Prometheus入门到放弃(6)之AlertManager进阶
前面几个篇幅,我们介绍了alertmanger报警配置,在实际运维过程中,我们都会遇到,报警的重复发送,以及报警信息关联性报警。接下来我们就介绍下通过alertmanger对告警信息的收敛。
一、告警分组(Grouping)
1.1 定义三个报警规则:
文中为了实验验证,告警值设置比较小,实际生产中,应该跟据业务的实际使用场景,来确定合理的告警值
[root@prometheus-server ~]# vim /etc/prometheus/rules/node_alerts.yml groups:
- name: node_alerts
rules:
- alert: InstanceDown
expr: up{job='node'} ==
for: 2m
labels:
severity: "critical"
env: dev
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
- alert: OSLoad
expr: node_load1 >
for: 2m
labels:
severity: "warning"
env: dev
annotations:
summary: "主机 {{ $labels.instance }} 负载大于 1"
description: "当前值: {{ $value }}"
- alert: HightCPU
expr: -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)* >
for: 2m
labels:
severity: "warning"
annotations:
summary: "主机 {{ $labels.instance }} of CPU 使用率大于10%!"
description: "当前值: {{ $value }}%"
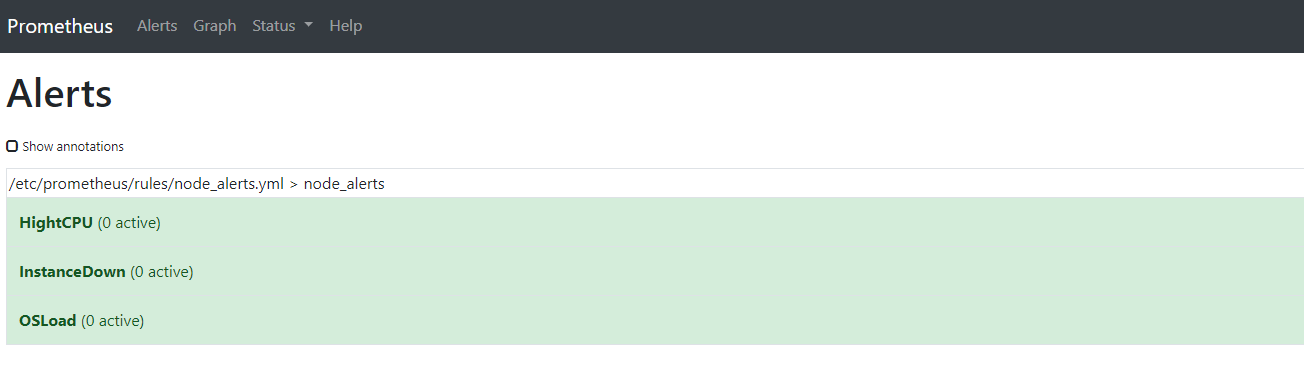
以上3个报警规则,node_alerts是监控node_exporter服务状态,OSLoad是监控系统负载,HightCPU是监控系统cpu使用率,前两个有标签env: dev,后面2个有标签 severity: "warning",重启Prometheus服务,可以看到监控规则已经加载
1.2 定义alertmanager报警组:
[root@prometheus-server ~]# vim /etc/alertmanager/alertmanager.yml
global:
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '****@163.com'
smtp_auth_username: '****@163.com'
smtp_auth_password: '****' ## 授权码
smtp_require_tls: false route:
group_by: ['env'] ### 以标签env分组,拥有labels为env的规则,如果在指定时间同时报警,报警信息会合并为一条进行发送
group_wait: 10s ### 组报警等待,等待该组中有没有其它报警
group_interval: 30s ### 组报警时间间隔
repeat_interval: 2m ### 重复报警时间,这个生产中跟据服务选择合适的时间
receiver: dev-mail ## 接收者 receivers:
- name: 'dev-mail' ## 对应上面的接收者
email_configs:
- to: '****@vanje.com.cn'
1.3 验证
我们停掉一台主机node_exporter(10.10.0.12)服务,用压测工具使某一台机器(10.10.0.11)负载大于1,cpu使用率(10.10.0.11)大于10,看下报警邮件是否会按我们定义组进行报警:
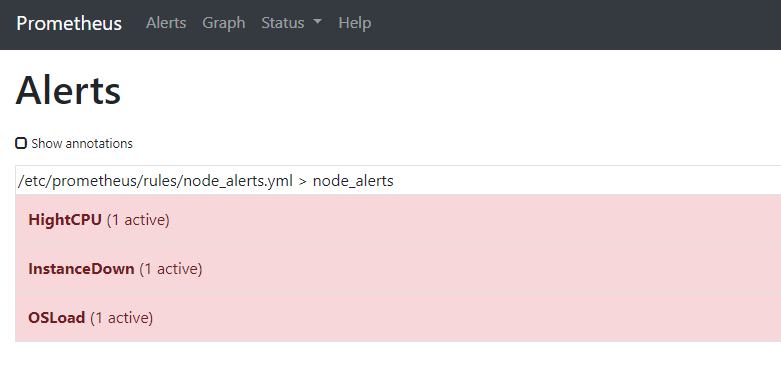
虽然我们同时触发了三个报警,但是跟据我们的定义,应该只会发两条报警信息,因为拥有env标签的报警规则,同时报警,会被合并为一条发送。
触发报警查看Prometheus ui界面上的alerts:

等2分钟后,如果检测到机器还是处于触发告警状态,Prometheus把会告警信息发送至alertmanager,然后跟据报警定义进行邮件报警:
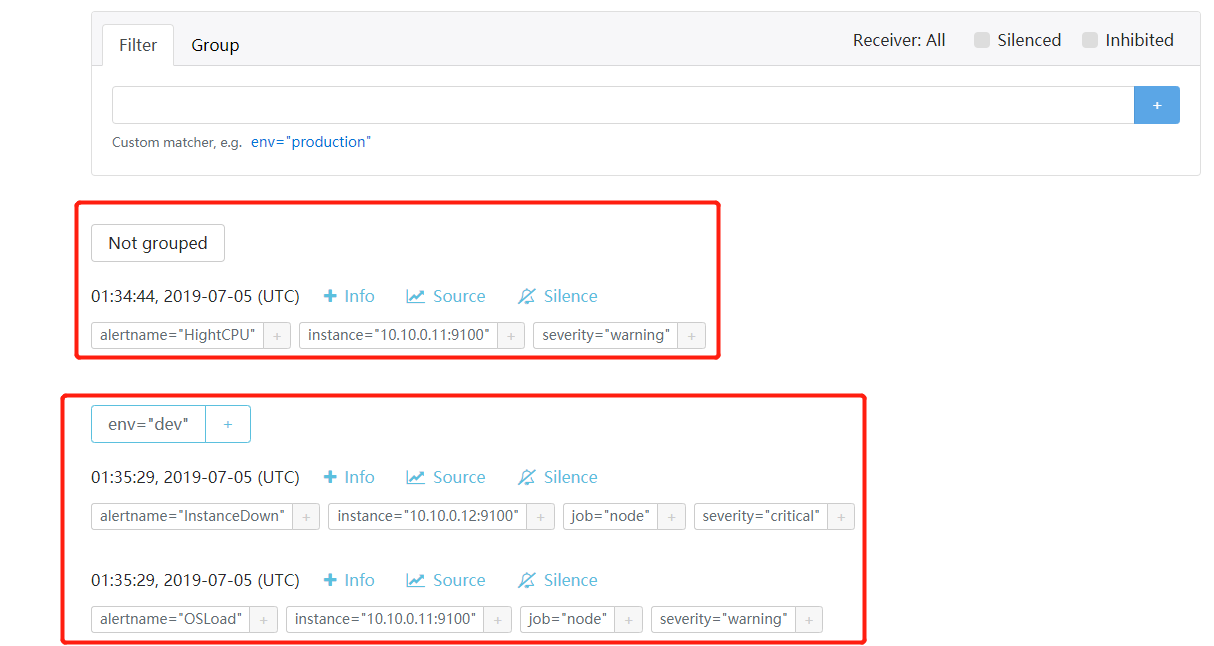
上图从alertmanager报警界面可以看到,报警信息已经按照分组合并,接下来我们看下邮箱中报警信息:
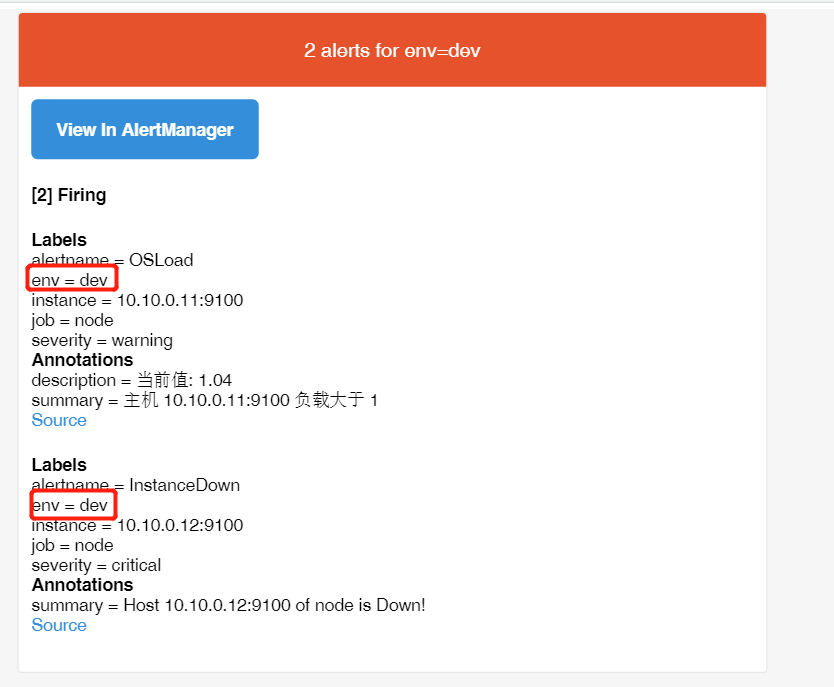
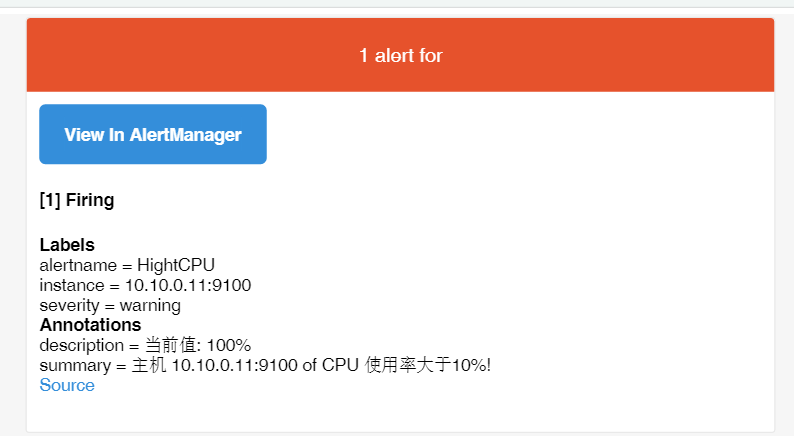
分组总结:
1、alertmanager跟据标签进行分组时,应该选择合适的标签,标签可以自定义,也可以使用默认的标签。
2、alertmanager报警分组,可以有效减少告警邮件数,但是仅是在同一个时间段报警,同一个组的告警信息才会合并发送。
二、告警抑制(Inhibition)
2.1 修改Prometheus 报警规则文件,为报警信息添加新标签area: A
[root@prometheus-server ~]# vim /etc/prometheus/rules/node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: InstanceDown
expr: up{job='node'} ==
for: 2m
labels:
severity: "critical"
env: dev
area: A
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
- alert: OSLoad
expr: node_load1 > 0.6
for: 2m
labels:
severity: "warning"
env: dev
area: A
annotations:
summary: "主机 {{ $labels.instance }} 负载大于 1"
description: "当前值: {{ $value }}"
- alert: HightCPU
expr: -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)* >
for: 2m
labels:
severity: "warning"
area: A
annotations:
summary: "主机 {{ $labels.instance }} of CPU 使用率大于10%!"
description: "当前值: {{ $value }}%"
2.2 修改alertmanager配置文件
[root@prometheus-server ~]# vim /etc/alertmanager/alertmanager.yml
## 新增以下配置
inhibit_rules:
- source_match: ## 源报警规则
severity: 'critical'
target_match: ## 抑制的报警规则
severity: 'warning'
equal: ['area'] ## 需要都有相同的标签及值,否则抑制不起作用
2.3 验证
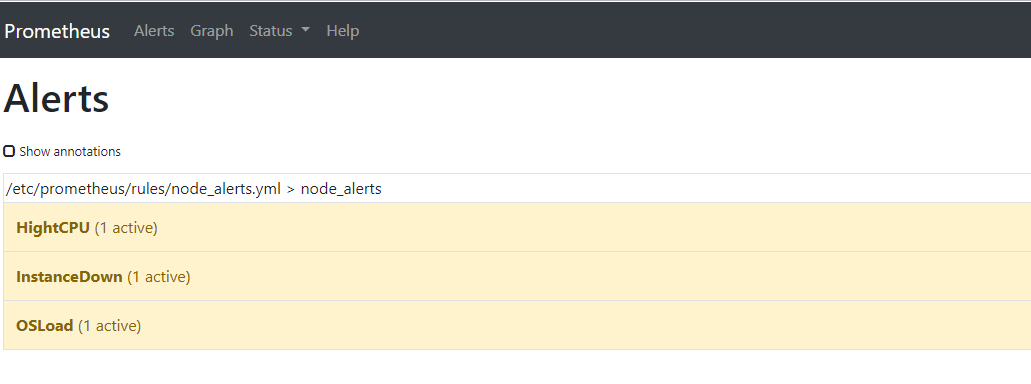
跟上面一样手动触发三个规则告警,跟据定义规则,应该只会收到一条报警信息:
查看Prometheus告警都已经触发,状态变为PENDING状态
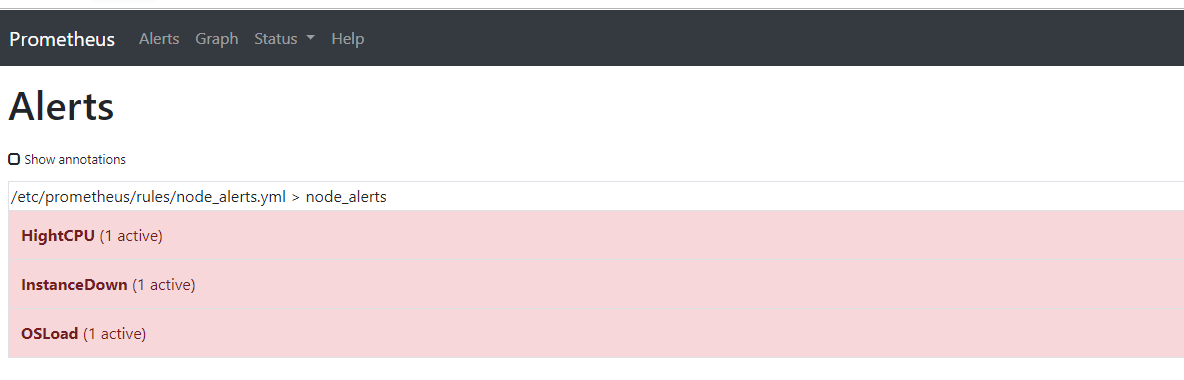
等待2分钟后, 三个告警状态由PENDING 变为 FIRING,同时prometheus会把告警信息发给alertmanager。
Alertmanager中我们只看到一条InstanceDown报警信息。

查看邮件中,也只收到InstanceDown的报警,另外2条报警已经被配置的抑制规则,把报警信息忽略掉。
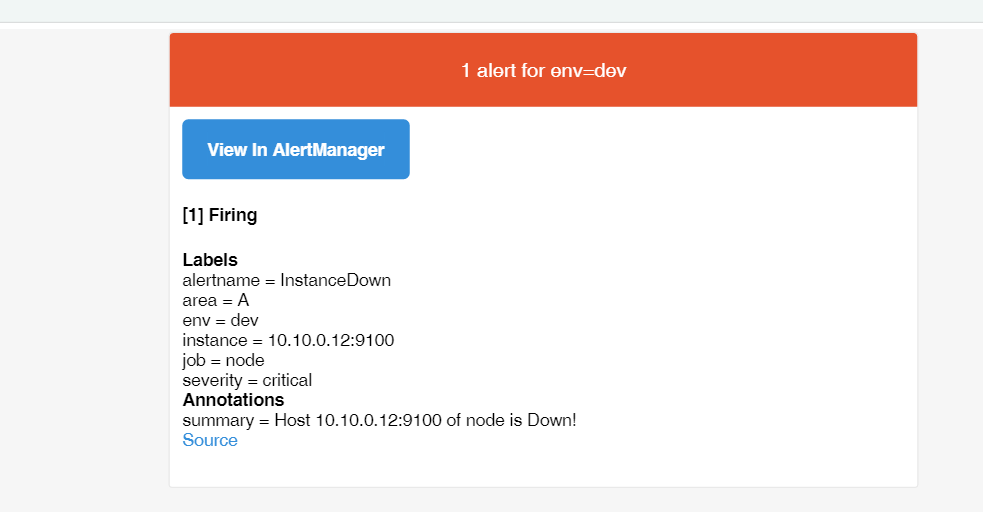
抑制总结:
1、抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。(比如网络不可达,服务器宕机等灾难性事件导致其他服务连接相关警报);
2、配置抑制规则,需要合理源规则及需要抑制的规则;
3、源规则与抑制规则需要具有相同的标签及标签值;
Prometheus入门到放弃(6)之AlertManager进阶的更多相关文章
- Prometheus入门到放弃(5)之AlertManager部署
alertmanager与exporters.cadvisor一样,都是独立于prometheus项目,这里我们也使用docker方式部署alertmanager. 1.下载镜像 镜像地址:https ...
- Prometheus入门到放弃(1)之Prometheus安装部署
规划: IP 角色 版本 10.10.0.13 prometheus-server 2.10 10.10.0.11 node_exporter 0.18.1 10.10.0.12 node_expor ...
- Prometheus入门到放弃(7)之redis_exporter部署
redis监控,prometheus需要使用redis_exporter客户端. 这里我们采用docker方式部署,既可以部署在redis所在服务器,也可以部署在其他机器: docker镜像地址:ht ...
- Prometheus入门到放弃(4)之cadvisor监控docker容器
Prometheus监控docker容器运行状态,我们用到cadvisor服务,cadvisor我们这里也采用docker方式直接运行. 1.下载镜像 [root@prometheus-server ...
- Prometheus入门到放弃(3)之Grafana展示监控数据
grafana我们这里采用docker方式部署 1.下载镜像 镜像官网地址:https://hub.docker.com/r/grafana/grafana/tags [root@prometheus ...
- Prometheus入门到放弃(2)之Node_export安装部署
1.下载安装 node_exporter服务需要在三台机器都安装,这里我们以一台机器为例: 地址:https://prometheus.io/download/ ### 另外两个节点部署时,需要先创建 ...
- K8S从入门到放弃系列-(16)Kubernetes集群Prometheus-operator监控部署
Prometheus Operator不同于Prometheus,Prometheus Operator是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控 ...
- [精品书单] C#/.NET 学习之路——从入门到放弃
C#/.NET 学习之路--从入门到放弃 此系列只包含 C#/CLR 学习,不包含应用框架(ASP.NET , WPF , WCF 等)及架构设计学习书籍和资料. C# 入门 <C# 本质论&g ...
- FQ:从入门到放弃(二)
上次的FQ:从入门到放弃(一)介绍了XXNet的部署和基本使用.本文整理一些部署过程中出现的问题,都是这几天朋友们安装过程中出现的问题.如果覆盖不全,欢迎在博客下方评论,互相交流,互相学习. 不过首先 ...
随机推荐
- LeetCode 842. Split Array into Fibonacci Sequence
原题链接在这里:https://leetcode.com/problems/split-array-into-fibonacci-sequence/ 题目: Given a string S of d ...
- 洛谷 P2949 [USACO09OPEN]工作调度Work Scheduling 题解
P2949 [USACO09OPEN]工作调度Work Scheduling 题目描述 Farmer John has so very many jobs to do! In order to run ...
- python实现:判断某一天是那一年中的第几天
方法1:先判断是否是闰年,然后再利用求和,得出某一天是第几天 # 方法1:low版 def func1(year, month, day): # 分别创建平年,闰年的月份天数列表(注意列表下标从0开始 ...
- 【2019.11.18】SDN阅读作业
为什么需要SDN?SDN特点? 随着网络的快速发展,传统互联网出现了如传统网络配置复杂度高等诸多问题,这些问题说明网络架构需要革新,可编程网络的相关研究为 SDN 的产生提供了可参考的理论依据 SDN ...
- 在js中添加HTML类样式
有时候需要给元素添加类样式,但又要保留之前的类,可以使用element.classList.add("类名");
- [Beta]第九次 Scrum Meeting
[Beta]第九次 Scrum Meeting 写在前面 会议时间 会议时长 会议地点 2019/5/19 21:20 20min 大运村公寓6F寝室 附Github仓库:WEDO 例会照片 (一人回 ...
- 回顾idea快捷键
F9 resume programe 恢复程序 Alt+F10 show execution point 显示执行断点 F8 Step Over ...
- tar_ssh 配合下载文件(适合于带宽充足传输大量小文件场景)
局域网网速快,但是当要传输大量小文件时倘若仍然使用scp,由于每个文件传输完毕都需要独立进行传输完毕的确认,这样就无法充分利用带宽.一方面等待确认时tcp窗口无法填满,另一方面文件传完之前确认也不会开 ...
- Springboot属性加载与覆盖优先级与SpringCloud Config Service配置
参考官方文档:https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-external-config. ...
- 子页面赋值给父页面:window.opener.document.getElementById
window.opener 返回的是创建当前窗口的那个父窗口的引用,比如点击了a.htm上的一个链接而打开了b.htm,然后我们打算在b.htm上输入一个值然后赋予a.htm上的一个id为“name” ...