关注度还是OK的。
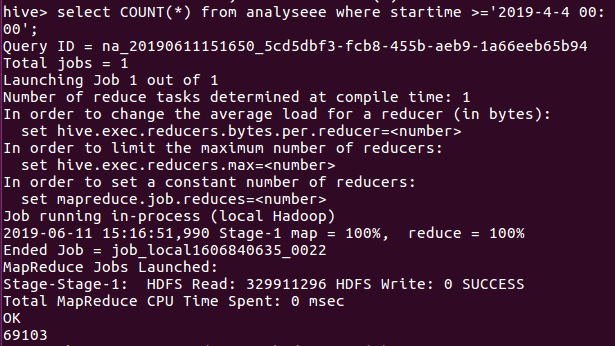
剩下的数量就是看完之后才会有的评论,69103条,说明该影片给观众多少留下一些印象。
4.观众观看时间分析
统计一下观众在某个时间片刻评论的数量多,证明着用户在评论时间的差不多时间就观看了电影,统计如下图所示:

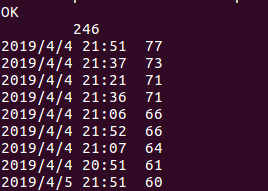
因此我们可以推断出观众在观看该影片大多时间都是在傍晚场至晚上场。
于是接着统计一下上映7天每天的数量,由于数据中的日期数据类型比较特殊,如果直接统计需要进行数据类型转化有点麻烦,故我各自统计了每天的数量
由图下的语句进行统计4月4日的数量,类推得到7天每天的数量。
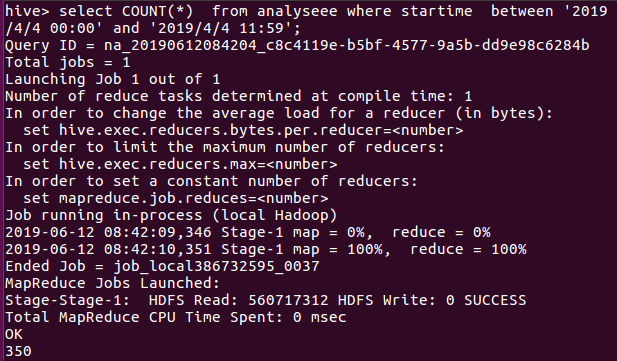
一直到4月11号,同样的语句就不放太多图了。。。
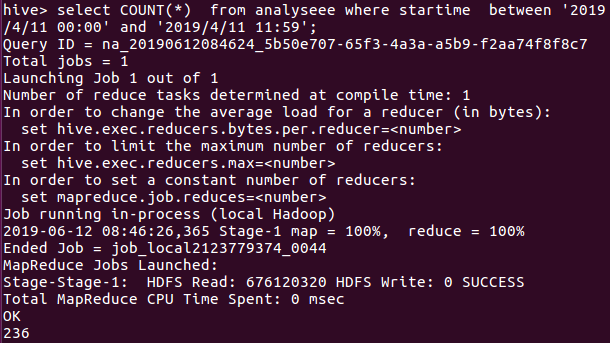
于是整理了一下,4月4日-4月11日的数量分别是350,699,949,714,485,342,275,236
从数据中可以看出6日的观众评论数是最多的,再弄一个折线波动图就更直观了。
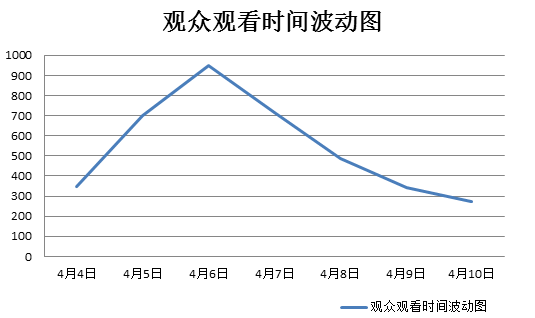
从图中我们很直观地看出了在影片在开播7日之内,6日的观看数(评论数)是最多的!
5.出现的问题解决:
1.在做这个过程中,数据在导入到hive时有分数列和时间列的数据出现NULL,如图所示:
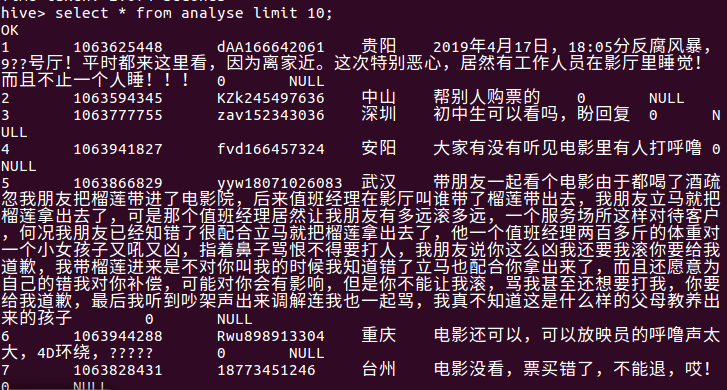
通过查找资料,解决方案为:重新建立表,然后把日期列和分数列的数据类型写成STRING就可以了,然后就会发现数据格式是正确的!
2.当我统计7天内的总数据量使用语句select * from analysee(表) where startime between ''2019/4/4 11:11‘ and '2019/4/10 11:11'时一直显示为0.
解决方案:由于我这里的数据格式为:2019/4/4 11:11,数据不是为date,故直接使用
故有两种解决方案,一:把日期列的数据进行格式化为’2019-1-2’,这样的话容易比较,就是有点复杂而已
二:简单思路多重复是记录每一天是数据量(我使用的是此方案,若数据天数太多则不建议)
三:在导入之前先用excel设计好自己想要的格式再重新上传到hdfs和hive中,结果会很方便
基于hive的《反贪风暴4》的影评的更多相关文章
- 基于 Hive 的文件格式:RCFile 简介及其应用
转载自:https://my.oschina.net/leejun2005/blog/280896 Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度 ...
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
- 基于hive的日志分析系统
转自 http://www.cppblog.com/koson/archive/2010/07/19/120773.html hive 简介 hive 是一个基于 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 转载:基于 Hive 的文件格式:RCFile 简介及其应用---推酷
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势.不过,MPP数据库社区也一直批评Hadoop由于文件格式并非为特定目的而建,因此序列化和反序 ...
- Arctic 基于 Hive 的流批一体实践
背景 随着大数据业务的发展,基于 Hive 的数仓体系逐渐难以满足日益增长的业务需求,一方面已有很大体量的用户,但是在实时性,功能性上严重缺失:另一方面 Hudi,Iceberg 这类系统在事务性,快 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Spark篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
随机推荐
- Charles关于Https SSLHandshake解决备忘录
抓包Https时错误提示:SSLHandshake: Received fatal alert: unknown_ca 1.准备工作,下载Charles版本 有情链接,提取码为:ghc6,其中包含 ...
- Flask 进阶
OOP 面向对象反射 # __call__方法 # class Foo(object): # def __call__(self, *args, **kwargs): # return "i ...
- Spring的核心机制:依赖注入
依赖注入的概念 当一个对象要调用另一个对象时,一般是new一个被调用的对象,示例: class A{ private B b=new B(); public void test(){ b.say ...
- 软工作业 wc-java
项目要求: 实现一个统计程序,它能正确统计程序文件中的字符数.单词数.行数,以及还具备其他扩展功能,并能够快速地处理多个文件. 具体功能 -c 返回文件字符数 -w 返回词的数目 -l 返回行数 扩展 ...
- selenium 滚动屏幕操作+上传文件
执行js脚本来滚动屏幕: (x,y)x为0 纵向滚动,y为0横向滚动 负数为向上滚动 driver.execute_script('window.scrollBy(0,250)') 上传文件: 1.导 ...
- MySQL修炼之路五
1. 存储引擎和锁 1. 存储引擎(处理表的处理器) 1. 基本操作 1. 查看所有存储引擎 mysql>show engines; 2. 查看已有表的存储引擎 mysql>show cr ...
- django模板和静态文件
1.为什么要使用模板 在上一篇博文中,提到了HttpReponse,但是HttpReponse只能传送字符串,如果要构建一个网页,那么工作量就会十分巨大.模板是一种方便的标签,存在于HTML文件中,我 ...
- cookie删除失效问题
在一个yii2的项目中使用了cookie,设置.获取都没有问题,但是在删除时候失败了. 要想删除cookie成功,只是设置cookie值为null,或设置时间为过期时间是不行的,还需要设置path,一 ...
- Yii2安装任务调度扩展
一.安装扩展 在安装之前添加仓库到composer.json文件中 "repositories": [{"type": "vcs", &qu ...
- js的insertRow和insertCell用法
js的insertRow(-1)和insertCell(-1) 增加最后一行和增加最后一列 js的insertRow(5)和insertCell(5) 第5行后增加一行和增加第5列后增加一列